 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe European Language Technology Landscape in 2020: Language-Centric and Human-Centric AI for Cross-Cultural Communication in Multilingual Europe
Mar 30, 2020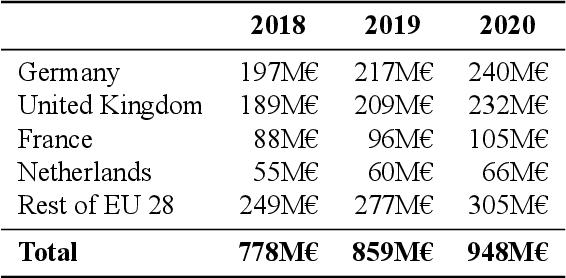
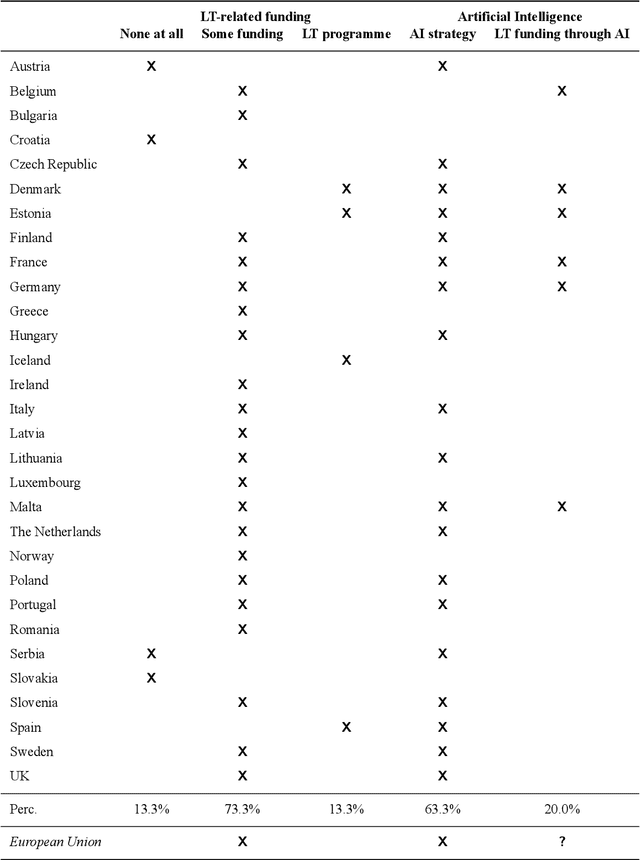
Multilingualism is a cultural cornerstone of Europe and firmly anchored in the European treaties including full language equality. However, language barriers impacting business, cross-lingual and cross-cultural communication are still omnipresent. Language Technologies (LTs) are a powerful means to break down these barriers. While the last decade has seen various initiatives that created a multitude of approaches and technologies tailored to Europe's specific needs, there is still an immense level of fragmentation. At the same time, AI has become an increasingly important concept in the European Information and Communication Technology area. For a few years now, AI, including many opportunities, synergies but also misconceptions, has been overshadowing every other topic. We present an overview of the European LT landscape, describing funding programmes, activities, actions and challenges in the different countries with regard to LT, including the current state of play in industry and the LT market. We present a brief overview of the main LT-related activities on the EU level in the last ten years and develop strategic guidance with regard to four key dimensions.
A Maturity Model for Public Administration as Open Translation Data Providers
Jul 07, 2016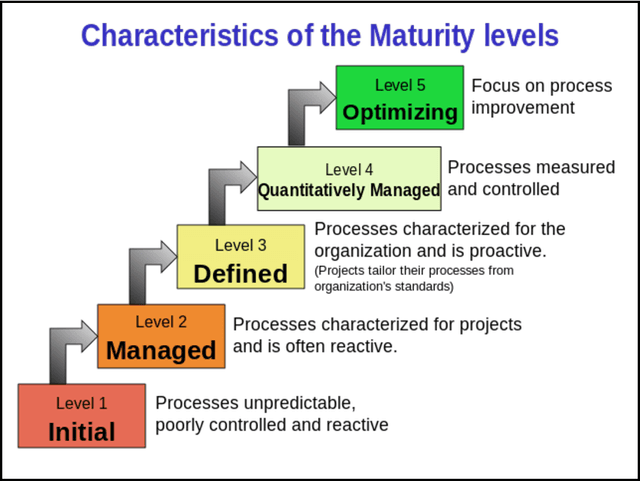
Any public administration that produces translation data can be a provider of useful reusable data to meet its own translation needs and the ones of other public organizations and private companies that work with texts of the same domain. These data can also be crucial to produce domain-tuned Machine Translation systems. The organization's management of the translation process, the characteristics of the archives of the generated resources and of the infrastructure available to support them determine the efficiency and the effectiveness with which the materials produced can be converted into reusable data. However, it is of utmost importance that the organizations themselves first become aware of the goods they are producing and, second, adapt their internal processes to become optimal providers. In this article, we propose a Maturity Model to help these organizations to achieve it by identifying the different stages of the management of translation data that determine the path to the aforementioned goal.
Using qualia information to identify lexical semantic classes in an unsupervised clustering task
Mar 11, 2013
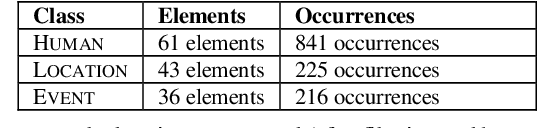

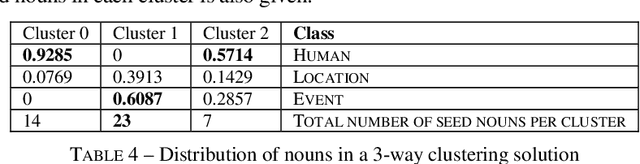
Acquiring lexical information is a complex problem, typically approached by relying on a number of contexts to contribute information for classification. One of the first issues to address in this domain is the determination of such contexts. The work presented here proposes the use of automatically obtained FORMAL role descriptors as features used to draw nouns from the same lexical semantic class together in an unsupervised clustering task. We have dealt with three lexical semantic classes (HUMAN, LOCATION and EVENT) in English. The results obtained show that it is possible to discriminate between elements from different lexical semantic classes using only FORMAL role information, hence validating our initial hypothesis. Also, iterating our method accurately accounts for fine-grained distinctions within lexical classes, namely distinctions involving ambiguous expressions. Moreover, a filtering and bootstrapping strategy employed in extracting FORMAL role descriptors proved to minimize effects of sparse data and noise in our task.
* 10 pages, 5 tables. Also available in UPF institutional repository (http://hdl.handle.net/10230/20383)
Automatic Detection of Non-deverbal Event Nouns for Quick Lexicon Production
Mar 11, 2013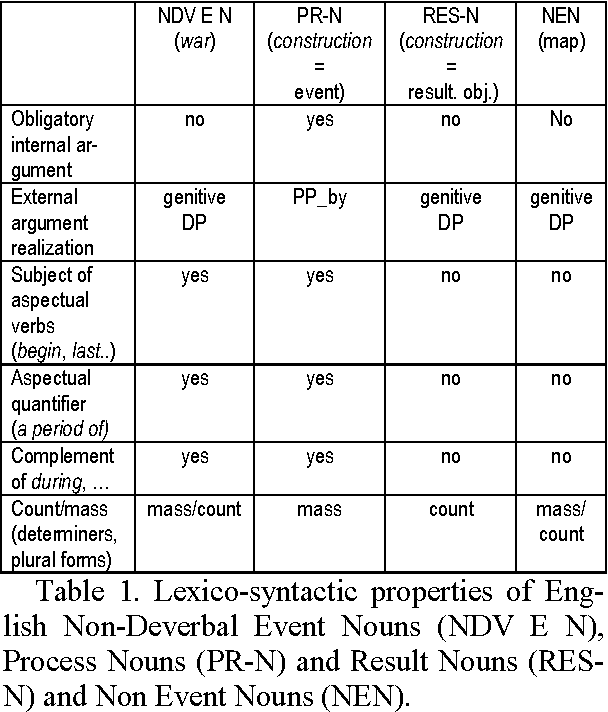
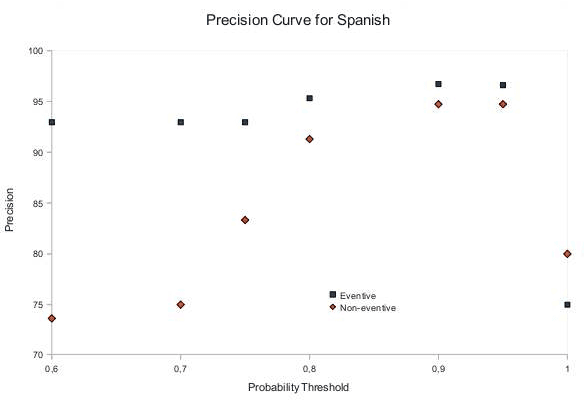

In this work we present the results of our experimental work on the develop-ment of lexical class-based lexica by automatic means. The objective is to as-sess the use of linguistic lexical-class based information as a feature selection methodology for the use of classifiers in quick lexical development. The results show that the approach can help in re-ducing the human effort required in the development of language resources sig-nificantly.
* 7 pages, 2 figures. Also available in UPF institutional repository (http://hdl.handle.net/10230/20325)
Mining and Exploiting Domain-Specific Corpora in the PANACEA Platform
Mar 08, 2013The objective of the PANACEA ICT-2007.2.2 EU project is to build a platform that automates the stages involved in the acquisition, production, updating and maintenance of the large language resources required by, among others, MT systems. The development of a Corpus Acquisition Component (CAC) for extracting monolingual and bilingual data from the web is one of the most innovative building blocks of PANACEA. The CAC, which is the first stage in the PANACEA pipeline for building Language Resources, adopts an efficient and distributed methodology to crawl for web documents with rich textual content in specific languages and predefined domains. The CAC includes modules that can acquire parallel data from sites with in-domain content available in more than one language. In order to extrinsically evaluate the CAC methodology, we have conducted several experiments that used crawled parallel corpora for the identification and extraction of parallel sentences using sentence alignment. The corpora were then successfully used for domain adaptation of Machine Translation Systems.
* 3 pages. Also available in UPF institutional repository (http://hdl.handle.net/10230/20416)
A Classification of Adjectives for Polarity Lexicons Enhancement
Mar 08, 2013
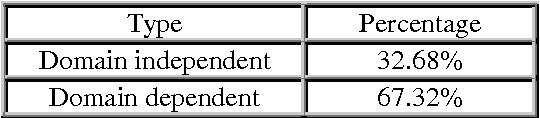
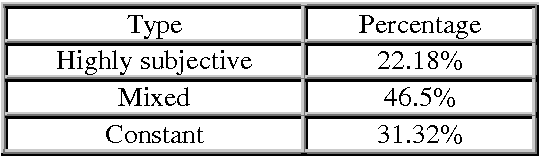
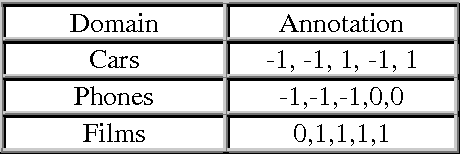
Subjective language detection is one of the most important challenges in Sentiment Analysis. Because of the weight and frequency in opinionated texts, adjectives are considered a key piece in the opinion extraction process. These subjective units are more and more frequently collected in polarity lexicons in which they appear annotated with their prior polarity. However, at the moment, any polarity lexicon takes into account prior polarity variations across domains. This paper proves that a majority of adjectives change their prior polarity value depending on the domain. We propose a distinction between domain dependent and domain independent adjectives. Moreover, our analysis led us to propose a further classification related to subjectivity degree: constant, mixed and highly subjective adjectives. Following this classification, polarity values will be a better support for Sentiment Analysis.
* 5 pages, 7 tables. Also available in UPF institutional repository (http://hdl.handle.net/10230/20419)
Automatic lexical semantic classification of nouns
Mar 08, 2013
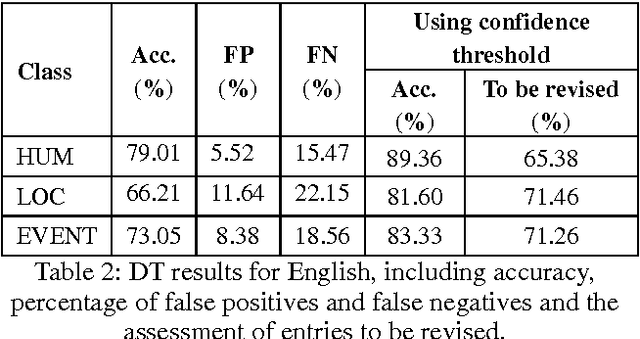
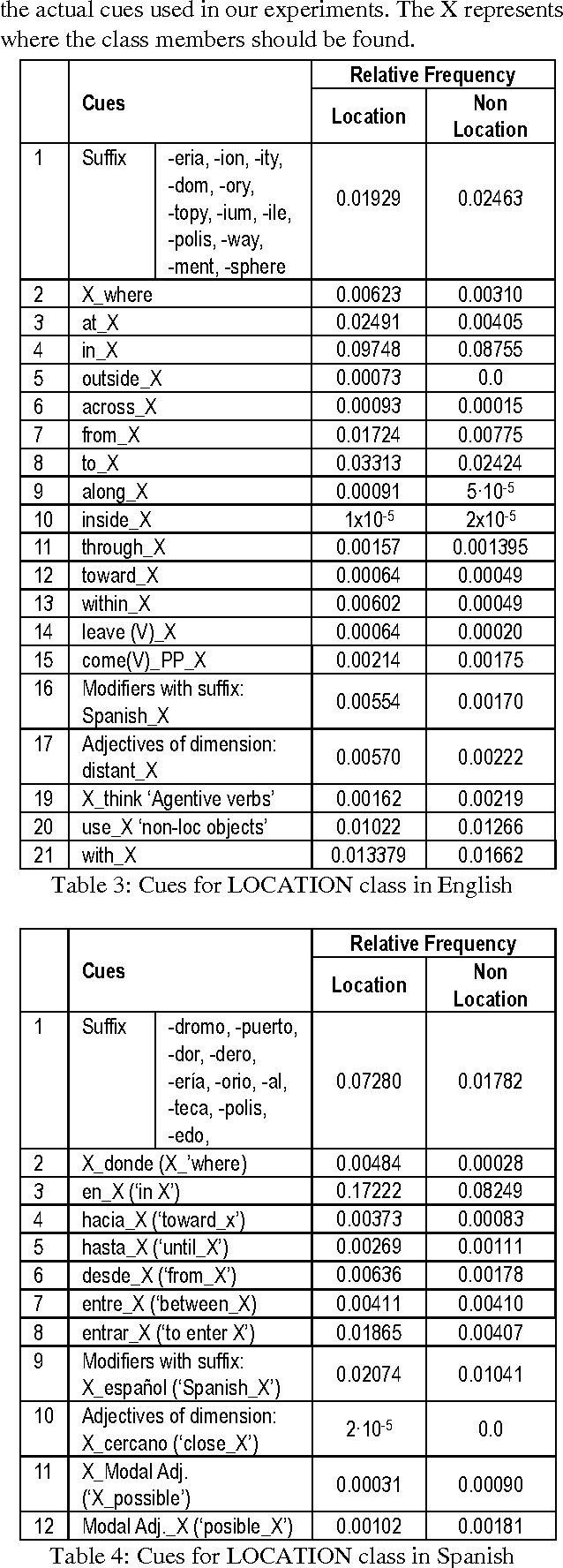
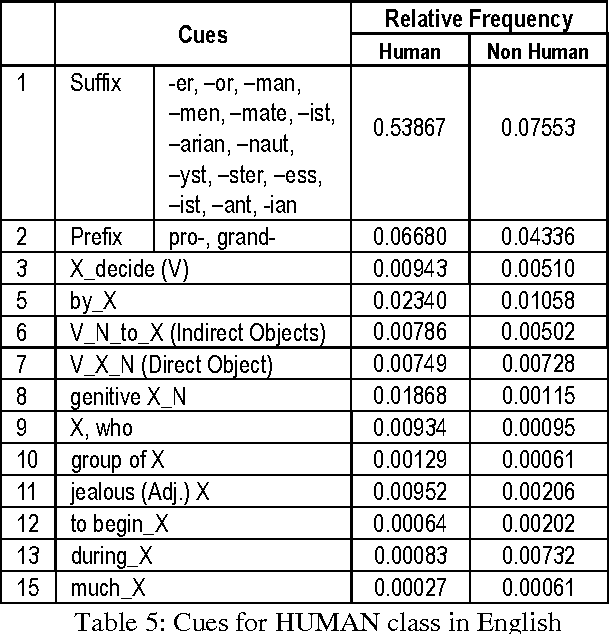
The work we present here addresses cue-based noun classification in English and Spanish. Its main objective is to automatically acquire lexical semantic information by classifying nouns into previously known noun lexical classes. This is achieved by using particular aspects of linguistic contexts as cues that identify a specific lexical class. Here we concentrate on the task of identifying such cues and the theoretical background that allows for an assessment of the complexity of the task. The results show that, despite of the a-priori complexity of the task, cue-based classification is a useful tool in the automatic acquisition of lexical semantic classes.
* 8 pages, 8 tables. Also available in UPF institutional repository (http://hdl.handle.net/10230/20420)
Towards the Fully Automatic Merging of Lexical Resources: A Step Forward
Mar 08, 2013
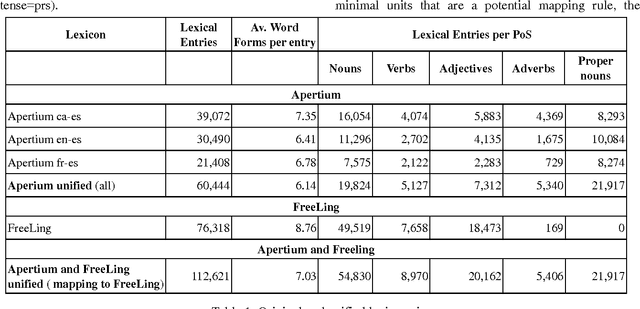
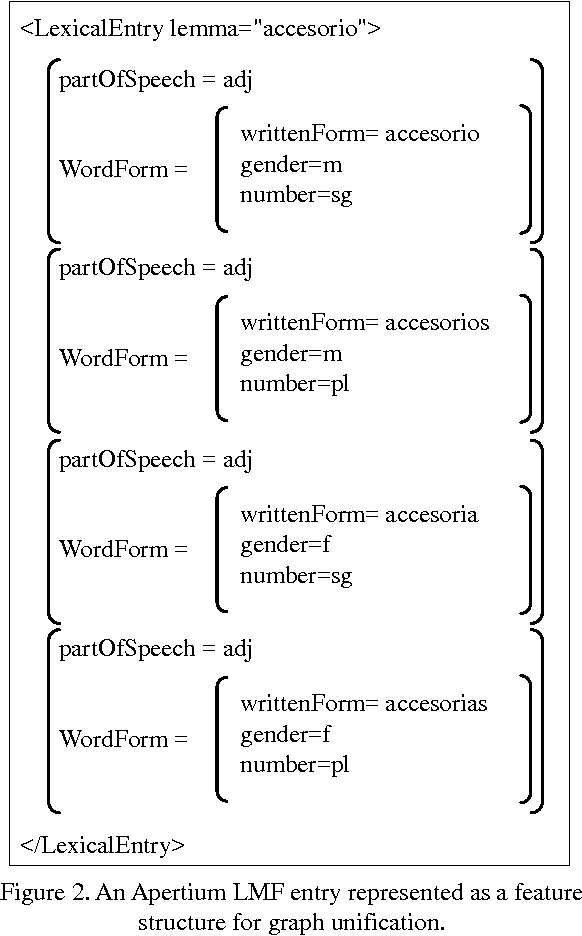

This article reports on the results of the research done towards the fully automatically merging of lexical resources. Our main goal is to show the generality of the proposed approach, which have been previously applied to merge Spanish Subcategorization Frames lexica. In this work we extend and apply the same technique to perform the merging of morphosyntactic lexica encoded in LMF. The experiments showed that the technique is general enough to obtain good results in these two different tasks which is an important step towards performing the merging of lexical resources fully automatically.
* 7 pages, 1 figure, 5 tables. Also available in UPF institutional repository (http://hdl.handle.net/10230/20417)