 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD-Net: Siamese based Network with Mutual Attention for Volume Alignment
Paper and Code
Jan 25, 2021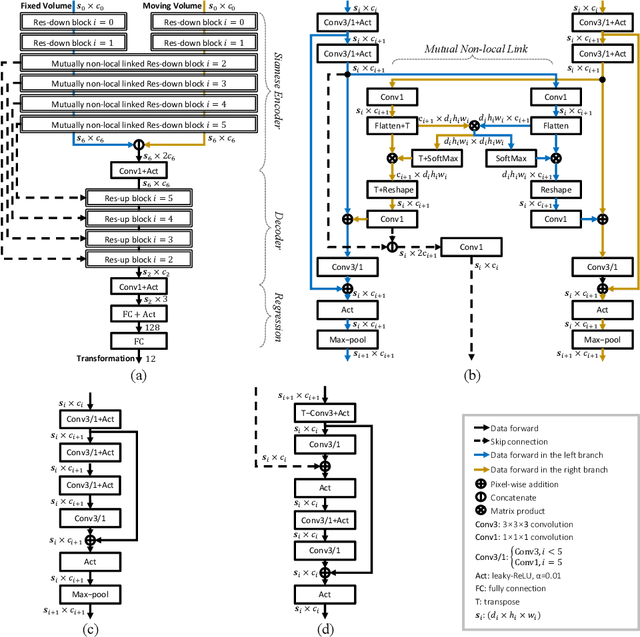
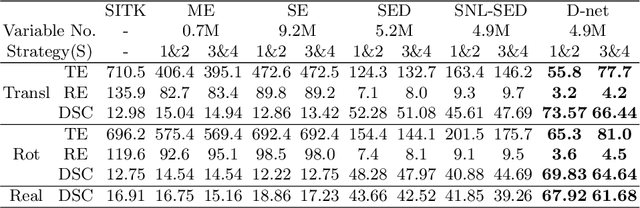


Alignment of contrast and non-contrast-enhanced imaging is essential for the quantification of changes in several biomedical applications. In particular, the extraction of cartilage shape from contrast-enhanced Computed Tomography (CT) of tibiae requires accurate alignment of the bone, currently performed manually. Existing deep learning-based methods for alignment require a common template or are limited in rotation range. Therefore, we present a novel network, D-net, to estimate arbitrary rotation and translation between 3D CT scans that additionally does not require a prior standard template. D-net is an extension to the branched Siamese encoder-decoder structure connected by new mutual non-local links, which efficiently capture long-range connections of similar features between two branches. The 3D supervised network is trained and validated using preclinical CT scans of mouse tibiae with and without contrast enhancement in cartilage. The presented results show a significant improvement in the estimation of CT alignment, outperforming the current comparable methods.