 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualizing Automatic Speech Recognition -- Means for a Better Understanding?
Feb 01, 2022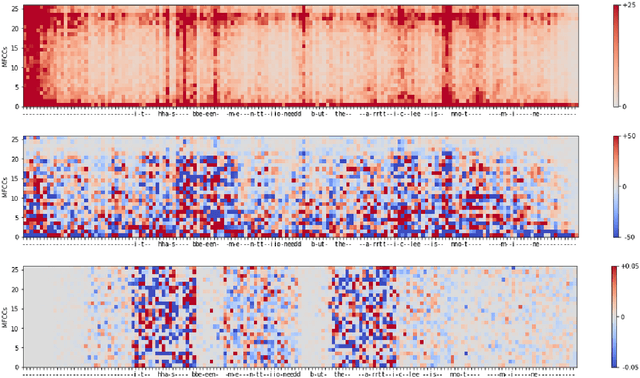
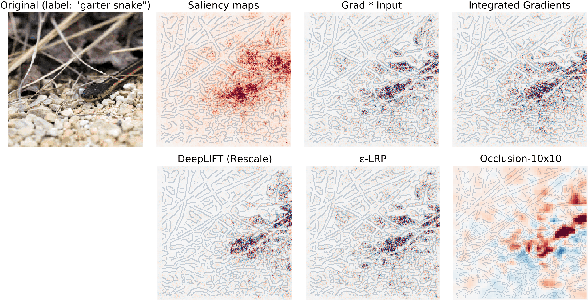
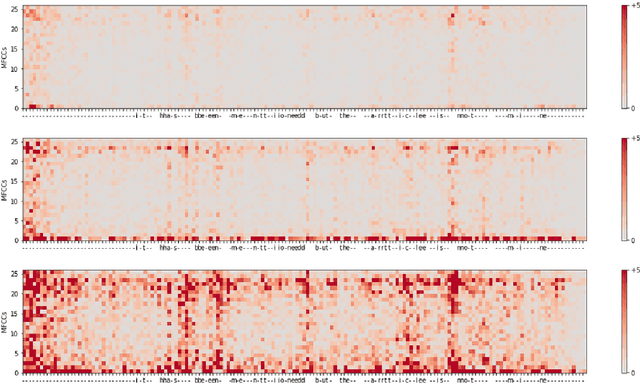
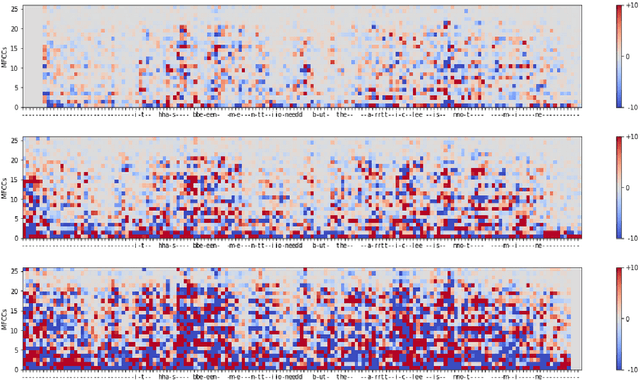
Automatic speech recognition (ASR) is improving ever more at mimicking human speech processing. The functioning of ASR, however, remains to a large extent obfuscated by the complex structure of the deep neural networks (DNNs) they are based on. In this paper, we show how so-called attribution methods, that we import from image recognition and suitably adapt to handle audio data, can help to clarify the working of ASR. Taking DeepSpeech, an end-to-end model for ASR, as a case study, we show how these techniques help to visualize which features of the input are the most influential in determining the output. We focus on three visualization techniques: Layer-wise Relevance Propagation (LRP), Saliency Maps, and Shapley Additive Explanations (SHAP). We compare these methods and discuss potential further applications, such as in the detection of adversarial examples.