 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Dependencies in Adversarial Attacks on Speech Recognition Systems
Feb 02, 2022



Automatic speech recognition (ASR) systems are ubiquitously present in our daily devices. They are vulnerable to adversarial attacks, where manipulated input samples fool the ASR system's recognition. While adversarial examples for various English ASR systems have already been analyzed, there exists no inter-language comparative vulnerability analysis. We compare the attackability of a German and an English ASR system, taking Deepspeech as an example. We investigate if one of the language models is more susceptible to manipulations than the other. The results of our experiments suggest statistically significant differences between English and German in terms of computational effort necessary for the successful generation of adversarial examples. This result encourages further research in language-dependent characteristics in the robustness analysis of ASR.
Visualizing Automatic Speech Recognition -- Means for a Better Understanding?
Feb 01, 2022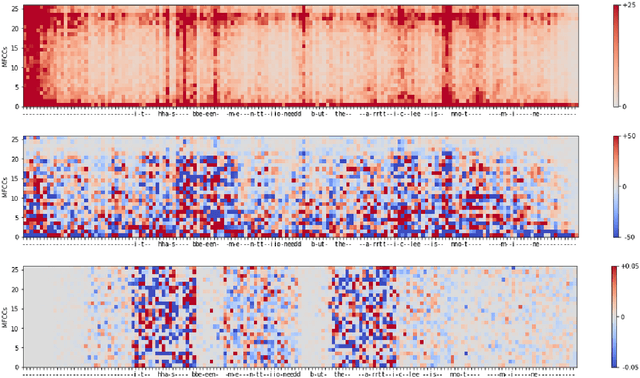
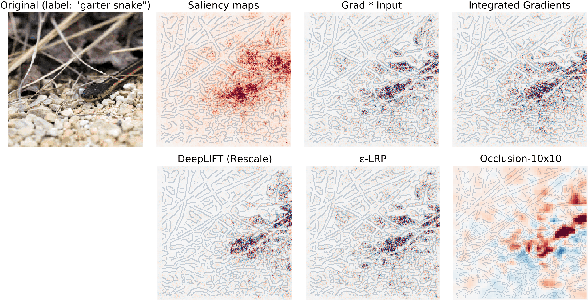
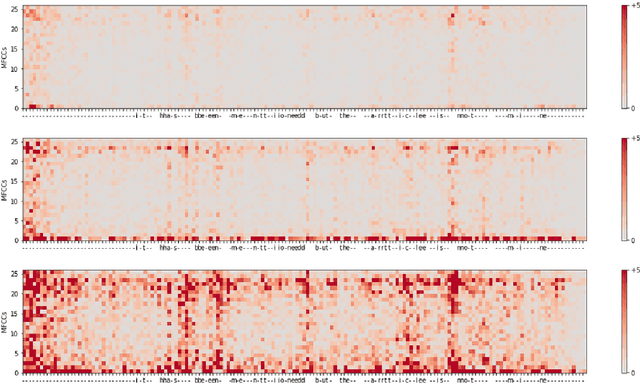
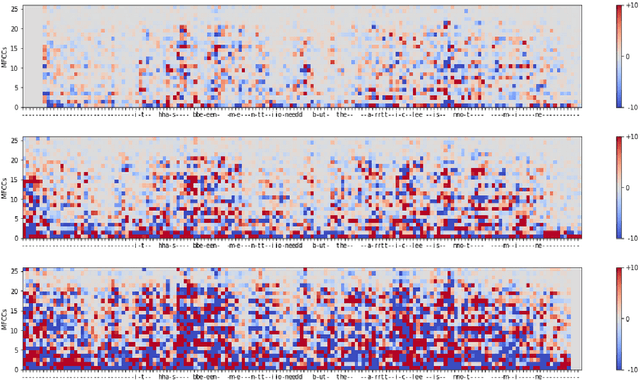
Automatic speech recognition (ASR) is improving ever more at mimicking human speech processing. The functioning of ASR, however, remains to a large extent obfuscated by the complex structure of the deep neural networks (DNNs) they are based on. In this paper, we show how so-called attribution methods, that we import from image recognition and suitably adapt to handle audio data, can help to clarify the working of ASR. Taking DeepSpeech, an end-to-end model for ASR, as a case study, we show how these techniques help to visualize which features of the input are the most influential in determining the output. We focus on three visualization techniques: Layer-wise Relevance Propagation (LRP), Saliency Maps, and Shapley Additive Explanations (SHAP). We compare these methods and discuss potential further applications, such as in the detection of adversarial examples.
Human Perception of Audio Deepfakes
Jul 20, 2021


The recent emergence of deepfakes, computerized realistic multimedia fakes, brought the detection of manipulated and generated content to the forefront. While many machine learning models for deepfakes detection have been proposed, the human detection capabilities have remained far less explored. This is of special importance as human perception differs from machine perception and deepfakes are generally designed to fool the human. So far, this issue has only been addressed in the area of images and video. To compare the ability of humans and machines in detecting audio deepfakes, we conducted an online gamified experiment in which we asked users to discern bonda-fide audio samples from spoofed audio, generated with a variety of algorithms. 200 users competed for 8976 game rounds with an artificial intelligence (AI) algorithm trained for audio deepfake detection. With the collected data we found that the machine generally outperforms the humans in detecting audio deepfakes, but that the converse holds for a certain attack type, for which humans are still more accurate. Furthermore, we found that younger participants are on average better at detecting audio deepfakes than older participants, while IT-professionals hold no advantage over laymen. We conclude that it is important to combine human and machine knowledge in order to improve audio deepfake detection.
Towards Resistant Audio Adversarial Examples
Oct 14, 2020



Adversarial examples tremendously threaten the availability and integrity of machine learning-based systems. While the feasibility of such attacks has been observed first in the domain of image processing, recent research shows that speech recognition is also susceptible to adversarial attacks. However, reliably bridging the air gap (i.e., making the adversarial examples work when recorded via a microphone) has so far eluded researchers. We find that due to flaws in the generation process, state-of-the-art adversarial example generation methods cause overfitting because of the binning operation in the target speech recognition system (e.g., Mozilla Deepspeech). We devise an approach to mitigate this flaw and find that our method improves generation of adversarial examples with varying offsets. We confirm the significant improvement with our approach by empirical comparison of the edit distance in a realistic over-the-air setting. Our approach states a significant step towards over-the-air attacks. We publish the code and an applicable implementation of our approach.
Identifying Mislabeled Instances in Classification Datasets
Dec 11, 2019
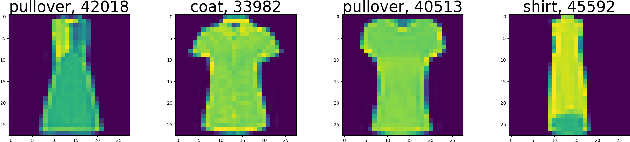
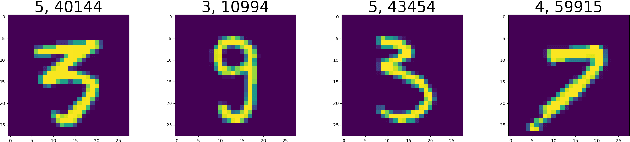
A key requirement for supervised machine learning is labeled training data, which is created by annotating unlabeled data with the appropriate class. Because this process can in many cases not be done by machines, labeling needs to be performed by human domain experts. This process tends to be expensive both in time and money, and is prone to errors. Additionally, reviewing an entire labeled dataset manually is often prohibitively costly, so many real world datasets contain mislabeled instances. To address this issue, we present in this paper a non-parametric end-to-end pipeline to find mislabeled instances in numerical, image and natural language datasets. We evaluate our system quantitatively by adding a small number of label noise to 29 datasets, and show that we find mislabeled instances with an average precision of more than 0.84 when reviewing our system's top 1\% recommendation. We then apply our system to publicly available datasets and find mislabeled instances in CIFAR-100, Fashion-MNIST, and others. Finally, we publish the code and an applicable implementation of our approach.