 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review of Literature on Parallel Constraint Solving
Mar 29, 2018As multicore computing is now standard, it seems irresponsible for constraints researchers to ignore the implications of it. Researchers need to address a number of issues to exploit parallelism, such as: investigating which constraint algorithms are amenable to parallelisation; whether to use shared memory or distributed computation; whether to use static or dynamic decomposition; and how to best exploit portfolios and cooperating search. We review the literature, and see that we can sometimes do quite well, some of the time, on some instances, but we are far from a general solution. Yet there seems to be little overall guidance that can be given on how best to exploit multicore computers to speed up constraint solving. We hope at least that this survey will provide useful pointers to future researchers wishing to correct this situation. Under consideration in Theory and Practice of Logic Programming (TPLP).
The Ultrametric Constraint and its Application to Phylogenetics
Jan 15, 2014

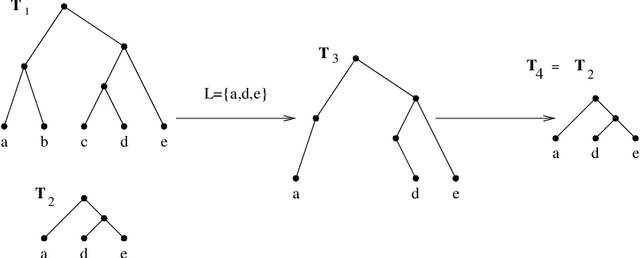

A phylogenetic tree shows the evolutionary relationships among species. Internal nodes of the tree represent speciation events and leaf nodes correspond to species. A goal of phylogenetics is to combine such trees into larger trees, called supertrees, whilst respecting the relationships in the original trees. A rooted tree exhibits an ultrametric property; that is, for any three leaves of the tree it must be that one pair has a deeper most recent common ancestor than the other pairs, or that all three have the same most recent common ancestor. This inspires a constraint programming encoding for rooted trees. We present an efficient constraint that enforces the ultrametric property over a symmetric array of constrained integer variables, with the inevitable property that the lower bounds of any three variables are mutually supportive. We show that this allows an efficient constraint-based solution to the supertree construction problem. We demonstrate that the versatility of constraint programming can be exploited to allow solutions to variants of the supertree construction problem.
Distributed solving through model splitting
Aug 25, 2010
Constraint problems can be trivially solved in parallel by exploring different branches of the search tree concurrently. Previous approaches have focused on implementing this functionality in the solver, more or less transparently to the user. We propose a new approach, which modifies the constraint model of the problem. An existing model is split into new models with added constraints that partition the search space. Optionally, additional constraints are imposed that rule out the search already done. The advantages of our approach are that it can be implemented easily, computations can be stopped and restarted, moved to different machines and indeed solved on machines which are not able to communicate with each other at all.