 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study of Retrieval Methods in Azure AI Search
Dec 08, 2025Increasingly, attorneys are interested in moving beyond keyword and semantic search to improve the efficiency of how they find key information during a document review task. Large language models (LLMs) are now seen as tools that attorneys can use to ask natural language questions of their data during document review to receive accurate and concise answers. This study evaluates retrieval strategies within Microsoft Azure's Retrieval-Augmented Generation (RAG) framework to identify effective approaches for Early Case Assessment (ECA) in eDiscovery. During ECA, legal teams analyze data at the outset of a matter to gain a general understanding of the data and attempt to determine key facts and risks before beginning full-scale review. In this paper, we compare the performance of Azure AI Search's keyword, semantic, vector, hybrid, and hybrid-semantic retrieval methods. We then present the accuracy, relevance, and consistency of each method's AI-generated responses. Legal practitioners can use the results of this study to enhance how they select RAG configurations in the future.
Exploiting the Randomness of Large Language Models (LLM) in Text Classification Tasks: Locating Privileged Documents in Legal Matters
Dec 08, 2025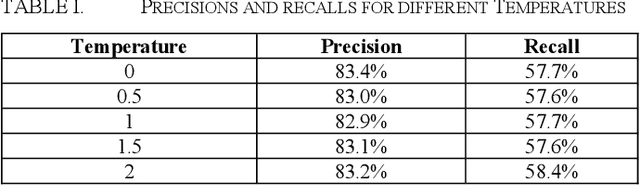

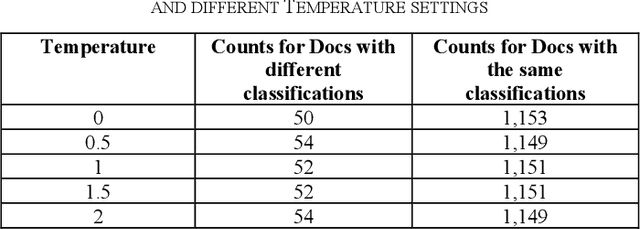

In legal matters, text classification models are most often used to filter through large datasets in search of documents that meet certain pre-selected criteria like relevance to a certain subject matter, such as legally privileged communications and attorney-directed documents. In this context, large language models have demonstrated strong performance. This paper presents an empirical study investigating the role of randomness in LLM-based classification for attorney-client privileged document detection, focusing on four key dimensions: (1) the effectiveness of LLMs in identifying legally privileged documents, (2) the influence of randomness control parameters on classification outputs, (3) their impact on overall classification performance, and (4) a methodology for leveraging randomness to enhance accuracy. Experimental results showed that LLMs can identify privileged documents effectively, randomness control parameters have minimal impact on classification performance, and importantly, our developed methodology for leveraging randomness can have a significant impact on improving accuracy. Notably, this methodology that leverages randomness could also enhance a corporation's confidence in an LLM's output when incorporated into its sanctions-compliance processes. As organizations increasingly rely on LLMs to augment compliance workflows, reducing output variability helps build internal and regulatory confidence in LLM-derived sanctions-screening decisions.
Leveraging Machine Learning and Large Language Models for Automated Image Clustering and Description in Legal Discovery
Dec 08, 2025The rapid increase in digital image creation and retention presents substantial challenges during legal discovery, digital archive, and content management. Corporations and legal teams must organize, analyze, and extract meaningful insights from large image collections under strict time pressures, making manual review impractical and costly. These demands have intensified interest in automated methods that can efficiently organize and describe large-scale image datasets. This paper presents a systematic investigation of automated cluster description generation through the integration of image clustering, image captioning, and large language models (LLMs). We apply K-means clustering to group images into 20 visually coherent clusters and generate base captions using the Azure AI Vision API. We then evaluate three critical dimensions of the cluster description process: (1) image sampling strategies, comparing random, centroid-based, stratified, hybrid, and density-based sampling against using all cluster images; (2) prompting techniques, contrasting standard prompting with chain-of-thought prompting; and (3) description generation methods, comparing LLM-based generation with traditional TF-IDF and template-based approaches. We assess description quality using semantic similarity and coverage metrics. Results show that strategic sampling with 20 images per cluster performs comparably to exhaustive inclusion while significantly reducing computational cost, with only stratified sampling showing modest degradation. LLM-based methods consistently outperform TF-IDF baselines, and standard prompts outperform chain-of-thought prompts for this task. These findings provide practical guidance for deploying scalable, accurate cluster description systems that support high-volume workflows in legal discovery and other domains requiring automated organization of large image collections.
Detecting Privileged Documents by Ranking Connected Network Entities
Dec 08, 2025
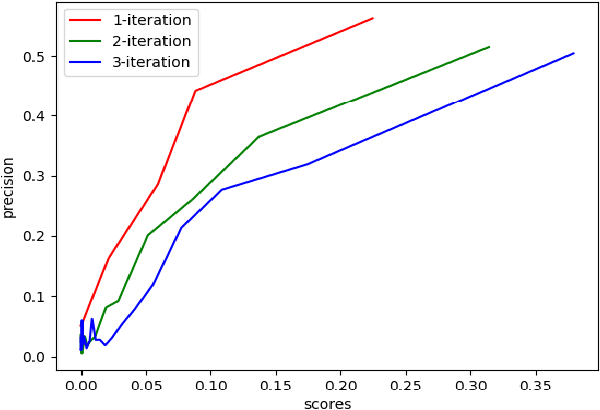


This paper presents a link analysis approach for identifying privileged documents by constructing a network of human entities derived from email header metadata. Entities are classified as either counsel or non-counsel based on a predefined list of known legal professionals. The core assumption is that individuals with frequent interactions with lawyers are more likely to participate in privileged communications. To quantify this likelihood, an algorithm assigns a score to each entity within the network. By utilizing both entity scores and the strength of their connections, the method enhances the identification of privileged documents. Experimental results demonstrate the algorithm's effectiveness in ranking legal entities for privileged document detection.
Explainable Text Classification Techniques in Legal Document Review: Locating Rationales without Using Human Annotated Training Text Snippets
Nov 15, 2023
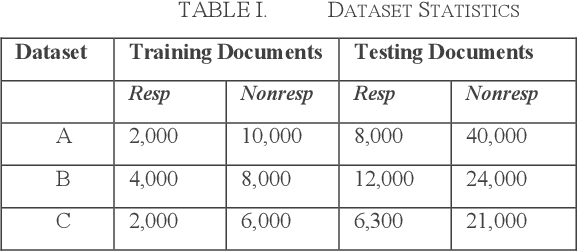


US corporations regularly spend millions of dollars reviewing electronically-stored documents in legal matters. Recently, attorneys apply text classification to efficiently cull massive volumes of data to identify responsive documents for use in these matters. While text classification is regularly used to reduce the discovery costs of legal matters, it also faces a perception challenge: amongst lawyers, this technology is sometimes looked upon as a "black box". Put simply, no extra information is provided for attorneys to understand why documents are classified as responsive. In recent years, explainable machine learning has emerged as an active research area. In an explainable machine learning system, predictions or decisions made by a machine learning model are human understandable. In legal 'document review' scenarios, a document is responsive, because one or more of its small text snippets are deemed responsive. In these scenarios, if these responsive snippets can be located, then attorneys could easily evaluate the model's document classification decisions - this is especially important in the field of responsible AI. Our prior research identified that predictive models created using annotated training text snippets improved the precision of a model when compared to a model created using all of a set of documents' text as training. While interesting, manually annotating training text snippets is not generally practical during a legal document review. However, small increases in precision can drastically decrease the cost of large document reviews. Automating the identification of training text snippets without human review could then make the application of training text snippet-based models a practical approach.
CNN Application in Detection of Privileged Documents in Legal Document Review
Feb 09, 2021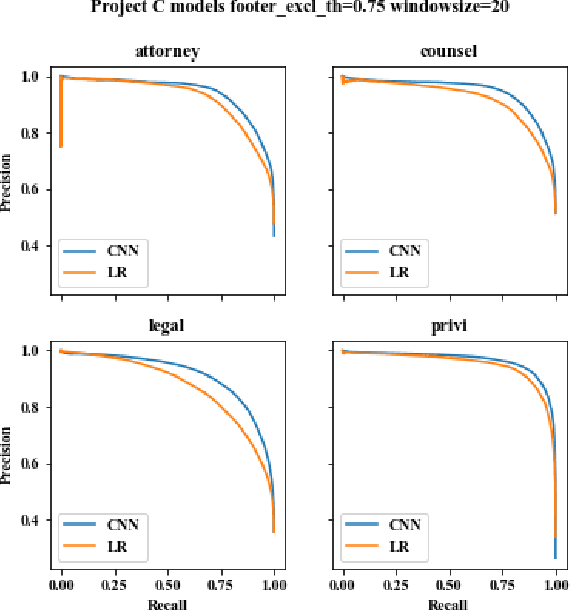
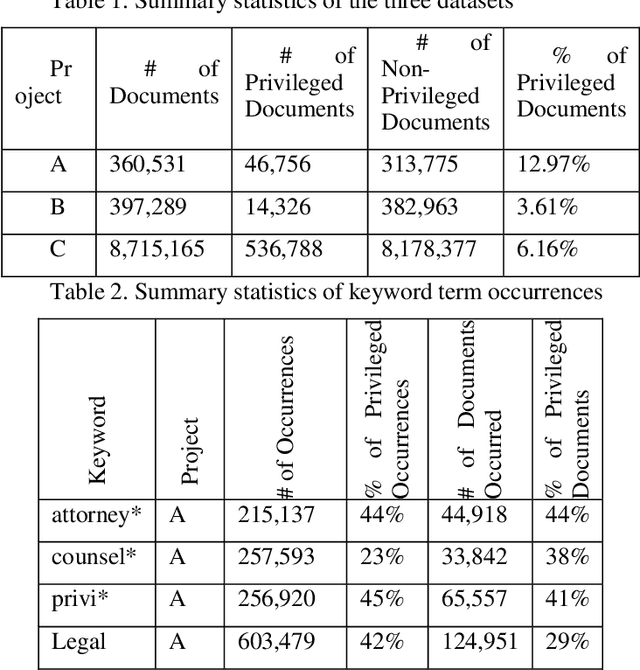
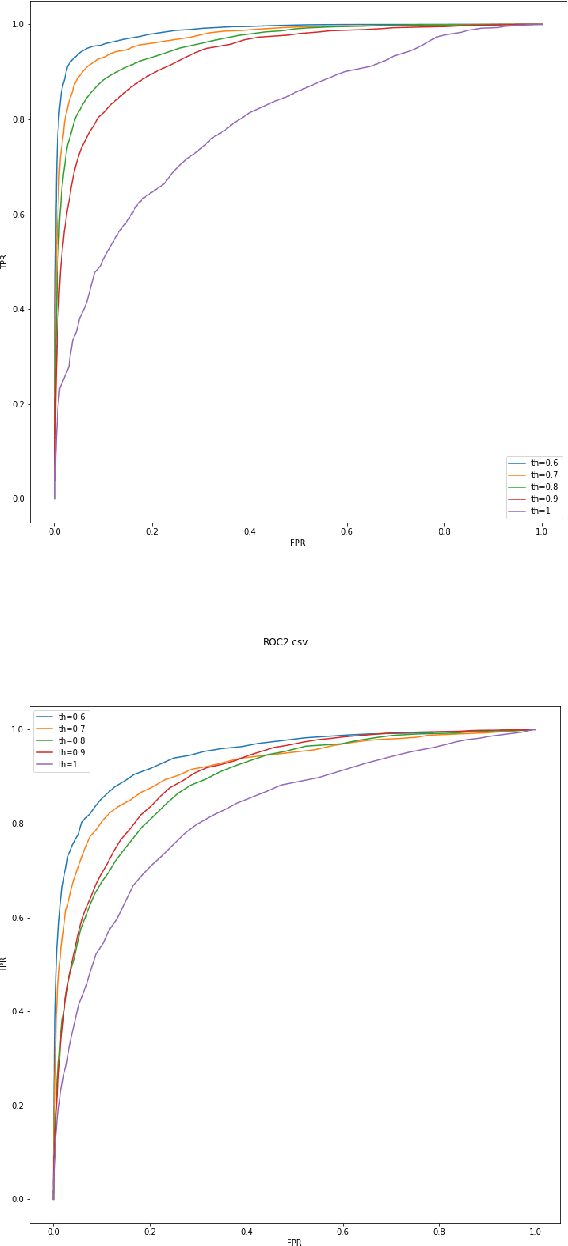
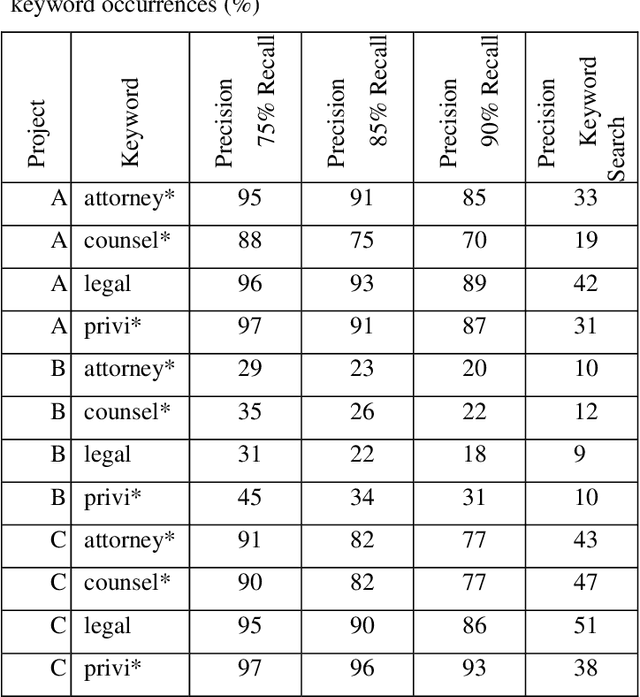
Protecting privileged communications and data from disclosure is paramount for legal teams. Legal advice, such as attorney-client communications or litigation strategy are typically exempt from disclosure in litigations or regulatory events and are vital to the attorney-client relationship. To protect this information from disclosure, companies and outside counsel often review vast amounts of documents to determine those that contain privileged material. This process is extremely costly and time consuming. As data volumes increase, legal counsel normally employs methods to reduce the number of documents requiring review while balancing the need to ensure the protection of privileged information. Keyword searching is relied upon as a method to target privileged information and reduce document review populations. Keyword searches are effective at casting a wide net but often return overly inclusive results - most of which do not contain privileged information. To overcome the weaknesses of keyword searching, legal teams increasingly are using machine learning techniques to target privileged information. In these studies, classic text classification techniques are applied to build classification models to identify privileged documents. In this paper, the authors propose a different method by applying machine learning / convolutional neural network techniques (CNN) to identify privileged documents. Our proposed method combines keyword searching with CNN. For each keyword term, a CNN model is created using the context of the occurrences of the keyword. In addition, a method was proposed to select reliable privileged (positive) training keyword occurrences from labeled positive training documents. Extensive experiments were conducted, and the results show that the proposed methods can significantly reduce false positives while still capturing most of the true positives.
Image Analytics for Legal Document Review: A Transfer Learning Approach
Dec 19, 2019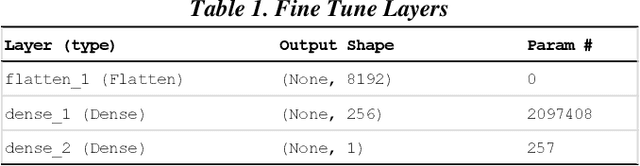

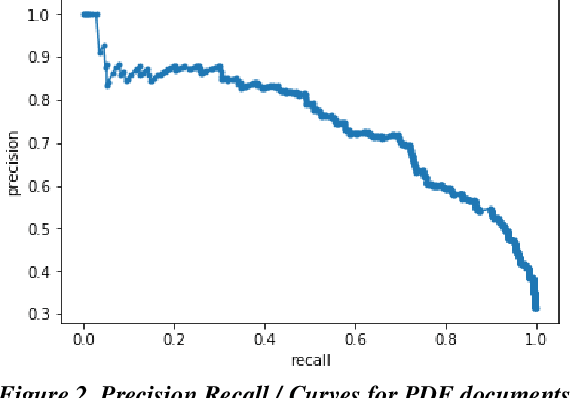
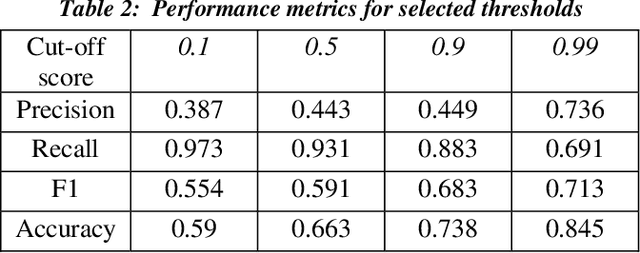
Though technology assisted review in electronic discovery has been focusing on text data, the need of advanced analytics to facilitate reviewing multimedia content is on the rise. In this paper, we present several applications of deep learning in computer vision to Technology Assisted Review of image data in legal industry. These applications include image classification, image clustering, and object detection. We use transfer learning techniques to leverage established pretrained models for feature extraction and fine tuning. These applications are first of their kind in the legal industry for image document review. We demonstrate effectiveness of these applications with solving real world business challenges.
A Framework for Explainable Text Classification in Legal Document Review
Dec 19, 2019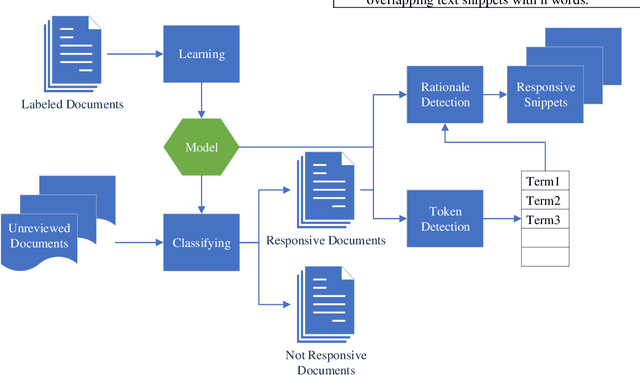
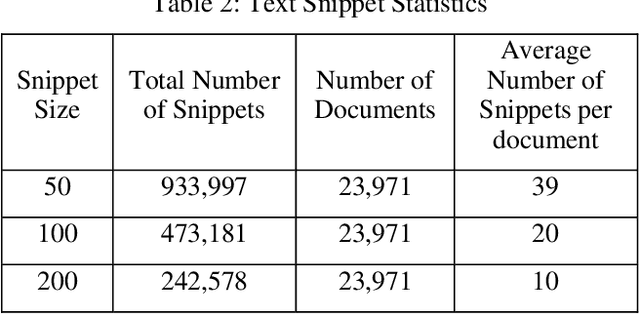
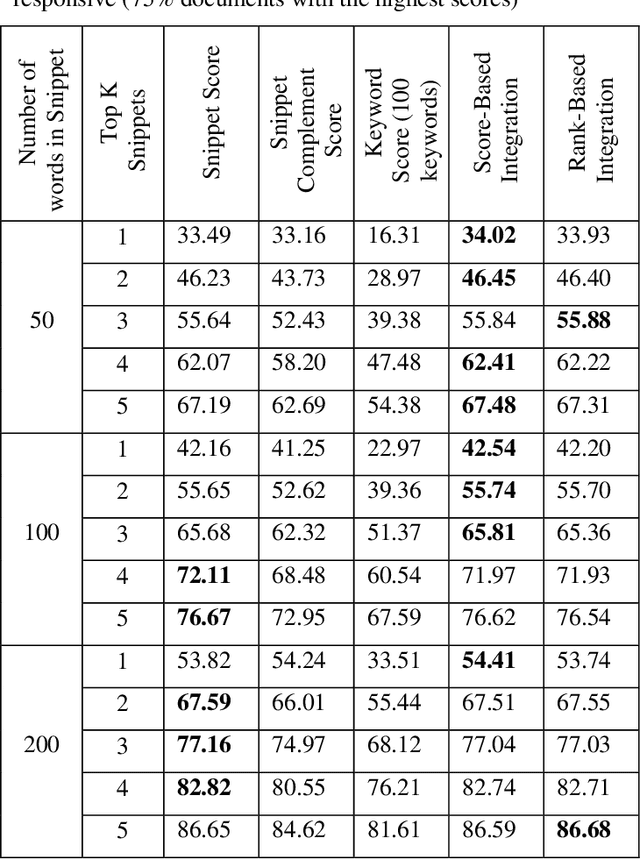
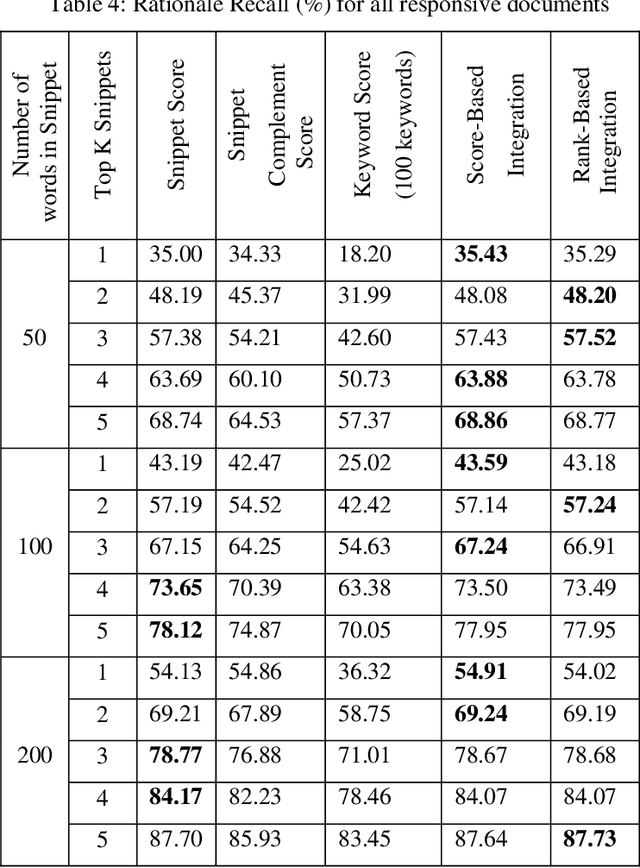
Companies regularly spend millions of dollars producing electronically-stored documents in legal matters. Recently, parties on both sides of the 'legal aisle' are accepting the use of machine learning techniques like text classification to cull massive volumes of data and to identify responsive documents for use in these matters. While text classification is regularly used to reduce the discovery costs in legal matters, it also faces a peculiar perception challenge: amongst lawyers, this technology is sometimes looked upon as a "black box", little information provided for attorneys to understand why documents are classified as responsive. In recent years, a group of AI and ML researchers have been actively researching Explainable AI, in which actions or decisions are human understandable. In legal document review scenarios, a document can be identified as responsive, if one or more of its text snippets are deemed responsive. In these scenarios, if text classification can be used to locate these snippets, then attorneys could easily evaluate the model's classification decision. When deployed with defined and explainable results, text classification can drastically enhance overall quality and speed of the review process by reducing the review time. Moreover, explainable predictive coding provides lawyers with greater confidence in the results of that supervised learning task. This paper describes a framework for explainable text classification as a valuable tool in legal services: for enhancing the quality and efficiency of legal document review and for assisting in locating responsive snippets within responsive documents. This framework has been implemented in our legal analytics product, which has been used in hundreds of legal matters. We also report our experimental results using the data from an actual legal matter that used this type of document review.
Empirical Comparisons of CNN with Other Learning Algorithms for Text Classification in Legal Document Review
Dec 19, 2019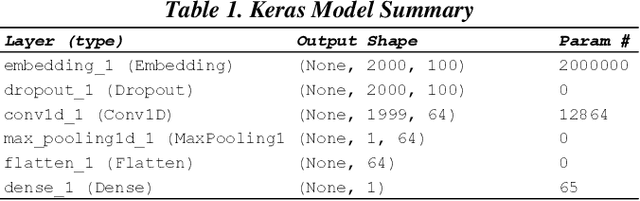
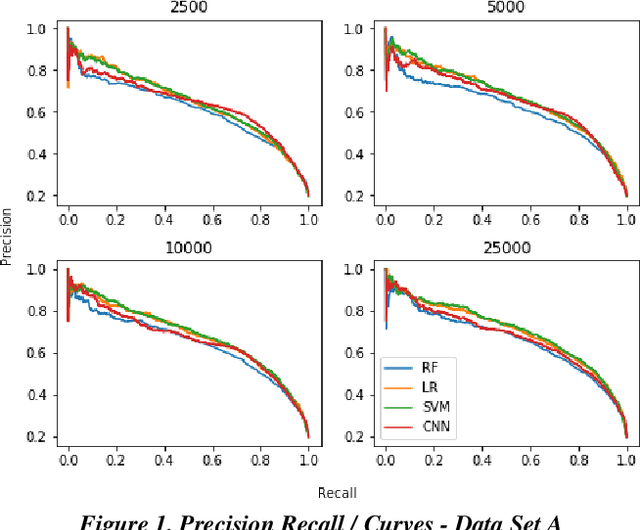
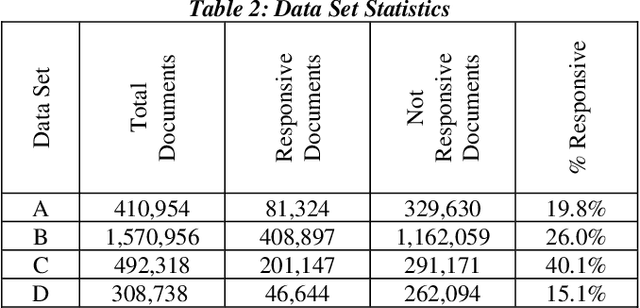
Research has shown that Convolutional Neural Networks (CNN) can be effectively applied to text classification as part of a predictive coding protocol. That said, most research to date has been conducted on data sets with short documents that do not reflect the variety of documents in real world document reviews. Using data from four actual reviews with documents of varying lengths, we compared CNN with other popular machine learning algorithms for text classification, including Logistic Regression, Support Vector Machine, and Random Forest. For each data set, classification models were trained with different training sample sizes using different learning algorithms. These models were then evaluated using a large randomly sampled test set of documents, and the results were compared using precision and recall curves. Our study demonstrates that CNN performed well, but that there was no single algorithm that performed the best across the combination of data sets and training sample sizes. These results will help advance research into the legal profession's use of machine learning algorithms that maximize performance.
Evaluation of Seed Set Selection Approaches and Active Learning Strategies in Predictive Coding
Jun 11, 2019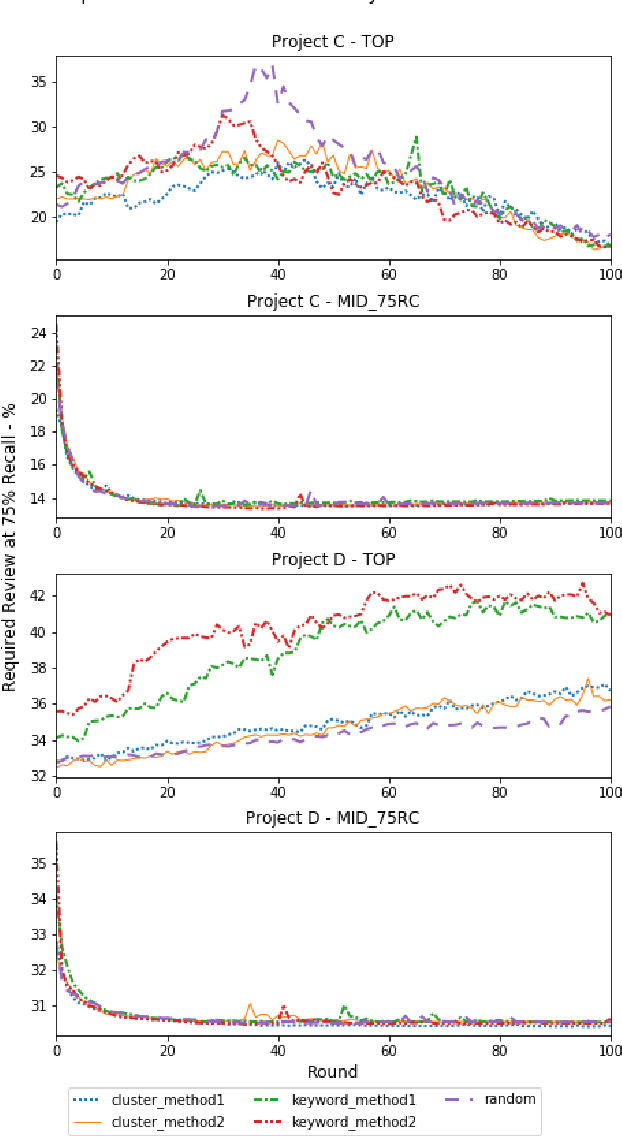
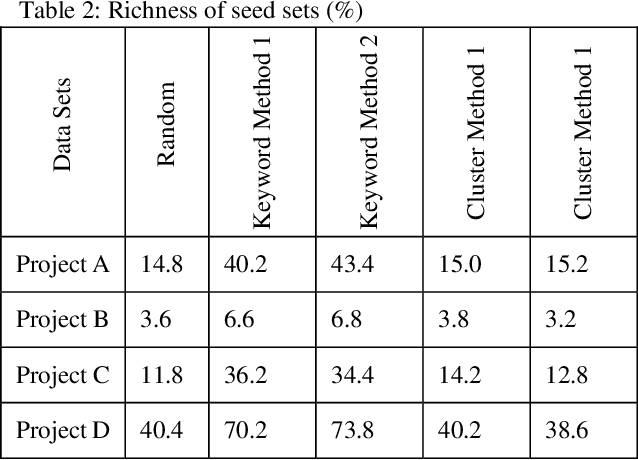
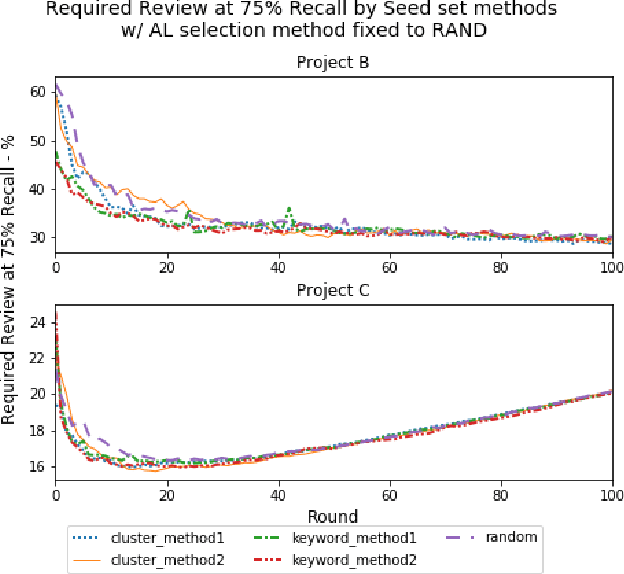
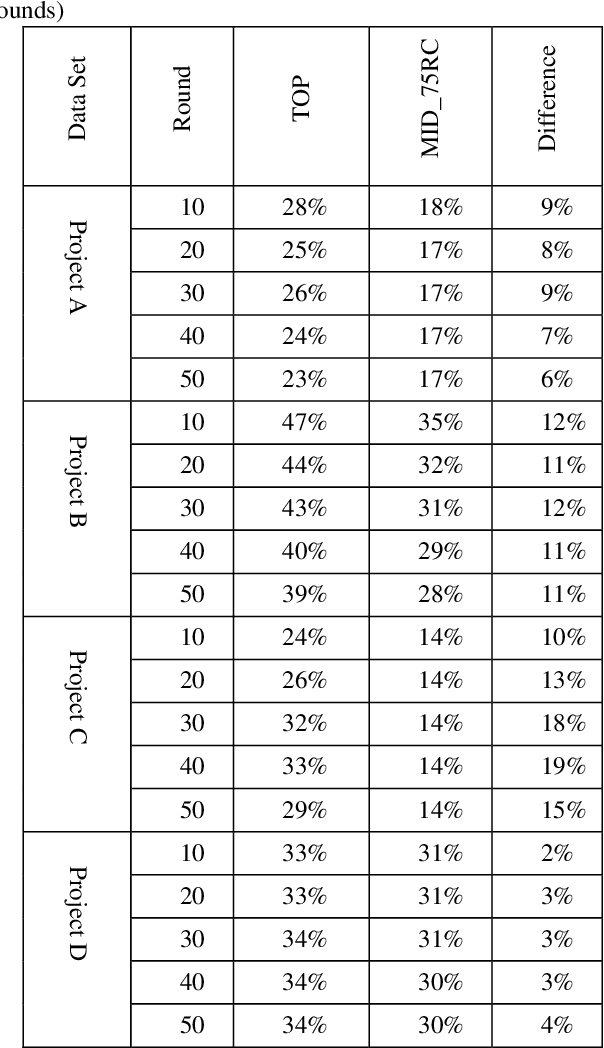
Active learning is a popular methodology in text classification - known in the legal domain as "predictive coding" or "Technology Assisted Review" or "TAR" - due to its potential to minimize the required review effort to build effective classifiers. In this study, we use extensive experimentation to examine the impact of popular seed set selection strategies in active learning, within a predictive coding exercise, and evaluate different active learning strategies against well-researched continuous active learning strategies for the purpose of determining efficient training methods for classifying large populations quickly and precisely. We study how random sampling, keyword models and clustering based seed set selection strategies combined together with top-ranked, uncertain, random, recall inspired, and hybrid active learning document selection strategies affect the performance of active learning for predictive coding. We use the percentage of documents requiring review to reach 75% recall as the "benchmark" metric to evaluate and compare our approaches. In most cases we find that seed set selection methods have a minor impact, though they do show significant impact in lower richness data sets or when choosing a top-ranked active learning selection strategy. Our results also show that active learning selection strategies implementing uncertainty, random, or 75% recall selection strategies has the potential to reach the optimum active learning round much earlier than the popular continuous active learning approach (top-ranked selection). The results of our research shed light on the impact of active learning seed set selection strategies and also the effectiveness of the selection strategies for the following learning rounds. Legal practitioners can use the results of this study to enhance the efficiency, precision, and simplicity of their predictive coding process.