 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study on Transfer Learning for Privilege Review
Dec 16, 2021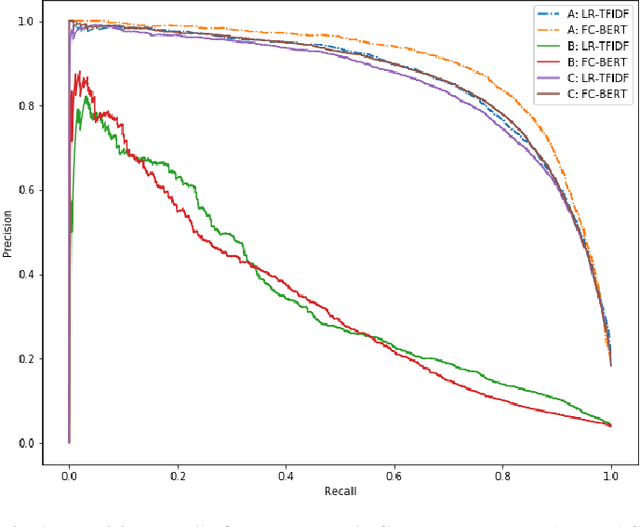
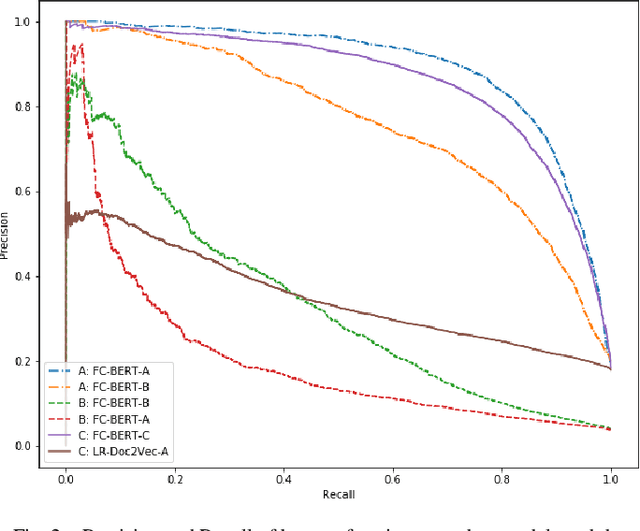
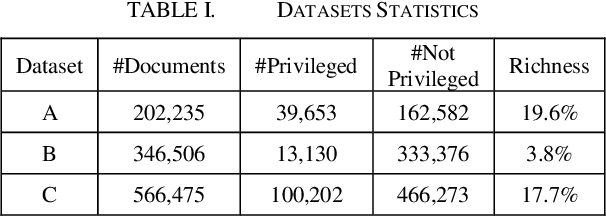
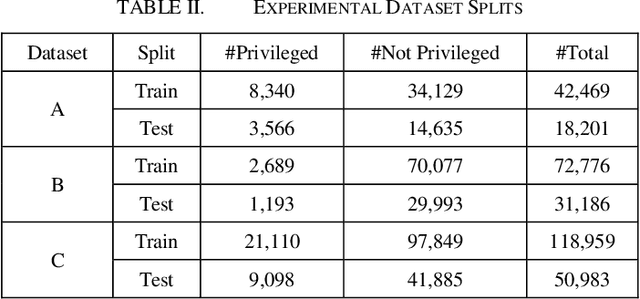
Protecting privileged communications and data from inadvertent disclosure is a paramount task in the US legal practice. Traditionally counsels rely on keyword searching and manual review to identify privileged documents in cases. As data volumes increase, this approach becomes less and less defensible in costs. Machine learning methods have been used in identifying privilege documents. Given the generalizable nature of privilege in legal cases, we hypothesize that transfer learning can capitalize knowledge learned from existing labeled data to identify privilege documents without requiring labeling new training data. In this paper, we study both traditional machine learning models and deep learning models based on BERT for privilege document classification tasks in legal document review, and we examine the effectiveness of transfer learning in privilege model on three real world datasets with privilege labels. Our results show that BERT model outperforms the industry standard logistic regression algorithm and transfer learning models can achieve decent performance on datasets in same or close domains.
Use Image Clustering to Facilitate Technology Assisted Review
Dec 16, 2021During the past decade breakthroughs in GPU hardware and deep neural networks technologies have revolutionized the field of computer vision, making image analytical potentials accessible to a range of real-world applications. Technology Assisted Review (TAR) in electronic discovery though traditionally has dominantly dealt with textual content, is witnessing a rising need to incorporate multimedia content in the scope. We have developed innovative image analytics applications for TAR in the past years, such as image classification, image clustering, and object detection, etc. In this paper, we discuss the use of image clustering applications to facilitate TAR based on our experiences in serving clients. We describe our general workflow on leveraging image clustering in tasks and use statistics from real projects to showcase the effectiveness of using image clustering in TAR. We also summarize lessons learned and best practices on using image clustering in TAR.
CNN Application in Detection of Privileged Documents in Legal Document Review
Feb 09, 2021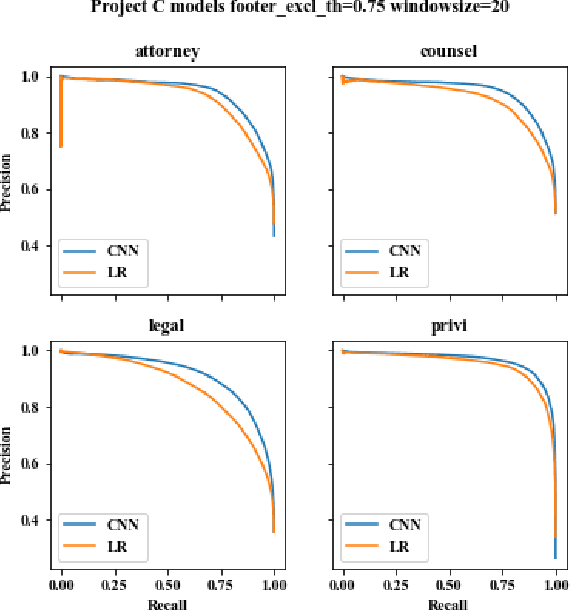
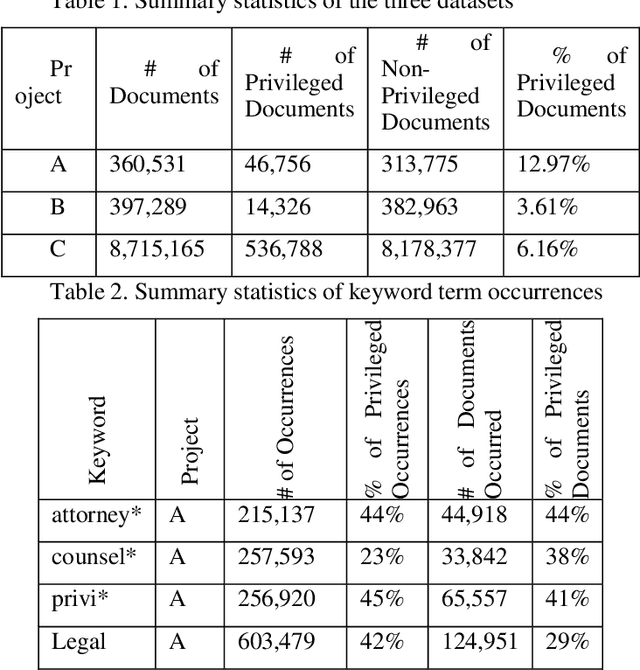
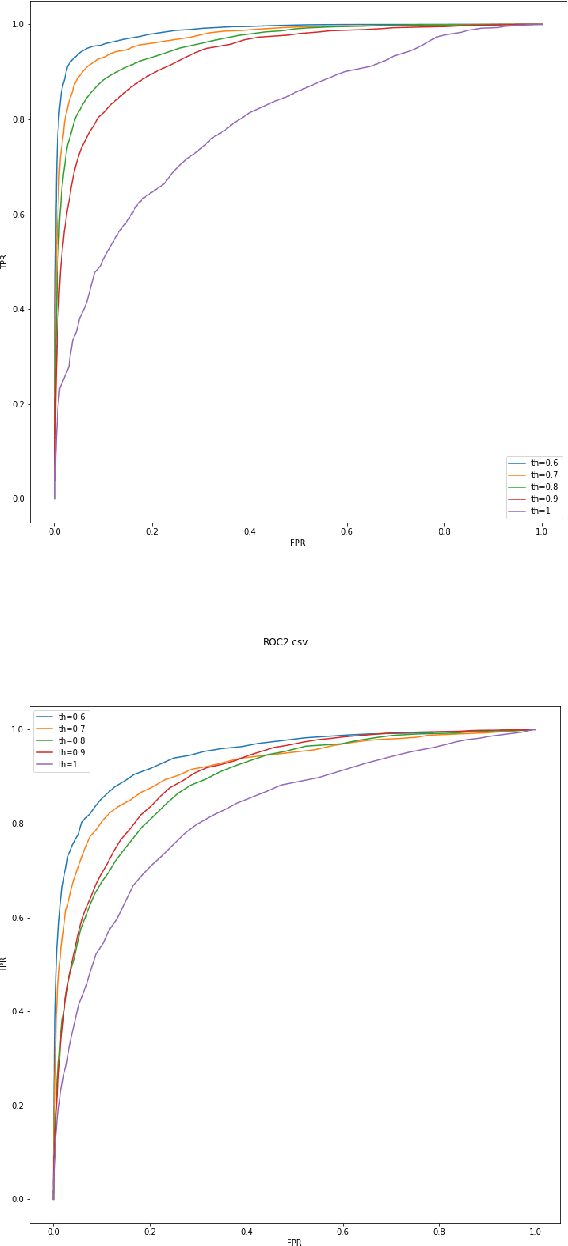
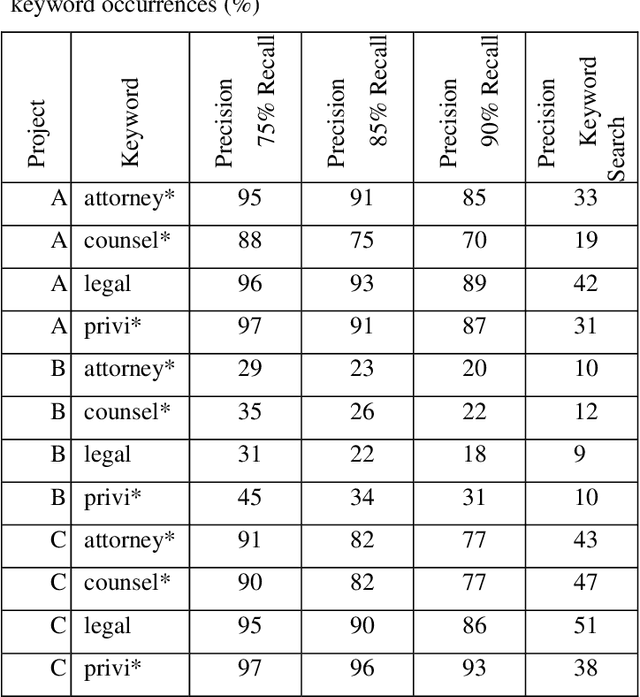
Protecting privileged communications and data from disclosure is paramount for legal teams. Legal advice, such as attorney-client communications or litigation strategy are typically exempt from disclosure in litigations or regulatory events and are vital to the attorney-client relationship. To protect this information from disclosure, companies and outside counsel often review vast amounts of documents to determine those that contain privileged material. This process is extremely costly and time consuming. As data volumes increase, legal counsel normally employs methods to reduce the number of documents requiring review while balancing the need to ensure the protection of privileged information. Keyword searching is relied upon as a method to target privileged information and reduce document review populations. Keyword searches are effective at casting a wide net but often return overly inclusive results - most of which do not contain privileged information. To overcome the weaknesses of keyword searching, legal teams increasingly are using machine learning techniques to target privileged information. In these studies, classic text classification techniques are applied to build classification models to identify privileged documents. In this paper, the authors propose a different method by applying machine learning / convolutional neural network techniques (CNN) to identify privileged documents. Our proposed method combines keyword searching with CNN. For each keyword term, a CNN model is created using the context of the occurrences of the keyword. In addition, a method was proposed to select reliable privileged (positive) training keyword occurrences from labeled positive training documents. Extensive experiments were conducted, and the results show that the proposed methods can significantly reduce false positives while still capturing most of the true positives.
Application of Deep Learning in Recognizing Bates Numbers and Confidentiality Stamping from Images
Feb 05, 2021


In eDiscovery, it is critical to ensure that each page produced in legal proceedings conforms with the requirements of court or government agency production requests. Errors in productions could have severe consequences in a case, putting a party in an adverse position. The volume of pages produced continues to increase, and tremendous time and effort has been taken to ensure quality control of document productions. This has historically been a manual and laborious process. This paper demonstrates a novel automated production quality control application which leverages deep learning-based image recognition technology to extract Bates Number and Confidentiality Stamping from legal case production images and validate their correctness. Effectiveness of the method is verified with an experiment using a real-world production data.
Image Analytics for Legal Document Review: A Transfer Learning Approach
Dec 19, 2019

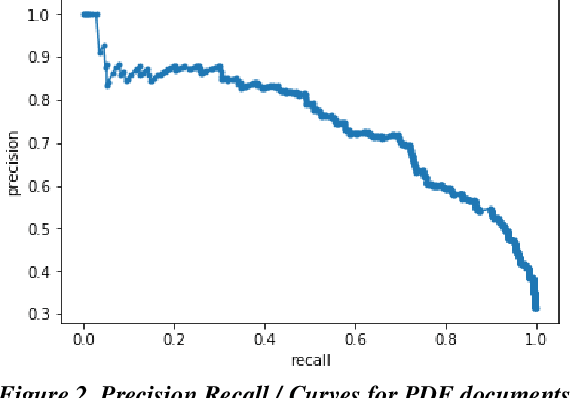
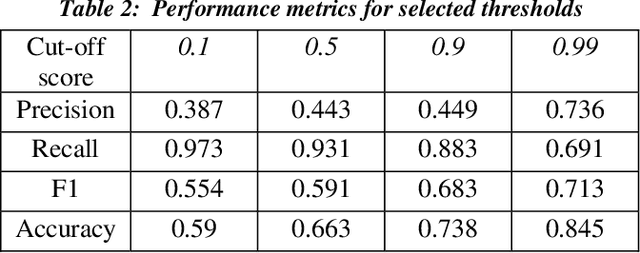
Though technology assisted review in electronic discovery has been focusing on text data, the need of advanced analytics to facilitate reviewing multimedia content is on the rise. In this paper, we present several applications of deep learning in computer vision to Technology Assisted Review of image data in legal industry. These applications include image classification, image clustering, and object detection. We use transfer learning techniques to leverage established pretrained models for feature extraction and fine tuning. These applications are first of their kind in the legal industry for image document review. We demonstrate effectiveness of these applications with solving real world business challenges.
A Framework for Explainable Text Classification in Legal Document Review
Dec 19, 2019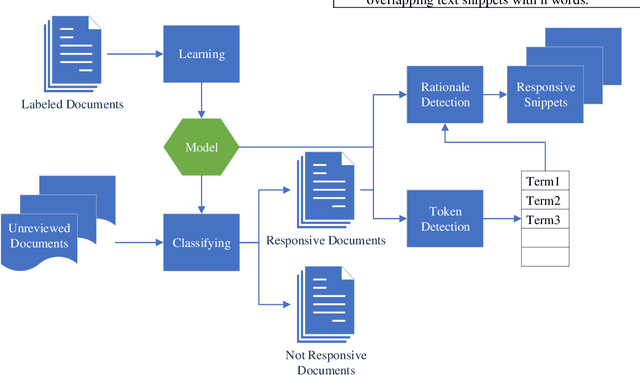
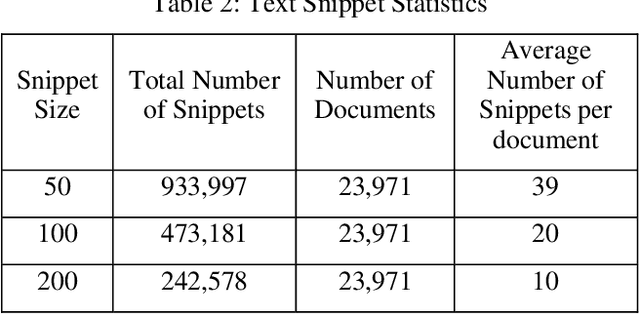
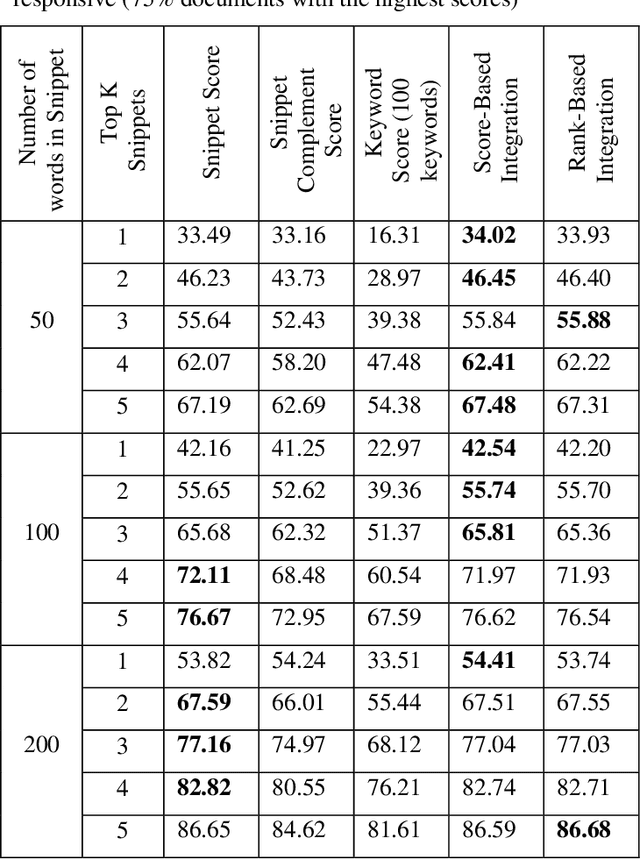
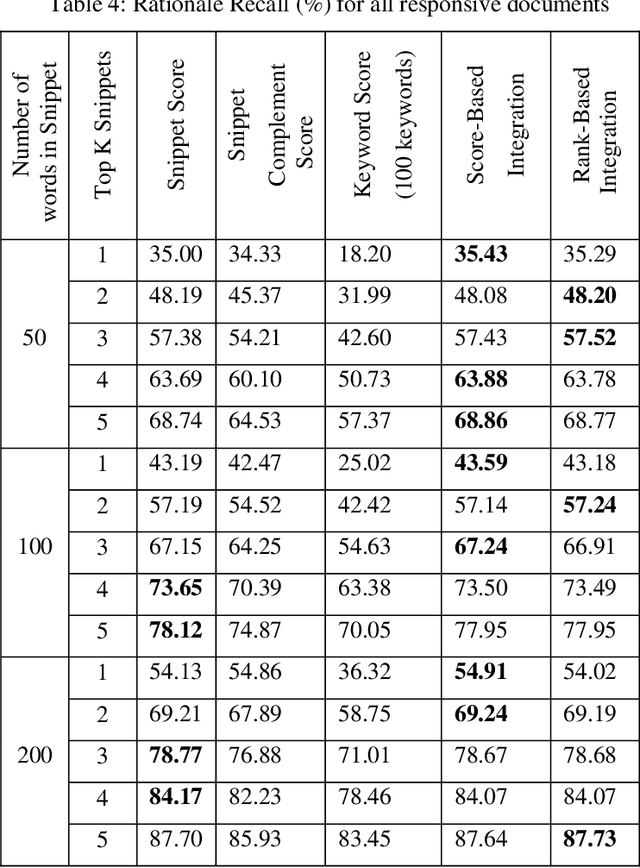
Companies regularly spend millions of dollars producing electronically-stored documents in legal matters. Recently, parties on both sides of the 'legal aisle' are accepting the use of machine learning techniques like text classification to cull massive volumes of data and to identify responsive documents for use in these matters. While text classification is regularly used to reduce the discovery costs in legal matters, it also faces a peculiar perception challenge: amongst lawyers, this technology is sometimes looked upon as a "black box", little information provided for attorneys to understand why documents are classified as responsive. In recent years, a group of AI and ML researchers have been actively researching Explainable AI, in which actions or decisions are human understandable. In legal document review scenarios, a document can be identified as responsive, if one or more of its text snippets are deemed responsive. In these scenarios, if text classification can be used to locate these snippets, then attorneys could easily evaluate the model's classification decision. When deployed with defined and explainable results, text classification can drastically enhance overall quality and speed of the review process by reducing the review time. Moreover, explainable predictive coding provides lawyers with greater confidence in the results of that supervised learning task. This paper describes a framework for explainable text classification as a valuable tool in legal services: for enhancing the quality and efficiency of legal document review and for assisting in locating responsive snippets within responsive documents. This framework has been implemented in our legal analytics product, which has been used in hundreds of legal matters. We also report our experimental results using the data from an actual legal matter that used this type of document review.
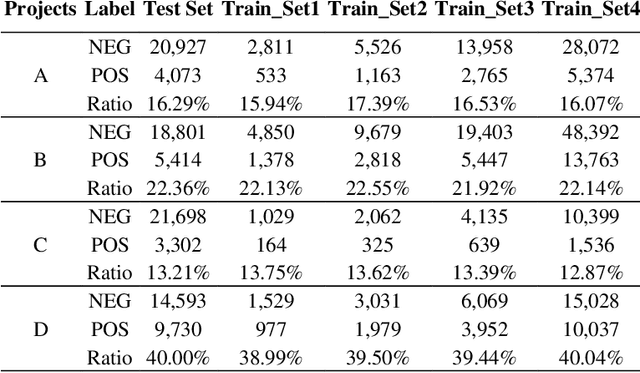
Empirical Comparisons of CNN with Other Learning Algorithms for Text Classification in Legal Document Review
Dec 19, 2019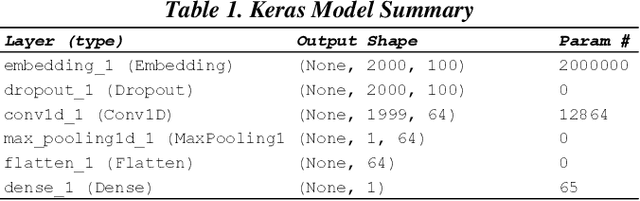
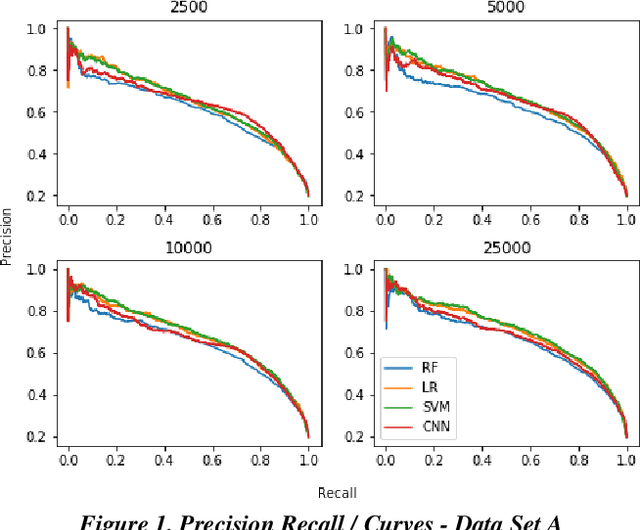
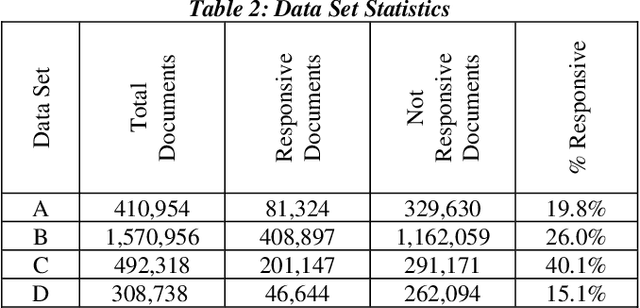
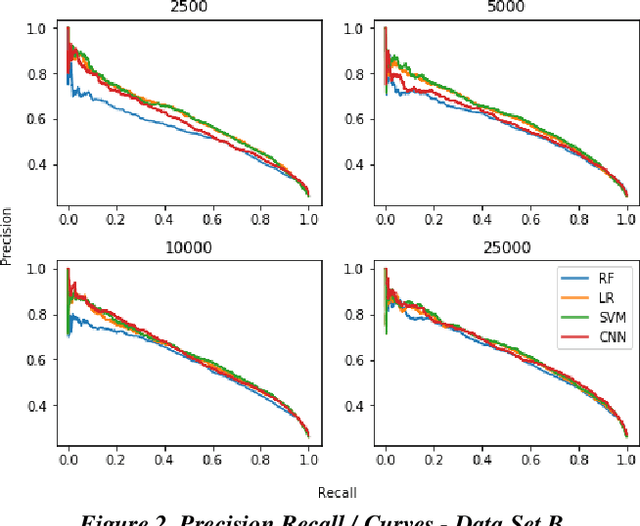
Research has shown that Convolutional Neural Networks (CNN) can be effectively applied to text classification as part of a predictive coding protocol. That said, most research to date has been conducted on data sets with short documents that do not reflect the variety of documents in real world document reviews. Using data from four actual reviews with documents of varying lengths, we compared CNN with other popular machine learning algorithms for text classification, including Logistic Regression, Support Vector Machine, and Random Forest. For each data set, classification models were trained with different training sample sizes using different learning algorithms. These models were then evaluated using a large randomly sampled test set of documents, and the results were compared using precision and recall curves. Our study demonstrates that CNN performed well, but that there was no single algorithm that performed the best across the combination of data sets and training sample sizes. These results will help advance research into the legal profession's use of machine learning algorithms that maximize performance.
Evaluation of Seed Set Selection Approaches and Active Learning Strategies in Predictive Coding
Jun 11, 2019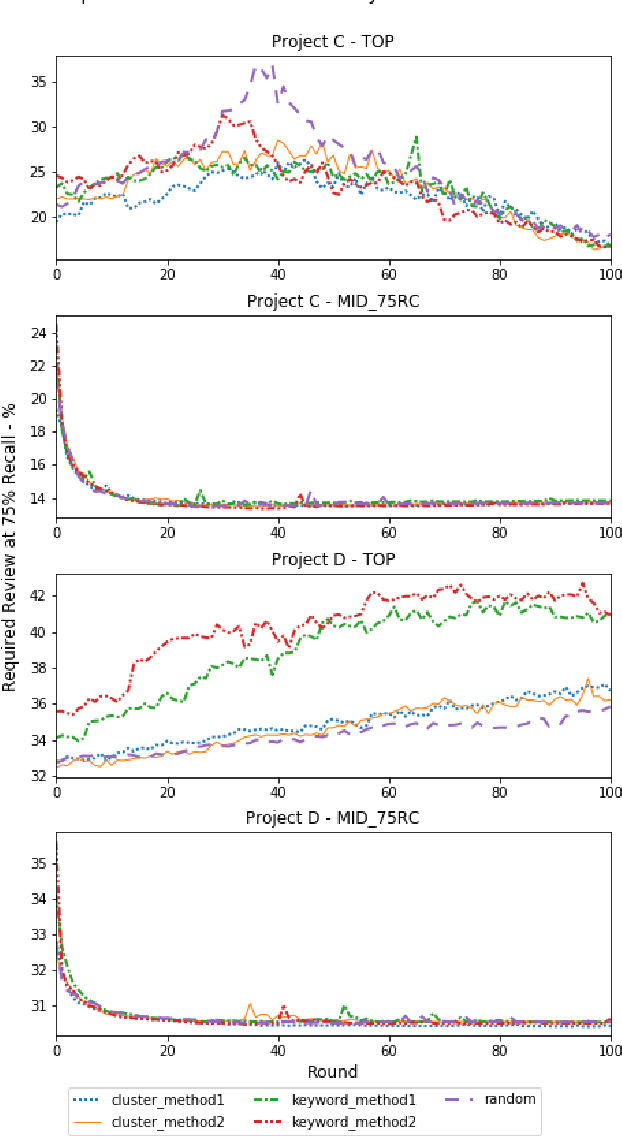
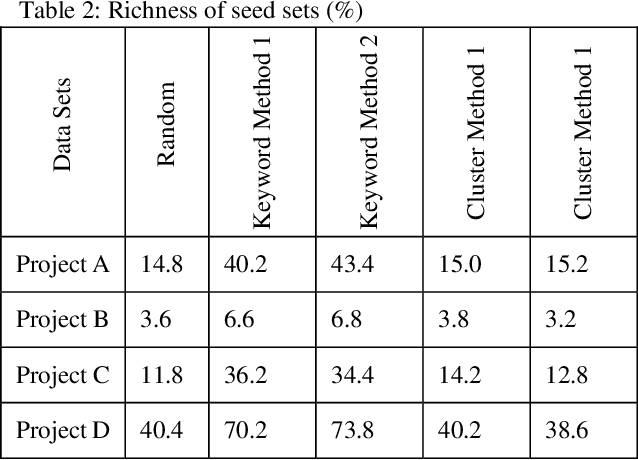
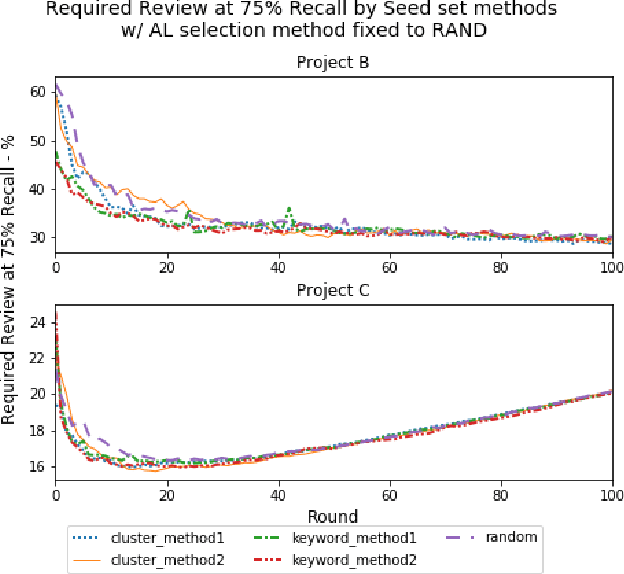
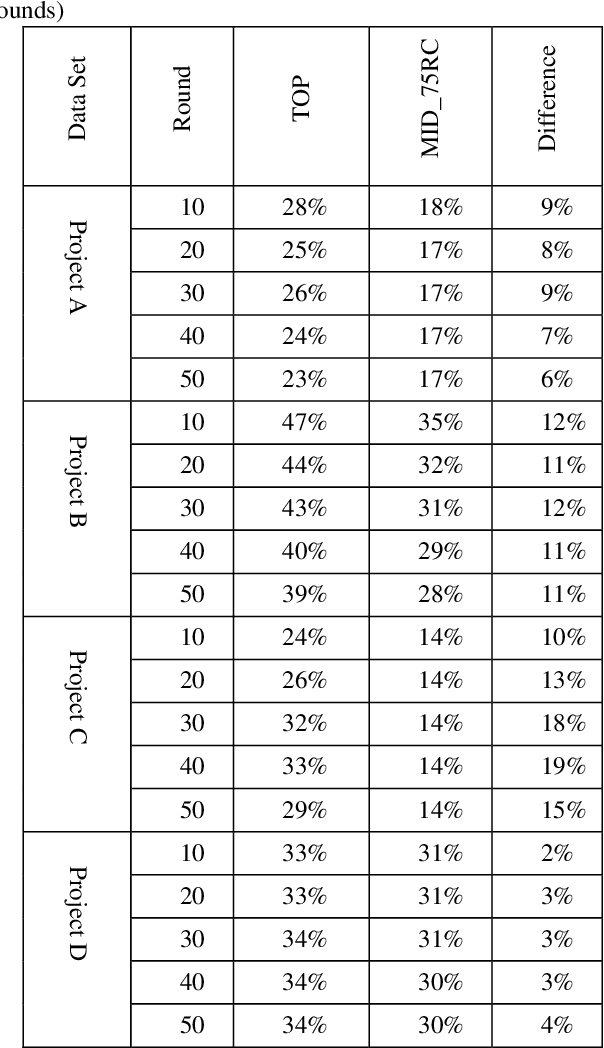
Active learning is a popular methodology in text classification - known in the legal domain as "predictive coding" or "Technology Assisted Review" or "TAR" - due to its potential to minimize the required review effort to build effective classifiers. In this study, we use extensive experimentation to examine the impact of popular seed set selection strategies in active learning, within a predictive coding exercise, and evaluate different active learning strategies against well-researched continuous active learning strategies for the purpose of determining efficient training methods for classifying large populations quickly and precisely. We study how random sampling, keyword models and clustering based seed set selection strategies combined together with top-ranked, uncertain, random, recall inspired, and hybrid active learning document selection strategies affect the performance of active learning for predictive coding. We use the percentage of documents requiring review to reach 75% recall as the "benchmark" metric to evaluate and compare our approaches. In most cases we find that seed set selection methods have a minor impact, though they do show significant impact in lower richness data sets or when choosing a top-ranked active learning selection strategy. Our results also show that active learning selection strategies implementing uncertainty, random, or 75% recall selection strategies has the potential to reach the optimum active learning round much earlier than the popular continuous active learning approach (top-ranked selection). The results of our research shed light on the impact of active learning seed set selection strategies and also the effectiveness of the selection strategies for the following learning rounds. Legal practitioners can use the results of this study to enhance the efficiency, precision, and simplicity of their predictive coding process.
Empirical Study of Deep Learning for Text Classification in Legal Document Review
Apr 03, 2019
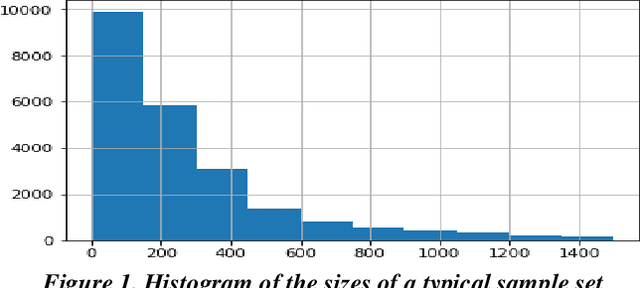
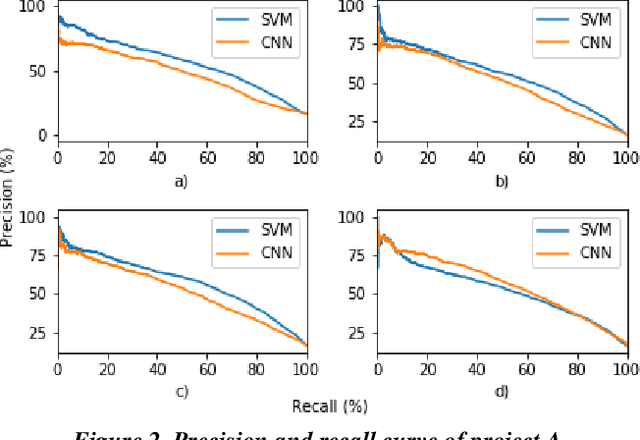
Predictive coding has been widely used in legal matters to find relevant or privileged documents in large sets of electronically stored information. It saves the time and cost significantly. Logistic Regression (LR) and Support Vector Machines (SVM) are two popular machine learning algorithms used in predictive coding. Recently, deep learning received a lot of attentions in many industries. This paper reports our preliminary studies in using deep learning in legal document review. Specifically, we conducted experiments to compare deep learning results with results obtained using a SVM algorithm on the four datasets of real legal matters. Our results showed that CNN performed better with larger volume of training dataset and should be a fit method in the text classification in legal industry.
Empirical Evaluations of Seed Set Selection Strategies for Predictive Coding
Mar 21, 2019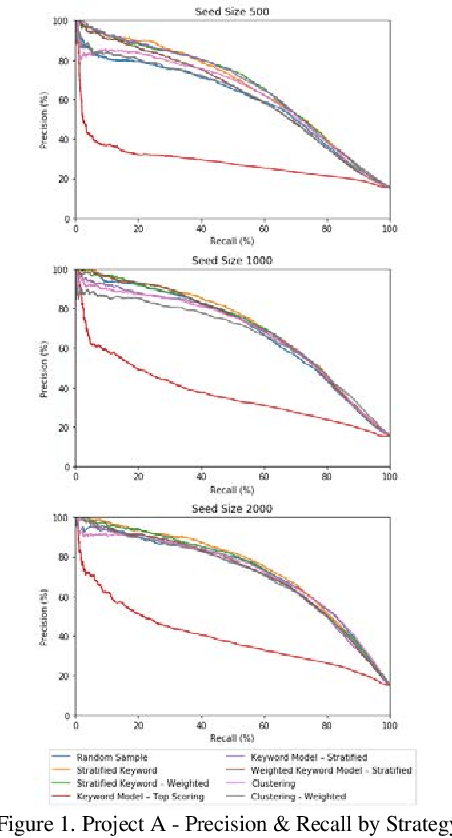
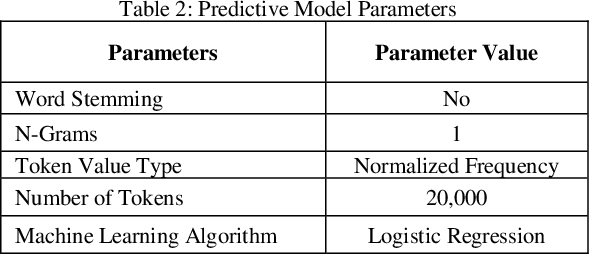
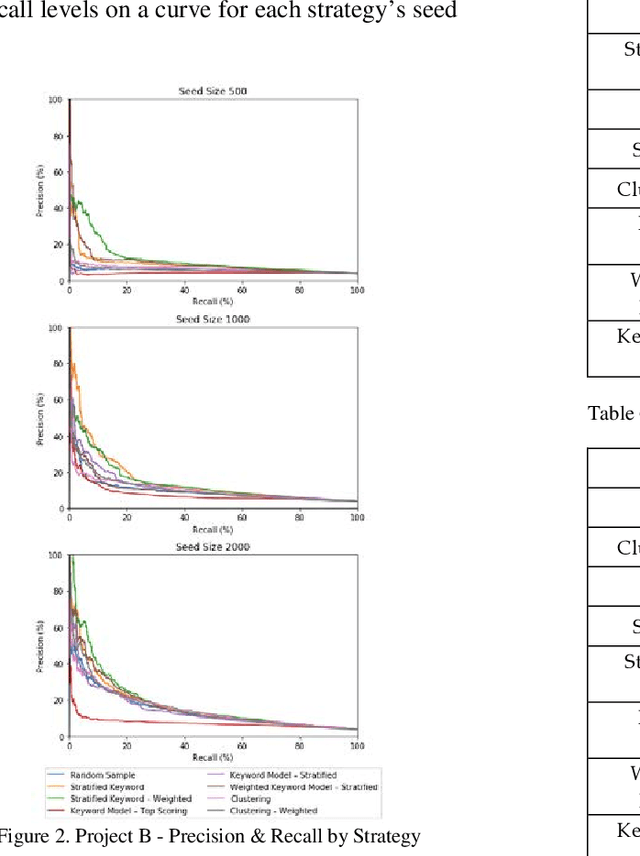
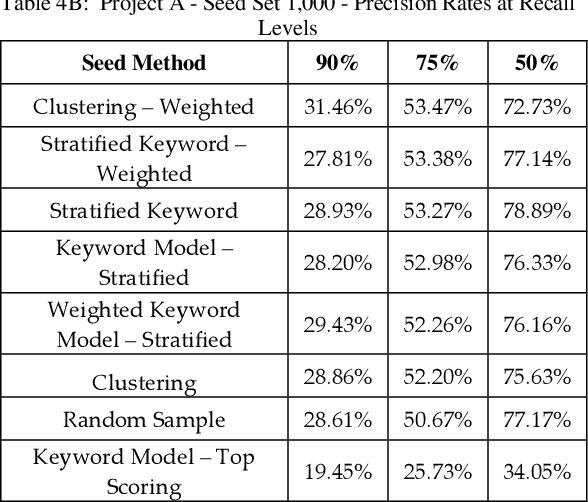
Training documents have a significant impact on the performance of predictive models in the legal domain. Yet, there is limited research that explores the effectiveness of the training document selection strategy - in particular, the strategy used to select the seed set, or the set of documents an attorney reviews first to establish an initial model. Since there is limited research on this important component of predictive coding, the authors of this paper set out to identify strategies that consistently perform well. Our research demonstrated that the seed set selection strategy can have a significant impact on the precision of a predictive model. Enabling attorneys with the results of this study will allow them to initiate the most effective predictive modeling process to comb through the terabytes of data typically present in modern litigation. This study used documents from four actual legal cases to evaluate eight different seed set selection strategies. Attorneys can use the results contained within this paper to enhance their approach to predictive coding.