 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplication of Deep Learning in Recognizing Bates Numbers and Confidentiality Stamping from Images
Feb 05, 2021


In eDiscovery, it is critical to ensure that each page produced in legal proceedings conforms with the requirements of court or government agency production requests. Errors in productions could have severe consequences in a case, putting a party in an adverse position. The volume of pages produced continues to increase, and tremendous time and effort has been taken to ensure quality control of document productions. This has historically been a manual and laborious process. This paper demonstrates a novel automated production quality control application which leverages deep learning-based image recognition technology to extract Bates Number and Confidentiality Stamping from legal case production images and validate their correctness. Effectiveness of the method is verified with an experiment using a real-world production data.
Empirical Evaluations of Seed Set Selection Strategies for Predictive Coding
Mar 21, 2019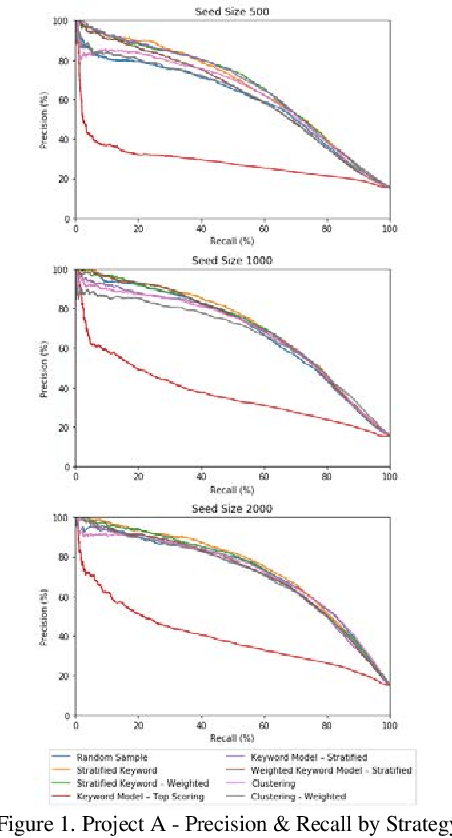
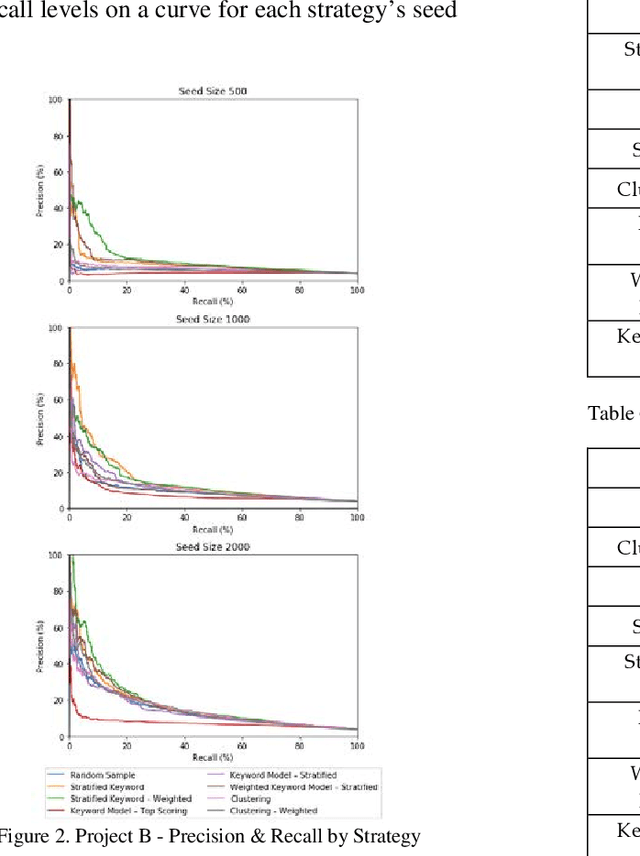
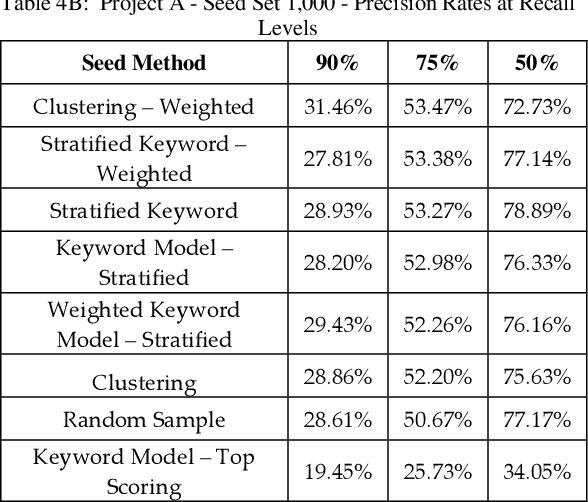
Training documents have a significant impact on the performance of predictive models in the legal domain. Yet, there is limited research that explores the effectiveness of the training document selection strategy - in particular, the strategy used to select the seed set, or the set of documents an attorney reviews first to establish an initial model. Since there is limited research on this important component of predictive coding, the authors of this paper set out to identify strategies that consistently perform well. Our research demonstrated that the seed set selection strategy can have a significant impact on the precision of a predictive model. Enabling attorneys with the results of this study will allow them to initiate the most effective predictive modeling process to comb through the terabytes of data typically present in modern litigation. This study used documents from four actual legal cases to evaluate eight different seed set selection strategies. Attorneys can use the results contained within this paper to enhance their approach to predictive coding.