 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImbalance in Regression Datasets
Feb 19, 2024



For classification, the problem of class imbalance is well known and has been extensively studied. In this paper, we argue that imbalance in regression is an equally important problem which has so far been overlooked: Due to under- and over-representations in a data set's target distribution, regressors are prone to degenerate to naive models, systematically neglecting uncommon training data and over-representing targets seen often during training. We analyse this problem theoretically and use resulting insights to develop a first definition of imbalance in regression, which we show to be a generalisation of the commonly employed imbalance measure in classification. With this, we hope to turn the spotlight on the overlooked problem of imbalance in regression and to provide common ground for future research.
Data Poisoning Attacks on Regression Learning and Corresponding Defenses
Sep 15, 2020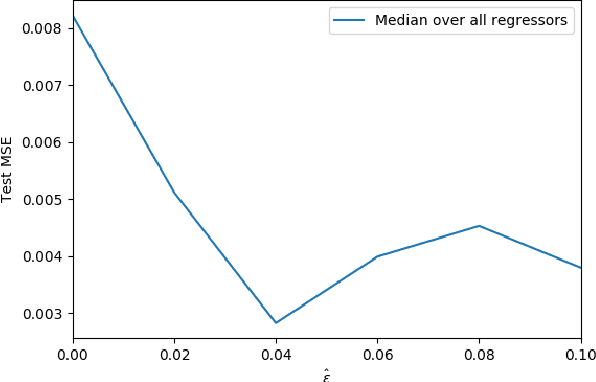
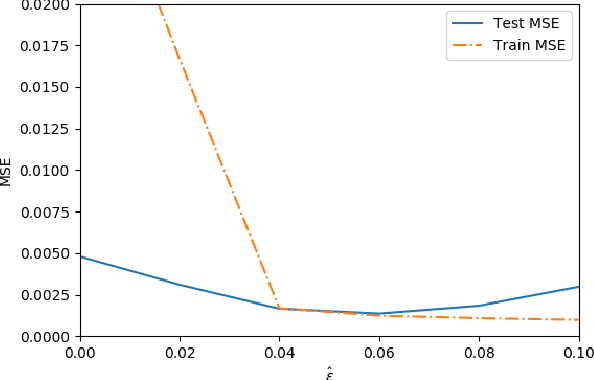

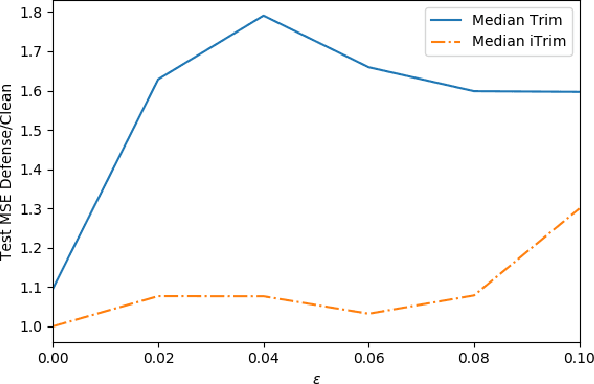
Adversarial data poisoning is an effective attack against machine learning and threatens model integrity by introducing poisoned data into the training dataset. So far, it has been studied mostly for classification, even though regression learning is used in many mission critical systems (such as dosage of medication, control of cyber-physical systems and managing power supply). Therefore, in the present research, we aim to evaluate all aspects of data poisoning attacks on regression learning, exceeding previous work both in terms of breadth and depth. We present realistic scenarios in which data poisoning attacks threaten production systems and introduce a novel black-box attack, which is then applied to a real-word medical use-case. As a result, we observe that the mean squared error (MSE) of the regressor increases to 150 percent due to inserting only two percent of poison samples. Finally, we present a new defense strategy against the novel and previous attacks and evaluate it thoroughly on 26 datasets. As a result of the conducted experiments, we conclude that the proposed defence strategy effectively mitigates the considered attacks.