 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenGF: An Ultra-Large-Scale Ground Filtering Dataset Built Upon Open ALS Point Clouds Around the World
Jan 24, 2021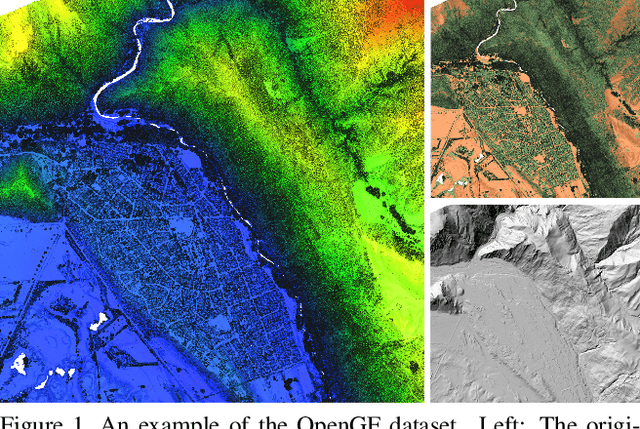
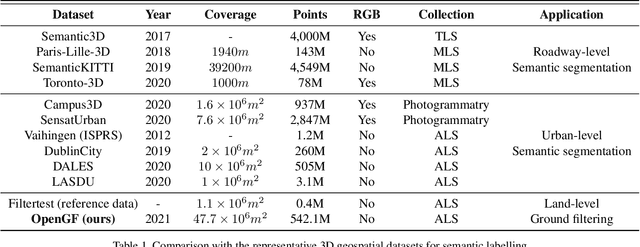


Ground filtering has remained a widely studied but incompletely resolved bottleneck for decades in the automatic generation of high-precision digital elevation model, due to the dramatic changes of topography and the complex structures of objects. The recent breakthrough of supervised deep learning algorithms in 3D scene understanding brings new solutions for better solving such problems. However, there are few large-scale and scene-rich public datasets dedicated to ground extraction, which considerably limits the development of effective deep-learning-based ground filtering methods. To this end, we present OpenGF, first Ultra-Large-Scale Ground Filtering dataset covering over 47 $km^2$ of 9 different typical terrain scenes built upon open ALS point clouds of 4 different countries around the world. OpenGF contains more than half a billion finely labeled ground and non-ground points, thousands of times the number of labeled points than the de facto standard ISPRS filtertest dataset. We extensively evaluate the performance of state-of-the-art rule-based algorithms and 3D semantic segmentation networks on our dataset and provide a comprehensive analysis. The results have confirmed the capability of OpenGF to train deep learning models effectively. This dataset will be released at https://github.com/Nathan-UW/OpenGF to promote more advancing research for ground filtering and large-scale 3D geographic environment understanding.
Toronto-3D: A Large-scale Mobile LiDAR Dataset for Semantic Segmentation of Urban Roadways
Apr 16, 2020
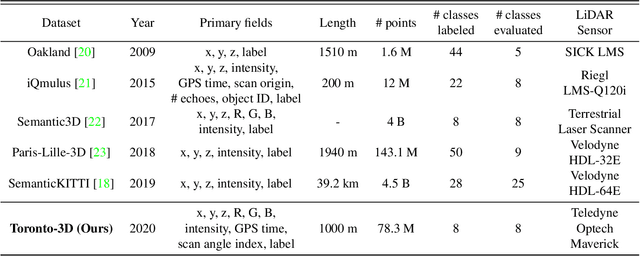
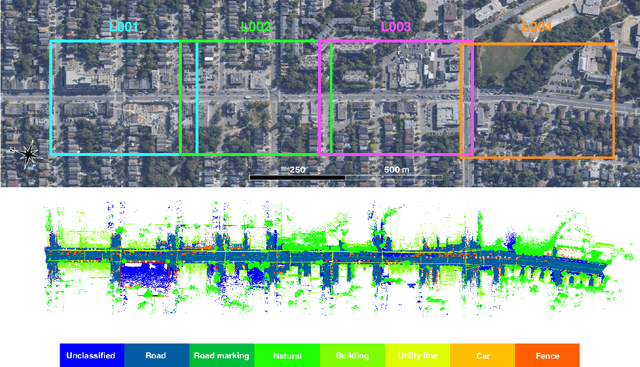

Semantic segmentation of large-scale outdoor point clouds is essential for urban scene understanding in various applications, especially autonomous driving and urban high-definition (HD) mapping. With rapid developments of mobile laser scanning (MLS) systems, massive point clouds are available for scene understanding, but publicly accessible large-scale labeled datasets, which are essential for developing learning-based methods, are still limited. This paper introduces Toronto-3D, a large-scale urban outdoor point cloud dataset acquired by a MLS system in Toronto, Canada for semantic segmentation. This dataset covers approximately 1 km of point clouds and consists of about 78.3 million points with 8 labeled object classes. Baseline experiments for semantic segmentation were conducted and the results confirmed the capability of this dataset to train deep learning models effectively. Toronto-3D is released to encourage new research, and the labels will be improved and updated with feedback from the research community.