 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Explainable Text Classification in Legal Document Review
Paper and Code
Dec 19, 2019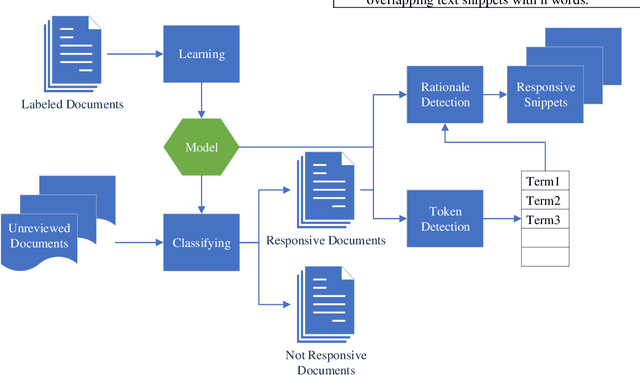
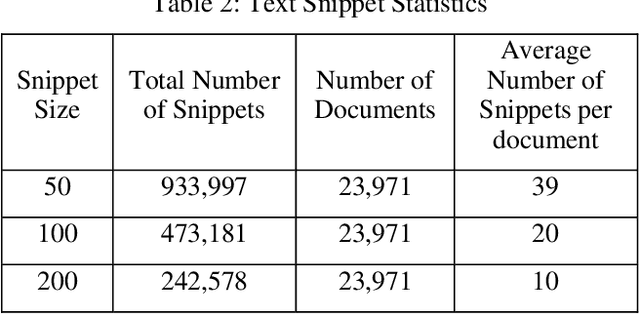
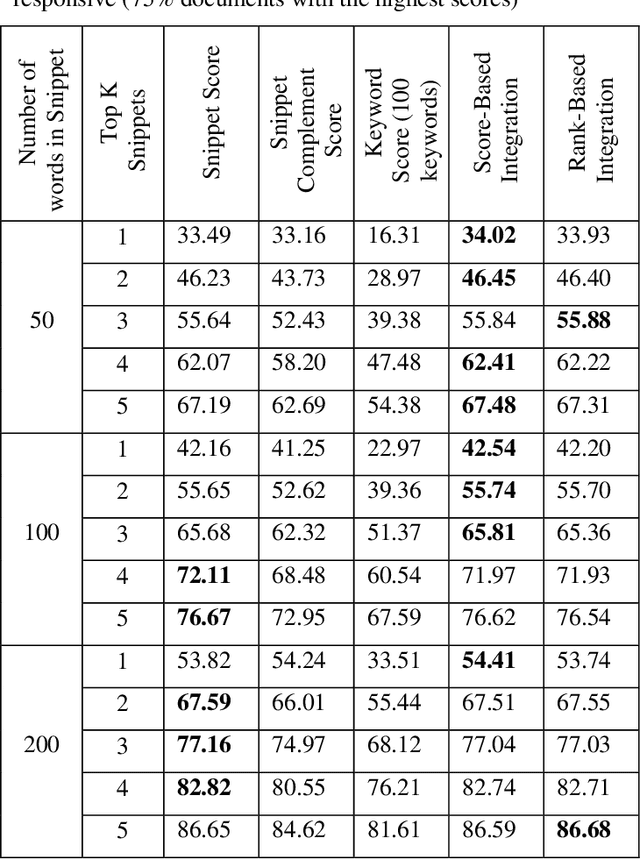
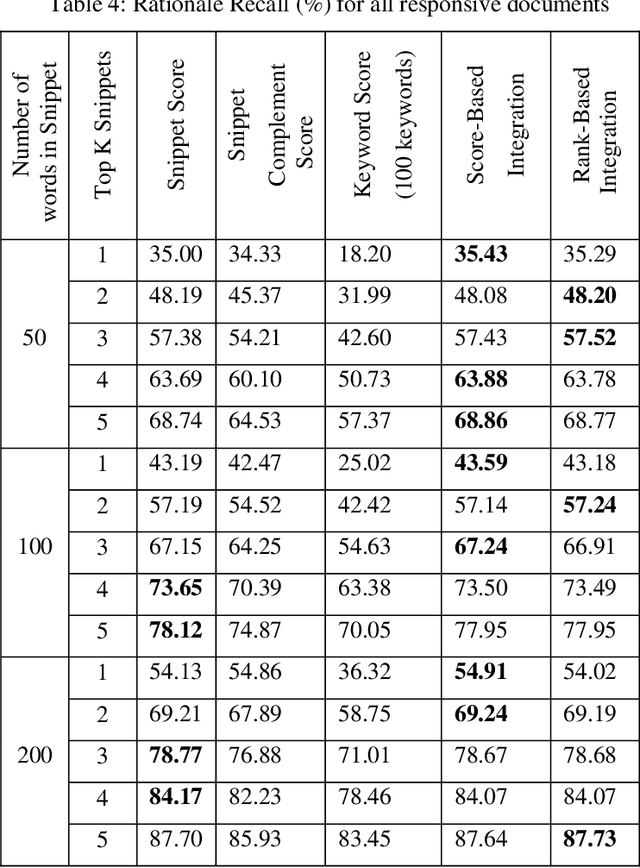
Companies regularly spend millions of dollars producing electronically-stored documents in legal matters. Recently, parties on both sides of the 'legal aisle' are accepting the use of machine learning techniques like text classification to cull massive volumes of data and to identify responsive documents for use in these matters. While text classification is regularly used to reduce the discovery costs in legal matters, it also faces a peculiar perception challenge: amongst lawyers, this technology is sometimes looked upon as a "black box", little information provided for attorneys to understand why documents are classified as responsive. In recent years, a group of AI and ML researchers have been actively researching Explainable AI, in which actions or decisions are human understandable. In legal document review scenarios, a document can be identified as responsive, if one or more of its text snippets are deemed responsive. In these scenarios, if text classification can be used to locate these snippets, then attorneys could easily evaluate the model's classification decision. When deployed with defined and explainable results, text classification can drastically enhance overall quality and speed of the review process by reducing the review time. Moreover, explainable predictive coding provides lawyers with greater confidence in the results of that supervised learning task. This paper describes a framework for explainable text classification as a valuable tool in legal services: for enhancing the quality and efficiency of legal document review and for assisting in locating responsive snippets within responsive documents. This framework has been implemented in our legal analytics product, which has been used in hundreds of legal matters. We also report our experimental results using the data from an actual legal matter that used this type of document review.