 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study of Retrieval Methods in Azure AI Search
Dec 08, 2025Increasingly, attorneys are interested in moving beyond keyword and semantic search to improve the efficiency of how they find key information during a document review task. Large language models (LLMs) are now seen as tools that attorneys can use to ask natural language questions of their data during document review to receive accurate and concise answers. This study evaluates retrieval strategies within Microsoft Azure's Retrieval-Augmented Generation (RAG) framework to identify effective approaches for Early Case Assessment (ECA) in eDiscovery. During ECA, legal teams analyze data at the outset of a matter to gain a general understanding of the data and attempt to determine key facts and risks before beginning full-scale review. In this paper, we compare the performance of Azure AI Search's keyword, semantic, vector, hybrid, and hybrid-semantic retrieval methods. We then present the accuracy, relevance, and consistency of each method's AI-generated responses. Legal practitioners can use the results of this study to enhance how they select RAG configurations in the future.
Leveraging Machine Learning and Large Language Models for Automated Image Clustering and Description in Legal Discovery
Dec 08, 2025The rapid increase in digital image creation and retention presents substantial challenges during legal discovery, digital archive, and content management. Corporations and legal teams must organize, analyze, and extract meaningful insights from large image collections under strict time pressures, making manual review impractical and costly. These demands have intensified interest in automated methods that can efficiently organize and describe large-scale image datasets. This paper presents a systematic investigation of automated cluster description generation through the integration of image clustering, image captioning, and large language models (LLMs). We apply K-means clustering to group images into 20 visually coherent clusters and generate base captions using the Azure AI Vision API. We then evaluate three critical dimensions of the cluster description process: (1) image sampling strategies, comparing random, centroid-based, stratified, hybrid, and density-based sampling against using all cluster images; (2) prompting techniques, contrasting standard prompting with chain-of-thought prompting; and (3) description generation methods, comparing LLM-based generation with traditional TF-IDF and template-based approaches. We assess description quality using semantic similarity and coverage metrics. Results show that strategic sampling with 20 images per cluster performs comparably to exhaustive inclusion while significantly reducing computational cost, with only stratified sampling showing modest degradation. LLM-based methods consistently outperform TF-IDF baselines, and standard prompts outperform chain-of-thought prompts for this task. These findings provide practical guidance for deploying scalable, accurate cluster description systems that support high-volume workflows in legal discovery and other domains requiring automated organization of large image collections.
Detecting Privileged Documents by Ranking Connected Network Entities
Dec 08, 2025
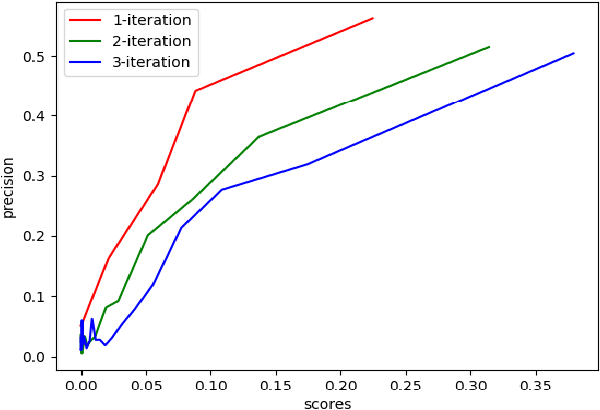


This paper presents a link analysis approach for identifying privileged documents by constructing a network of human entities derived from email header metadata. Entities are classified as either counsel or non-counsel based on a predefined list of known legal professionals. The core assumption is that individuals with frequent interactions with lawyers are more likely to participate in privileged communications. To quantify this likelihood, an algorithm assigns a score to each entity within the network. By utilizing both entity scores and the strength of their connections, the method enhances the identification of privileged documents. Experimental results demonstrate the algorithm's effectiveness in ranking legal entities for privileged document detection.
Use Image Clustering to Facilitate Technology Assisted Review
Dec 16, 2021During the past decade breakthroughs in GPU hardware and deep neural networks technologies have revolutionized the field of computer vision, making image analytical potentials accessible to a range of real-world applications. Technology Assisted Review (TAR) in electronic discovery though traditionally has dominantly dealt with textual content, is witnessing a rising need to incorporate multimedia content in the scope. We have developed innovative image analytics applications for TAR in the past years, such as image classification, image clustering, and object detection, etc. In this paper, we discuss the use of image clustering applications to facilitate TAR based on our experiences in serving clients. We describe our general workflow on leveraging image clustering in tasks and use statistics from real projects to showcase the effectiveness of using image clustering in TAR. We also summarize lessons learned and best practices on using image clustering in TAR.
Application of Deep Learning in Recognizing Bates Numbers and Confidentiality Stamping from Images
Feb 05, 2021


In eDiscovery, it is critical to ensure that each page produced in legal proceedings conforms with the requirements of court or government agency production requests. Errors in productions could have severe consequences in a case, putting a party in an adverse position. The volume of pages produced continues to increase, and tremendous time and effort has been taken to ensure quality control of document productions. This has historically been a manual and laborious process. This paper demonstrates a novel automated production quality control application which leverages deep learning-based image recognition technology to extract Bates Number and Confidentiality Stamping from legal case production images and validate their correctness. Effectiveness of the method is verified with an experiment using a real-world production data.
Image Analytics for Legal Document Review: A Transfer Learning Approach
Dec 19, 2019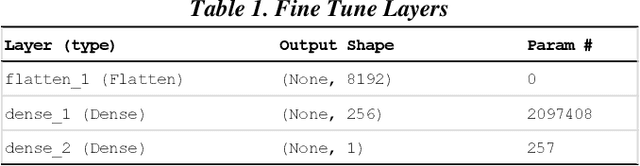

Though technology assisted review in electronic discovery has been focusing on text data, the need of advanced analytics to facilitate reviewing multimedia content is on the rise. In this paper, we present several applications of deep learning in computer vision to Technology Assisted Review of image data in legal industry. These applications include image classification, image clustering, and object detection. We use transfer learning techniques to leverage established pretrained models for feature extraction and fine tuning. These applications are first of their kind in the legal industry for image document review. We demonstrate effectiveness of these applications with solving real world business challenges.
Empirical Comparisons of CNN with Other Learning Algorithms for Text Classification in Legal Document Review
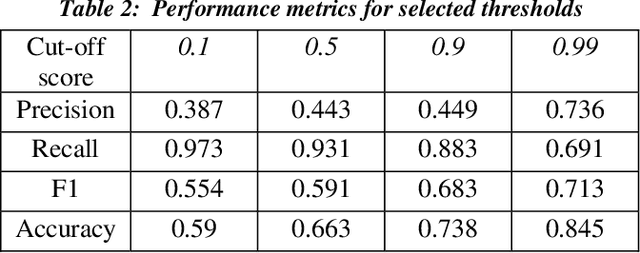
Dec 19, 2019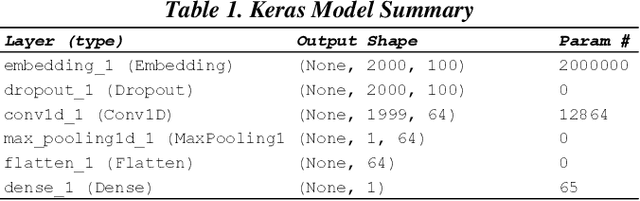
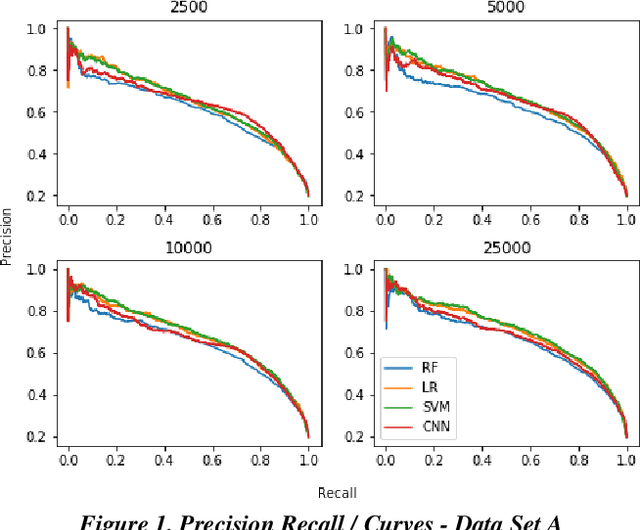
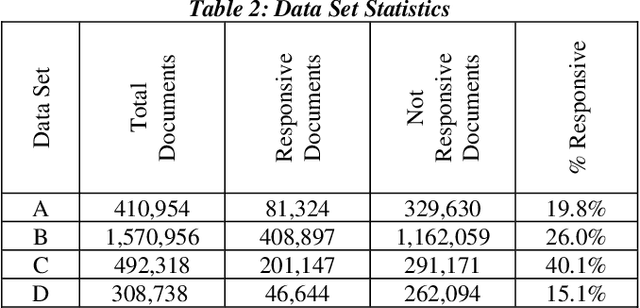
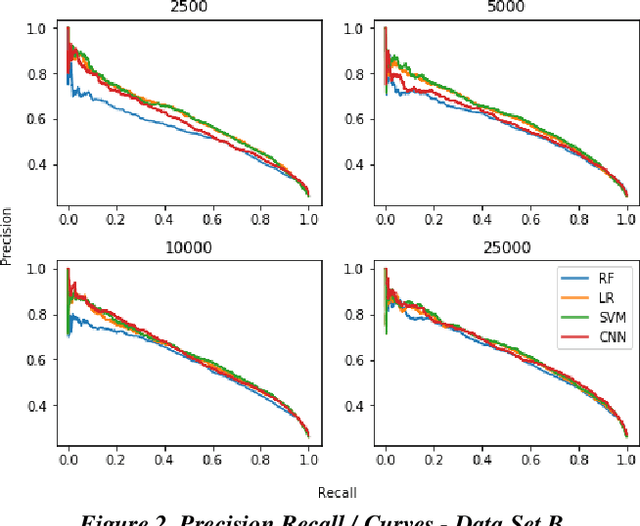
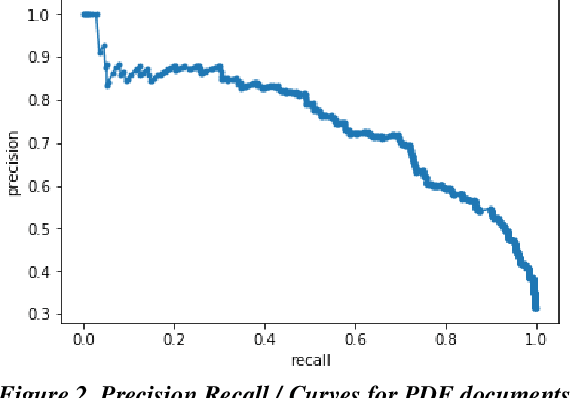
Research has shown that Convolutional Neural Networks (CNN) can be effectively applied to text classification as part of a predictive coding protocol. That said, most research to date has been conducted on data sets with short documents that do not reflect the variety of documents in real world document reviews. Using data from four actual reviews with documents of varying lengths, we compared CNN with other popular machine learning algorithms for text classification, including Logistic Regression, Support Vector Machine, and Random Forest. For each data set, classification models were trained with different training sample sizes using different learning algorithms. These models were then evaluated using a large randomly sampled test set of documents, and the results were compared using precision and recall curves. Our study demonstrates that CNN performed well, but that there was no single algorithm that performed the best across the combination of data sets and training sample sizes. These results will help advance research into the legal profession's use of machine learning algorithms that maximize performance.
Empirical Study of Deep Learning for Text Classification in Legal Document Review
Apr 03, 2019
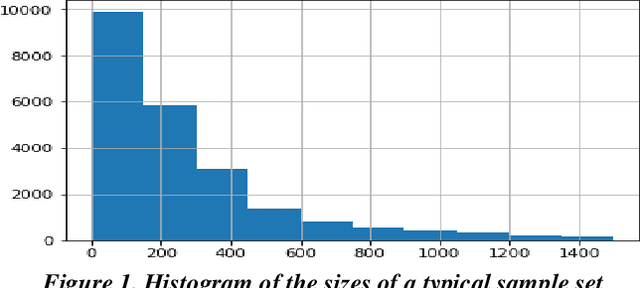
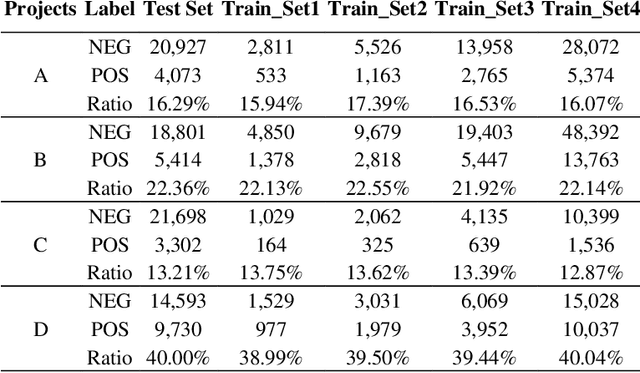
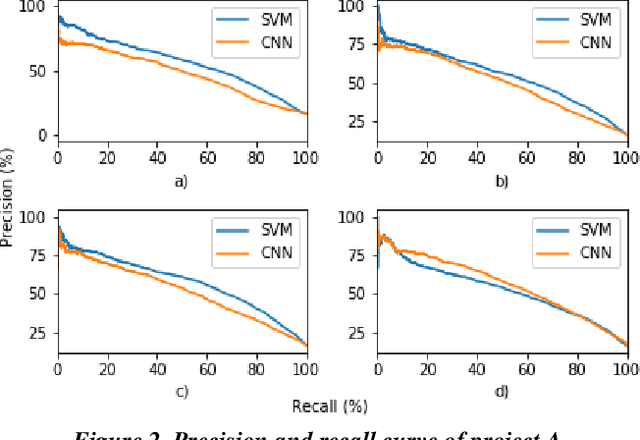
Predictive coding has been widely used in legal matters to find relevant or privileged documents in large sets of electronically stored information. It saves the time and cost significantly. Logistic Regression (LR) and Support Vector Machines (SVM) are two popular machine learning algorithms used in predictive coding. Recently, deep learning received a lot of attentions in many industries. This paper reports our preliminary studies in using deep learning in legal document review. Specifically, we conducted experiments to compare deep learning results with results obtained using a SVM algorithm on the four datasets of real legal matters. Our results showed that CNN performed better with larger volume of training dataset and should be a fit method in the text classification in legal industry.