 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Seed Set Selection Approaches and Active Learning Strategies in Predictive Coding
Paper and Code
Jun 11, 2019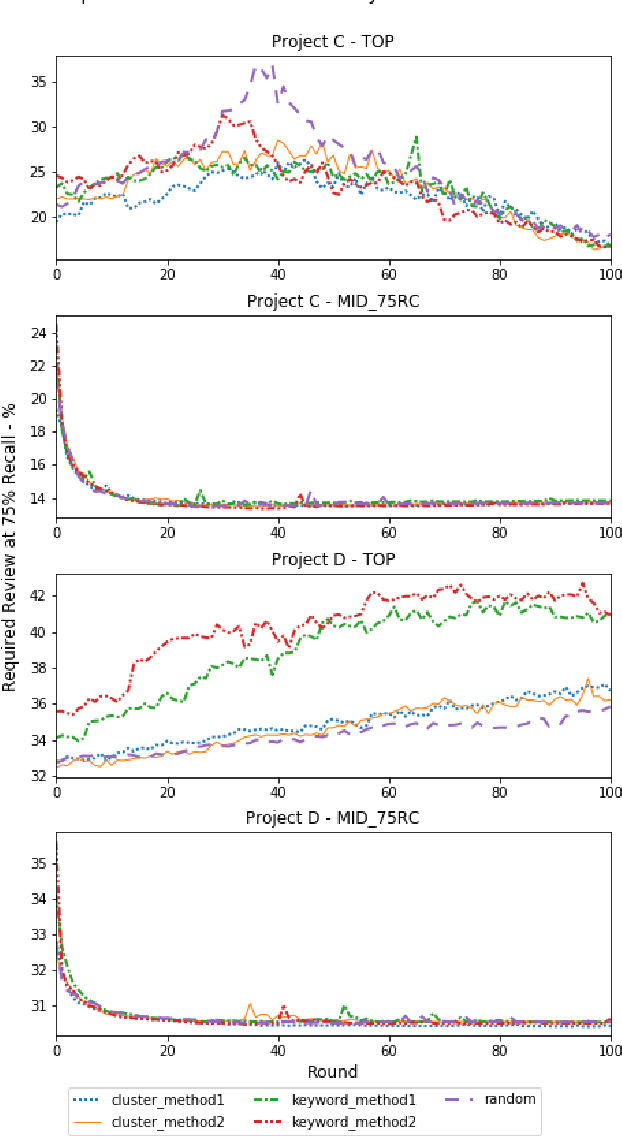
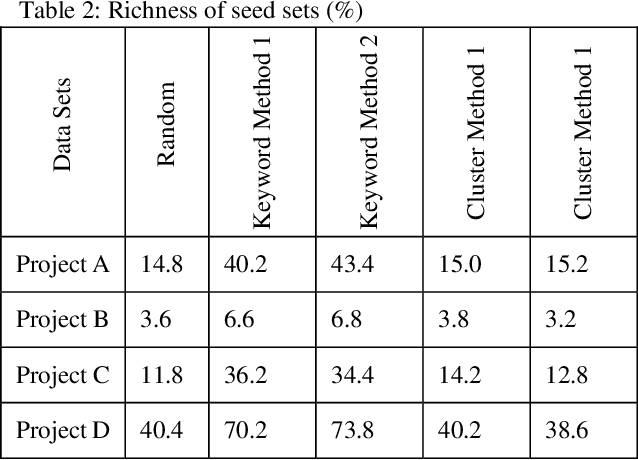
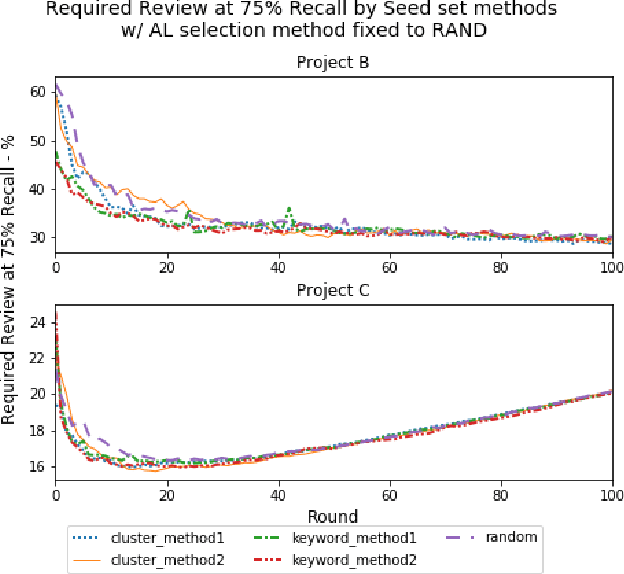
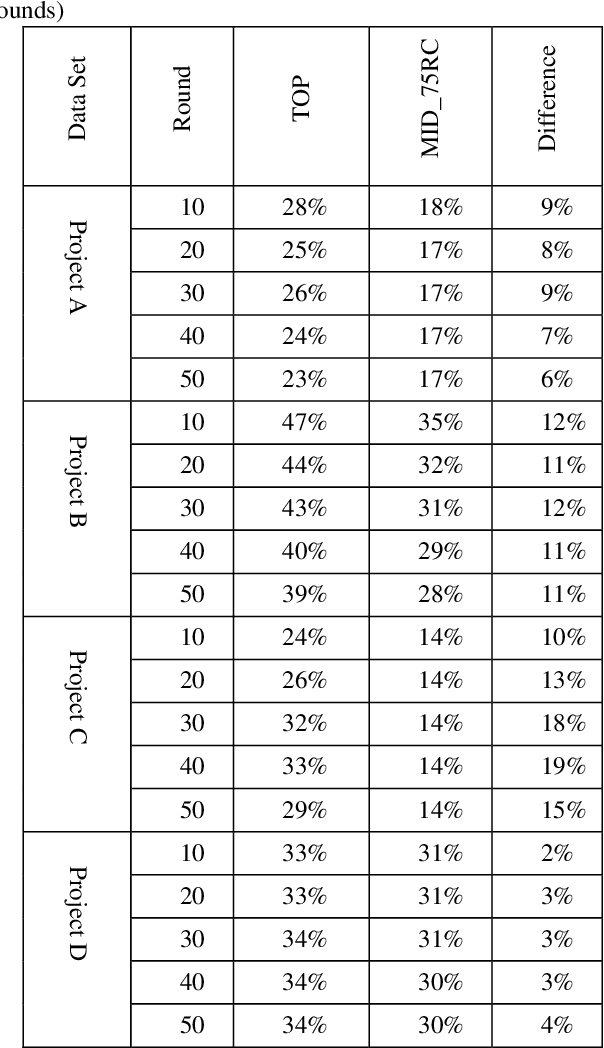
Active learning is a popular methodology in text classification - known in the legal domain as "predictive coding" or "Technology Assisted Review" or "TAR" - due to its potential to minimize the required review effort to build effective classifiers. In this study, we use extensive experimentation to examine the impact of popular seed set selection strategies in active learning, within a predictive coding exercise, and evaluate different active learning strategies against well-researched continuous active learning strategies for the purpose of determining efficient training methods for classifying large populations quickly and precisely. We study how random sampling, keyword models and clustering based seed set selection strategies combined together with top-ranked, uncertain, random, recall inspired, and hybrid active learning document selection strategies affect the performance of active learning for predictive coding. We use the percentage of documents requiring review to reach 75% recall as the "benchmark" metric to evaluate and compare our approaches. In most cases we find that seed set selection methods have a minor impact, though they do show significant impact in lower richness data sets or when choosing a top-ranked active learning selection strategy. Our results also show that active learning selection strategies implementing uncertainty, random, or 75% recall selection strategies has the potential to reach the optimum active learning round much earlier than the popular continuous active learning approach (top-ranked selection). The results of our research shed light on the impact of active learning seed set selection strategies and also the effectiveness of the selection strategies for the following learning rounds. Legal practitioners can use the results of this study to enhance the efficiency, precision, and simplicity of their predictive coding process.