 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Image Registration using Mutual Attention based Network
Jun 04, 2022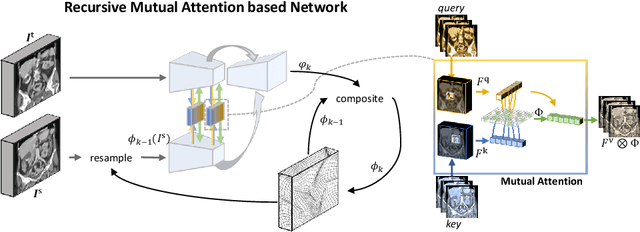
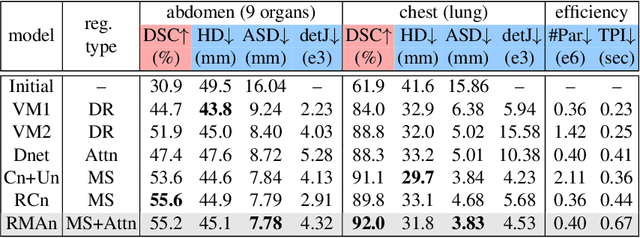
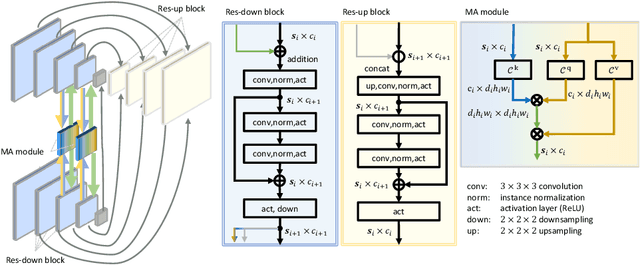
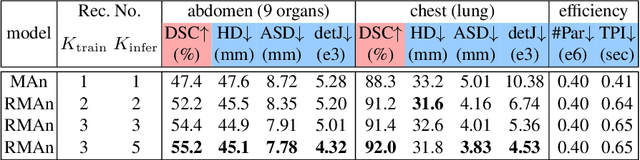
Image registration is an important task in medical imaging which estimates the spatial transformation between different images. Many previous studies have used learning-based methods for multi-stage registration to perform 3D image registration to improve performance. The performance of the multi-stage approach, however, is limited by the size of the receptive field where complex motion does not occur at a single spatial scale. We propose a new registration network combining recursive network architecture and mutual attention mechanism to overcome these limitations. Compared with the previous deep learning methods, our network based on the recursive structure achieves the highest accuracy in lung Computed Tomography (CT) data set (Dice score of 92\% and average surface distance of 3.8mm for lungs) and one of the most accurate results in abdominal CT data set with 9 organs of various sizes (Dice score of 55\% and average surface distance of 7.8mm). We also showed that adding 3 recursive networks is sufficient to achieve the state-of-the-art results without a significant increase in the inference time.
Residual Aligner Network
Mar 07, 2022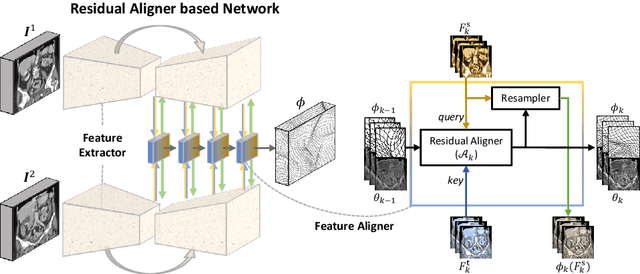
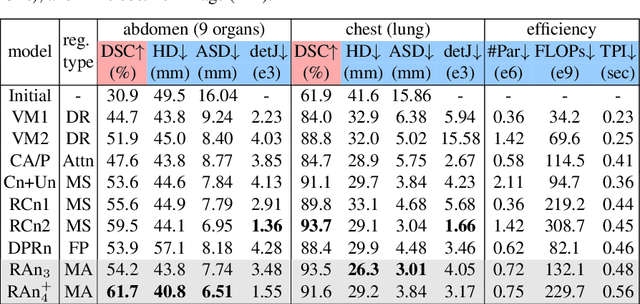
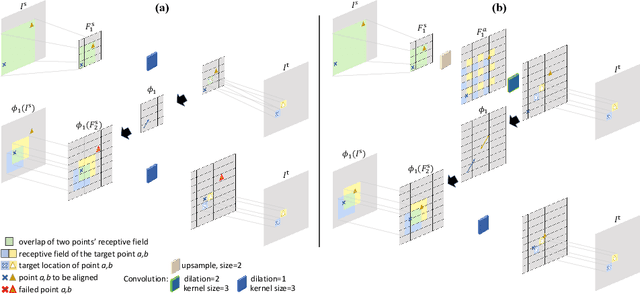
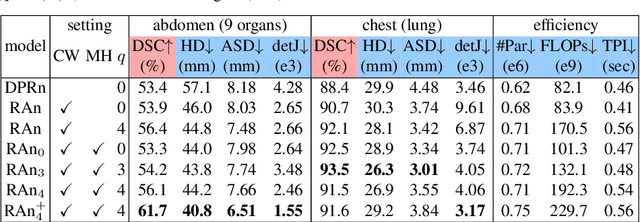
Image registration is important for medical imaging, the estimation of the spatial transformation between different images. Many previous studies have used learning-based methods for coarse-to-fine registration to efficiently perform 3D image registration. The coarse-to-fine approach, however, is limited when dealing with the different motions of nearby objects. Here we propose a novel Motion-Aware (MA) structure that captures the different motions in a region. The MA structure incorporates a novel Residual Aligner (RA) module which predicts the multi-head displacement field used to disentangle the different motions of multiple neighbouring objects. Compared with other deep learning methods, the network based on the MA structure and RA module achieve one of the most accurate unsupervised inter-subject registration on the 9 organs of assorted sizes in abdominal CT scans, with the highest-ranked registration of the veins (Dice Similarity Coefficient / Average surface distance: 62\%/4.9mm for the vena cava and 34\%/7.9mm for the portal and splenic vein), with a half-sized structure and more efficient computation. Applied to the segmentation of lungs in chest CT scans, the new network achieves results which were indistinguishable from the best-ranked networks (94\%/3.0mm). Additionally, the theorem on predicted motion pattern and the design of MA structure are validated by further analysis.
D-Net: Siamese based Network with Mutual Attention for Volume Alignment
Jan 25, 2021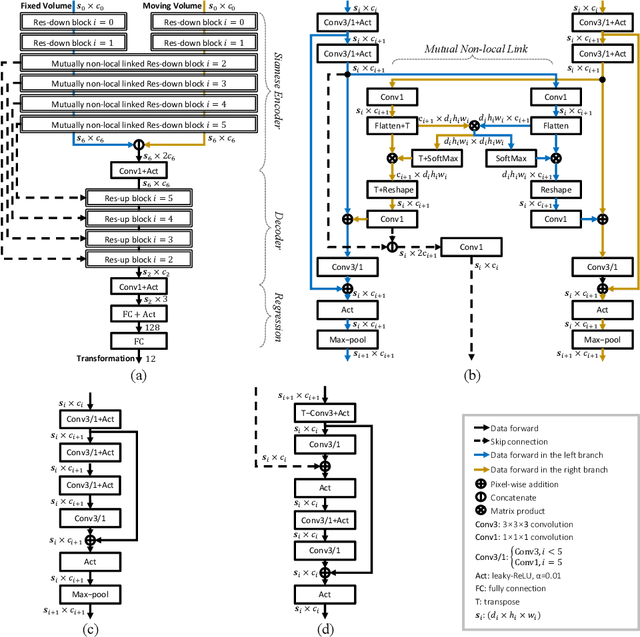
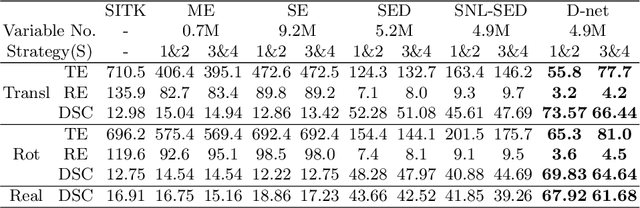


Alignment of contrast and non-contrast-enhanced imaging is essential for the quantification of changes in several biomedical applications. In particular, the extraction of cartilage shape from contrast-enhanced Computed Tomography (CT) of tibiae requires accurate alignment of the bone, currently performed manually. Existing deep learning-based methods for alignment require a common template or are limited in rotation range. Therefore, we present a novel network, D-net, to estimate arbitrary rotation and translation between 3D CT scans that additionally does not require a prior standard template. D-net is an extension to the branched Siamese encoder-decoder structure connected by new mutual non-local links, which efficiently capture long-range connections of similar features between two branches. The 3D supervised network is trained and validated using preclinical CT scans of mouse tibiae with and without contrast enhancement in cartilage. The presented results show a significant improvement in the estimation of CT alignment, outperforming the current comparable methods.
* this uploaded manuscript is another version of which published in: International Workshop on Shape in Medical Imaging, Springer, 2020, pp. 73-84