 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced artificial intelligence-based diagnosis using CBCT with internal denoising: Clinical validation for discrimination of fungal ball, sinusitis, and normal cases in the maxillary sinus
Nov 29, 2022



The cone-beam computed tomography (CBCT) provides 3D volumetric imaging of a target with low radiation dose and cost compared with conventional computed tomography, and it is widely used in the detection of paranasal sinus disease. However, it lacks the sensitivity to detect soft tissue lesions owing to reconstruction constraints. Consequently, only physicians with expertise in CBCT reading can distinguish between inherent artifacts or noise and diseases, restricting the use of this imaging modality. The development of artificial intelligence (AI)-based computer-aided diagnosis methods for CBCT to overcome the shortage of experienced physicians has attracted substantial attention. However, advanced AI-based diagnosis addressing intrinsic noise in CBCT has not been devised, discouraging the practical use of AI solutions for CBCT. To address this issue, we propose an AI-based computer-aided diagnosis method using CBCT with a denoising module. This module is implemented before diagnosis to reconstruct the internal ground-truth full-dose scan corresponding to an input CBCT image and thereby improve the diagnostic performance. The external validation results for the unified diagnosis of sinus fungal ball, chronic rhinosinusitis, and normal cases show that the proposed method improves the micro-, macro-average AUC, and accuracy by 7.4, 5.6, and 9.6% (from 86.2, 87.0, and 73.4 to 93.6, 92.6, and 83.0%), respectively, compared with a baseline while improving human diagnosis accuracy by 11% (from 71.7 to 83.0%), demonstrating technical differentiation and clinical effectiveness. This pioneering study on AI-based diagnosis using CBCT indicates denoising can improve diagnostic performance and reader interpretability in images from the sinonasal area, thereby providing a new approach and direction to radiographic image reconstruction regarding the development of AI-based diagnostic solutions.
Comparative Validation of AI and non-AI Methods in MRI Volumetry to Diagnose Parkinsonian Syndromes
Jul 23, 2022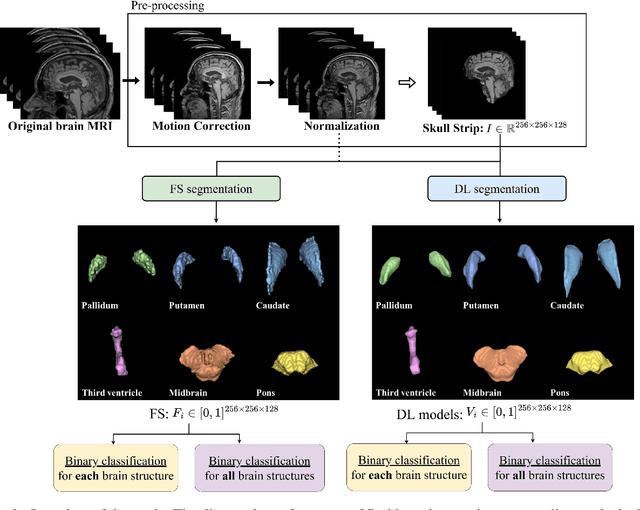

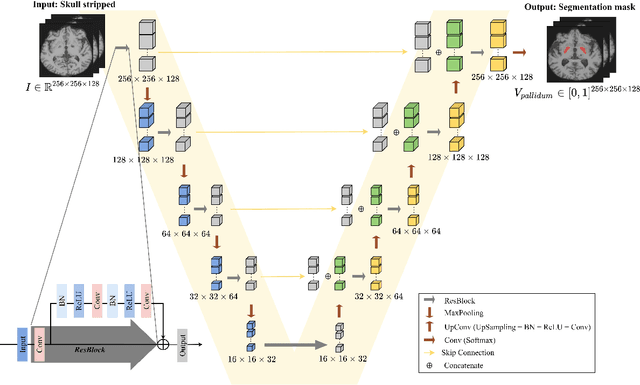
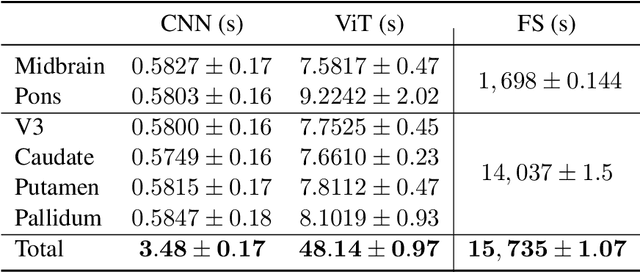
Automated segmentation and volumetry of brain magnetic resonance imaging (MRI) scans are essential for the diagnosis of Parkinson's disease (PD) and Parkinson's plus syndromes (P-plus). To enhance the diagnostic performance, we adopt deep learning (DL) models in brain segmentation and compared their performance with the gold-standard non-DL method. We collected brain MRI scans of healthy controls (n=105) and patients with PD (n=105), multiple systemic atrophy (n=132), and progressive supranuclear palsy (n=69) at Samsung Medical Center from January 2017 to December 2020. Using the gold-standard non-DL model, FreeSurfer (FS), we segmented six brain structures: midbrain, pons, caudate, putamen, pallidum, and third ventricle, and considered them as annotating data for DL models, the representative V-Net and UNETR. The Dice scores and area under the curve (AUC) for differentiating normal, PD, and P-plus cases were calculated. The segmentation times of V-Net and UNETR for the six brain structures per patient were 3.48 +- 0.17 and 48.14 +- 0.97 s, respectively, being at least 300 times faster than FS (15,735 +- 1.07 s). Dice scores of both DL models were sufficiently high (>0.85), and their AUCs for disease classification were superior to that of FS. For classification of normal vs. P-plus and PD vs. multiple systemic atrophy (cerebellar type), the DL models and FS showed AUCs above 0.8. DL significantly reduces the analysis time without compromising the performance of brain segmentation and differential diagnosis. Our findings may contribute to the adoption of DL brain MRI segmentation in clinical settings and advance brain research.
Improved Generative Model for Weakly Supervised Chest Anomaly Localization via Pseudo-paired Registration with Bilaterally Symmetrical Data Augmentation
Jul 21, 2022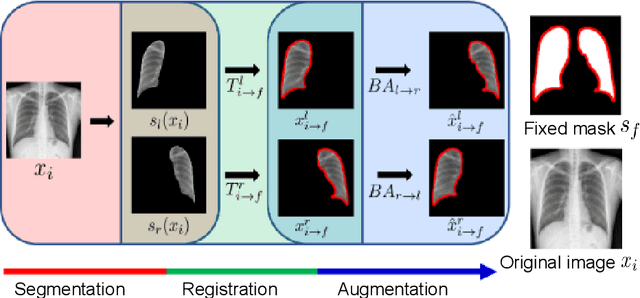

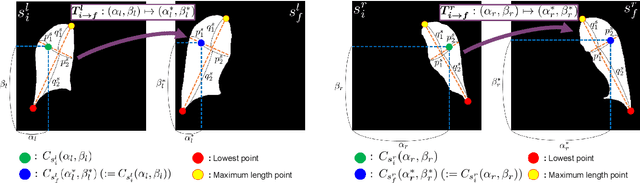
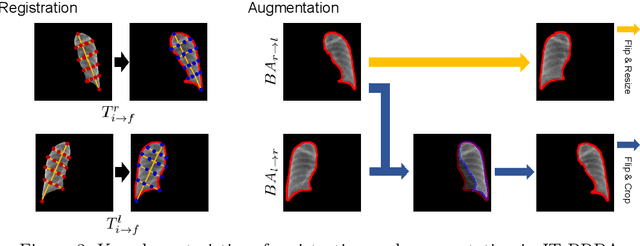
Image translation based on a generative adversarial network (GAN-IT) is a promising method for precise localization of abnormal regions in chest X-ray images (AL-CXR). However, heterogeneous unpaired datasets undermine existing methods to extract key features and distinguish normal from abnormal cases, resulting in inaccurate and unstable AL-CXR. To address this problem, we propose an improved two-stage GAN-IT involving registration and data augmentation. For the first stage, we introduce an invertible deep-learning-based registration technique that virtually and reasonably converts unpaired data into paired data for learning registration maps. This novel approach achieves high registration performance. For the second stage, we apply data augmentation to diversify anomaly locations by swapping the left and right lung regions on the uniform registered frames, further improving the performance by alleviating imbalance in data distribution showing left and right lung lesions. Our method is intended for application to existing GAN-IT models, allowing existing architecture to benefit from key features for translation. By showing that the AL-CXR performance is uniformly improved when applying the proposed method, we believe that GAN-IT for AL-CXR can be deployed in clinical environments, even if learning data are scarce.
AI-based computer-aided diagnostic system of chest digital tomography synthesis: Demonstrating comparative advantage with X-ray-based AI systems
Jun 18, 2022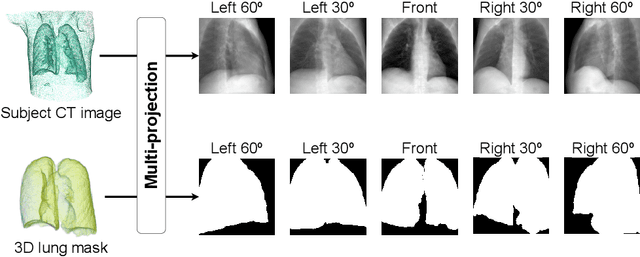
Compared with chest X-ray (CXR) imaging, which is a single image projected from the front of the patient, chest digital tomosynthesis (CDTS) imaging can be more advantageous for lung lesion detection because it acquires multiple images projected from multiple angles of the patient. Various clinical comparative analysis and verification studies have been reported to demonstrate this, but there were no artificial intelligence (AI)-based comparative analysis studies. Existing AI-based computer-aided detection (CAD) systems for lung lesion diagnosis have been developed mainly based on CXR images; however, CAD-based on CDTS, which uses multi-angle images of patients in various directions, has not been proposed and verified for its usefulness compared to CXR-based counterparts. This study develops/tests a CDTS-based AI CAD system to detect lung lesions to demonstrate performance improvements compared to CXR-based AI CAD. We used multiple projection images as input for the CDTS-based AI model and a single-projection image as input for the CXR-based AI model to fairly compare and evaluate the performance between models. The proposed CDTS-based AI CAD system yielded sensitivities of 0.782 and 0.785 and accuracies of 0.895 and 0.837 for the performance of detecting tuberculosis and pneumonia, respectively, against normal subjects. These results show higher performance than sensitivities of 0.728 and 0.698 and accuracies of 0.874 and 0.826 for detecting tuberculosis and pneumonia through the CXR-based AI CAD, which only uses a single projection image in the frontal direction. We found that CDTS-based AI CAD improved the sensitivity of tuberculosis and pneumonia by 5.4% and 8.7% respectively, compared to CXR-based AI CAD without loss of accuracy. Therefore, we comparatively prove that CDTS-based AI CAD technology can improve performance more than CXR, enhancing the clinical applicability of CDTS.
3D unsupervised anomaly detection and localization through virtual multi-view projection and reconstruction: Clinical validation on low-dose chest computed tomography
Jun 18, 2022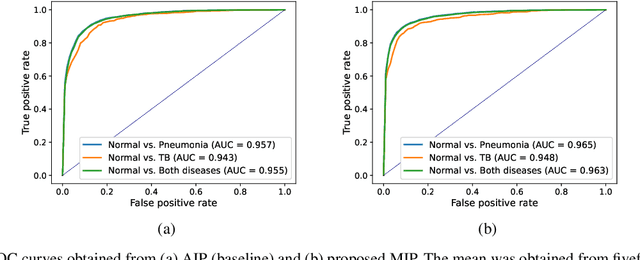
Computer-aided diagnosis for low-dose computed tomography (CT) based on deep learning has recently attracted attention as a first-line automatic testing tool because of its high accuracy and low radiation exposure. However, existing methods rely on supervised learning, imposing an additional burden to doctors for collecting disease data or annotating spatial labels for network training, consequently hindering their implementation. We propose a method based on a deep neural network for computer-aided diagnosis called virtual multi-view projection and reconstruction for unsupervised anomaly detection. Presumably, this is the first method that only requires data from healthy patients for training to identify three-dimensional (3D) regions containing any anomalies. The method has three key components. Unlike existing computer-aided diagnosis tools that use conventional CT slices as the network input, our method 1) improves the recognition of 3D lung structures by virtually projecting an extracted 3D lung region to obtain two-dimensional (2D) images from diverse views to serve as network inputs, 2) accommodates the input diversity gain for accurate anomaly detection, and 3) achieves 3D anomaly/disease localization through a novel 3D map restoration method using multiple 2D anomaly maps. The proposed method based on unsupervised learning improves the patient-level anomaly detection by 10% (area under the curve, 0.959) compared with a gold standard based on supervised learning (area under the curve, 0.848), and it localizes the anomaly region with 93% accuracy, demonstrating its high performance.
Automated Precision Localization of Peripherally Inserted Central Catheter Tip through Model-Agnostic Multi-Stage Networks
Jun 14, 2022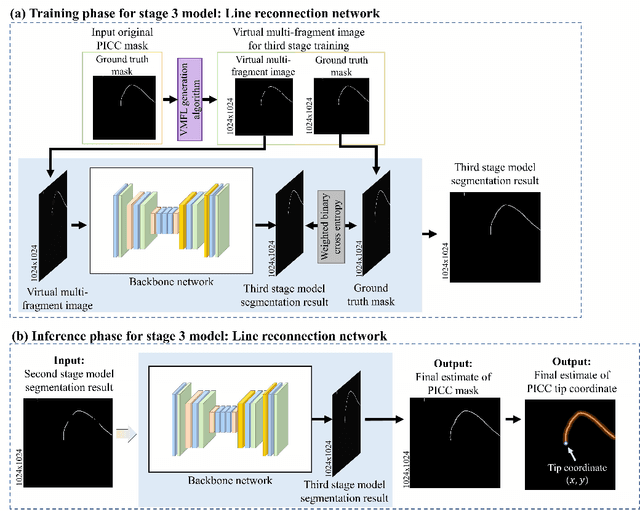

Peripherally inserted central catheters (PICCs) have been widely used as one of the representative central venous lines (CVCs) due to their long-term intravascular access with low infectivity. However, PICCs have a fatal drawback of a high frequency of tip mispositions, increasing the risk of puncture, embolism, and complications such as cardiac arrhythmias. To automatically and precisely detect it, various attempts have been made by using the latest deep learning (DL) technologies. However, even with these approaches, it is still practically difficult to determine the tip location because the multiple fragments phenomenon (MFP) occurs in the process of predicting and extracting the PICC line required before predicting the tip. This study aimed to develop a system generally applied to existing models and to restore the PICC line more exactly by removing the MFs of the model output, thereby precisely localizing the actual tip position for detecting its disposition. To achieve this, we proposed a multi-stage DL-based framework post-processing the PICC line extraction result of the existing technology. The performance was compared by each root mean squared error (RMSE) and MFP incidence rate according to whether or not MFCN is applied to five conventional models. In internal validation, when MFCN was applied to the existing single model, MFP was improved by an average of 45%. The RMSE was improved by over 63% from an average of 26.85mm (17.16 to 35.80mm) to 9.72mm (9.37 to 10.98mm). In external validation, when MFCN was applied, the MFP incidence rate decreased by an average of 32% and the RMSE decreased by an average of 65\%. Therefore, by applying the proposed MFCN, we observed the significant/consistent detection performance improvement of PICC tip location compared to the existing model.