 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAPNet: Continuous Approximation Projection For 3D Point Cloud Reconstruction Using 2D Supervision
Nov 28, 2018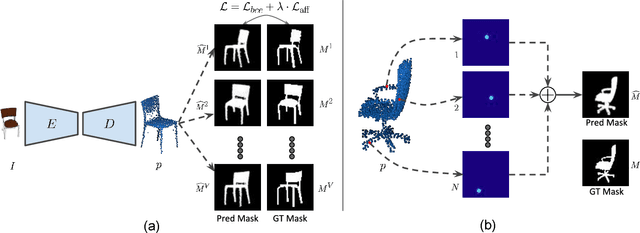


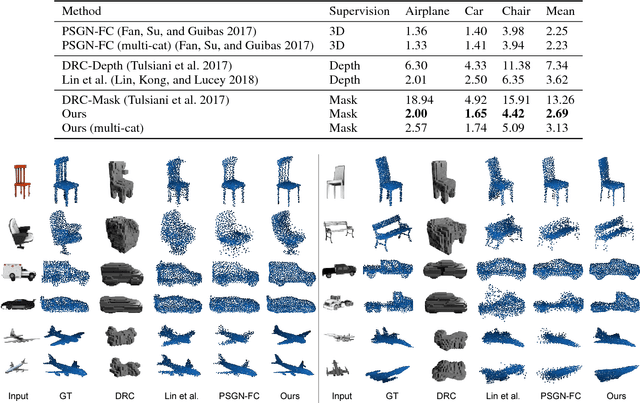
Knowledge of 3D properties of objects is a necessity in order to build effective computer vision systems. However, lack of large scale 3D datasets can be a major constraint for data-driven approaches in learning such properties. We consider the task of single image 3D point cloud reconstruction, and aim to utilize multiple foreground masks as our supervisory data to alleviate the need for large scale 3D datasets. A novel differentiable projection module, called 'CAPNet', is introduced to obtain such 2D masks from a predicted 3D point cloud. The key idea is to model the projections as a continuous approximation of the points in the point cloud. To overcome the challenges of sparse projection maps, we propose a loss formulation termed 'affinity loss' to generate outlier-free reconstructions. We significantly outperform the existing projection based approaches on a large-scale synthetic dataset. We show the utility and generalizability of such a 2D supervised approach through experiments on a real-world dataset, where lack of 3D data can be a serious concern. To further enhance the reconstructions, we also propose a test stage optimization procedure to obtain reconstructions that display high correspondence with the observed input image.
Operator-In-The-Loop Deep Sequential Multi-camera Feature Fusion for Person Re-identification
Nov 06, 2018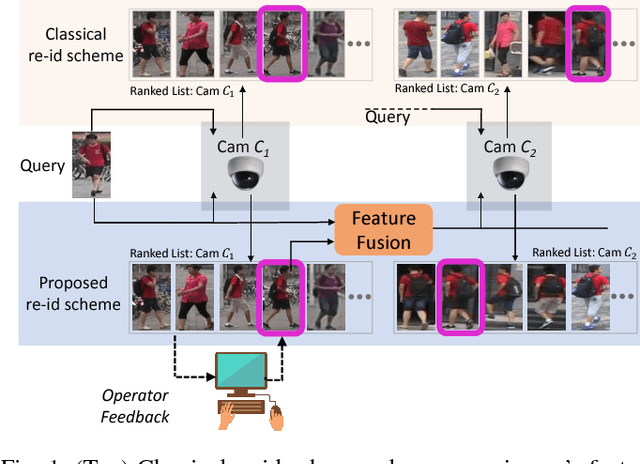

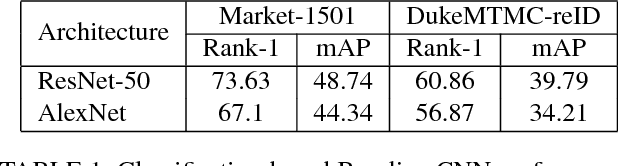
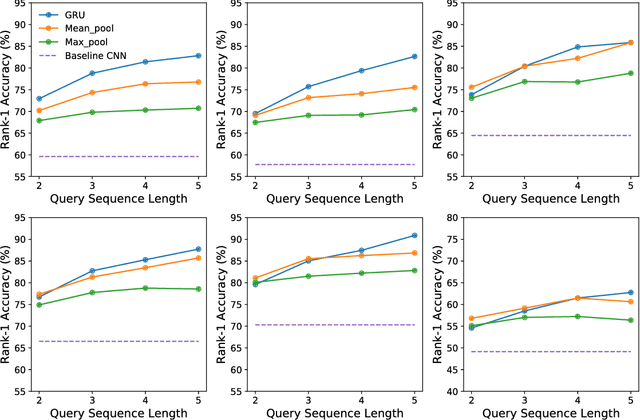
Given a target image as query, person re-identification systems retrieve a ranked list of candidate matches on a per-camera basis. In deployed systems, a human operator scans these lists and labels sighted targets by touch or mouse-based selection. However, classical re-id approaches generate per-camera lists independently. Therefore, target identifications by operator in a subset of cameras cannot be utilized to improve ranking of the target in remaining set of network cameras. To address this shortcoming, we propose a novel sequential multi-camera re-id approach. The proposed approach can accommodate human operator inputs and provides early gains via a monotonic improvement in target ranking. At the heart of our approach is a fusion function which operates on deep feature representations of query and candidate matches. We formulate an optimization procedure custom-designed to incrementally improve query representation. Since existing evaluation methods cannot be directly adopted to our setting, we also propose two novel evaluation protocols. The results on two large-scale re-id datasets (Market-1501, DukeMTMC-reID) demonstrate that our multi-camera method significantly outperforms baselines and other popular feature fusion schemes. Additionally, we conduct a comparative subject-based study of human operator performance. The superior operator performance enabled by our approach makes a compelling case for its integration into deployable video-surveillance systems.
3D-PSRNet: Part Segmented 3D Point Cloud Reconstruction From a Single Image
Sep 30, 2018
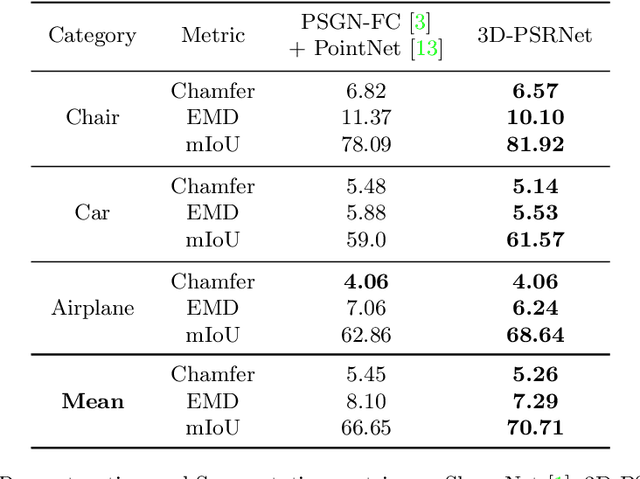
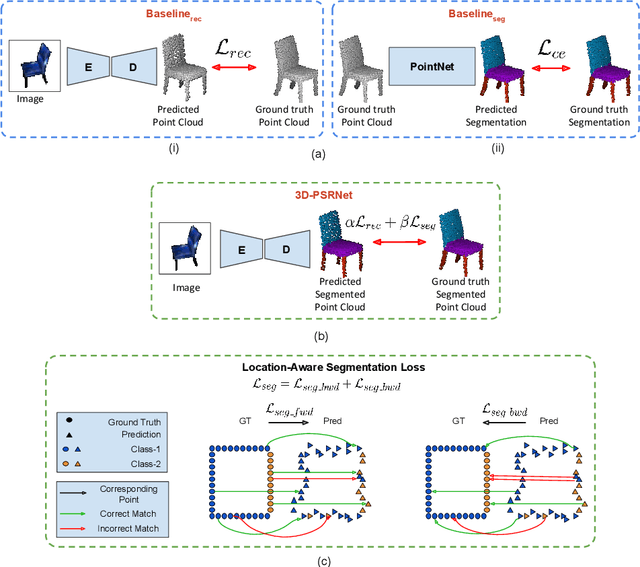
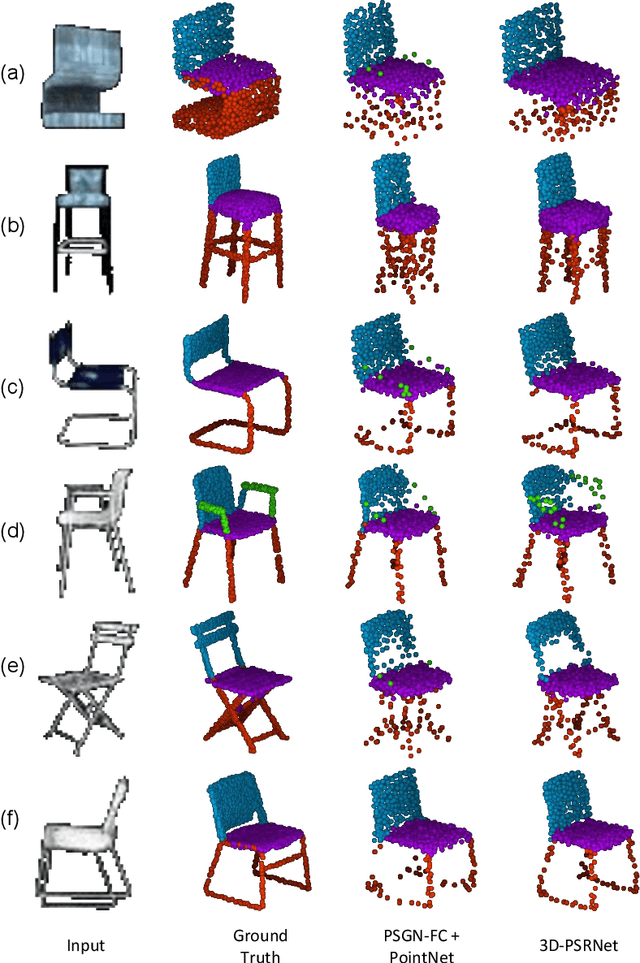
We propose a mechanism to reconstruct part annotated 3D point clouds of objects given just a single input image. We demonstrate that jointly training for both reconstruction and segmentation leads to improved performance in both the tasks, when compared to training for each task individually. The key idea is to propagate information from each task so as to aid the other during the training procedure. Towards this end, we introduce a location-aware segmentation loss in the training regime. We empirically show the effectiveness of the proposed loss in generating more faithful part reconstructions while also improving segmentation accuracy. We thoroughly evaluate the proposed approach on different object categories from the ShapeNet dataset to obtain improved results in reconstruction as well as segmentation.