 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Informed Uncertainty Enables Reliable AI-driven Design
Jan 26, 2026Inverse design is a central goal in much of science and engineering, including frequency-selective surfaces (FSS) that are critical to microelectronics for telecommunications and optical metamaterials. Traditional surrogate-assisted optimization methods using deep learning can accelerate the design process but do not usually incorporate uncertainty quantification, leading to poorer optimization performance due to erroneous predictions in data-sparse regions. Here, we introduce and validate a fundamentally different paradigm of Physics-Informed Uncertainty, where the degree to which a model's prediction violates fundamental physical laws serves as a computationally-cheap and effective proxy for predictive uncertainty. By integrating physics-informed uncertainty into a multi-fidelity uncertainty-aware optimization workflow to design complex frequency-selective surfaces within the 20 - 30 GHz range, we increase the success rate of finding performant solutions from less than 10% to over 50%, while simultaneously reducing computational cost by an order of magnitude compared to the sole use of a high-fidelity solver. These results highlight the necessity of incorporating uncertainty quantification in machine-learning-driven inverse design for high-dimensional problems, and establish physics-informed uncertainty as a viable alternative to quantifying uncertainty in surrogate models for physical systems, thereby setting the stage for autonomous scientific discovery systems that can efficiently and robustly explore and evaluate candidate designs.
Generalizable Neural Physics Solvers by Baldwinian Evolution
Dec 06, 2023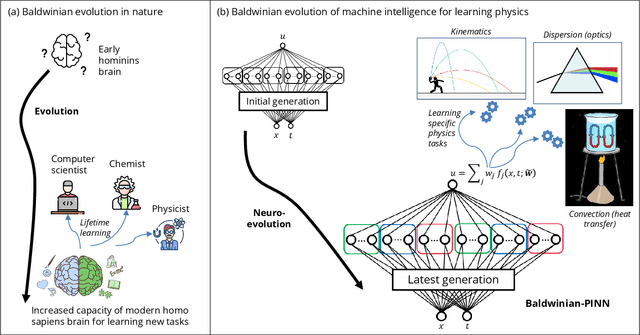
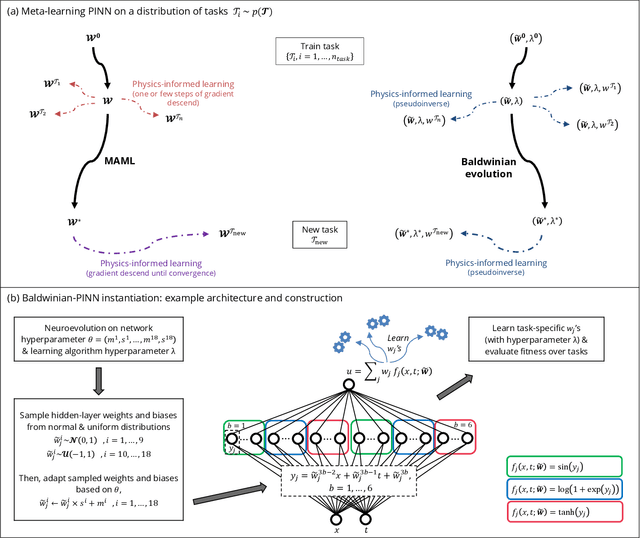
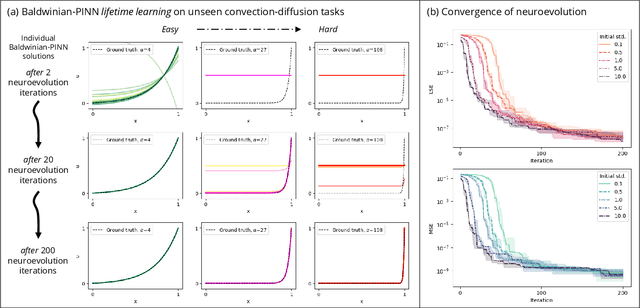

Physics-informed neural networks (PINNs) are at the forefront of scientific machine learning, making possible the creation of machine intelligence that is cognizant of physical laws and able to accurately simulate them. In this paper, the potential of discovering PINNs that generalize over an entire family of physics tasks is studied, for the first time, through a biological lens of the Baldwin effect. Drawing inspiration from the neurodevelopment of precocial species that have evolved to learn, predict and react quickly to their environment, we envision PINNs that are pre-wired with connection strengths inducing strong biases towards efficient learning of physics. To this end, evolutionary selection pressure (guided by proficiency over a family of tasks) is coupled with lifetime learning (to specialize on a smaller subset of those tasks) to produce PINNs that demonstrate fast and physics-compliant prediction capabilities across a range of empirically challenging problem instances. The Baldwinian approach achieves an order of magnitude improvement in prediction accuracy at a fraction of the computation cost compared to state-of-the-art results with PINNs meta-learned by gradient descent. This paper marks a leap forward in the meta-learning of PINNs as generalizable physics solvers.
LSA-PINN: Linear Boundary Connectivity Loss for Solving PDEs on Complex Geometry
Feb 03, 2023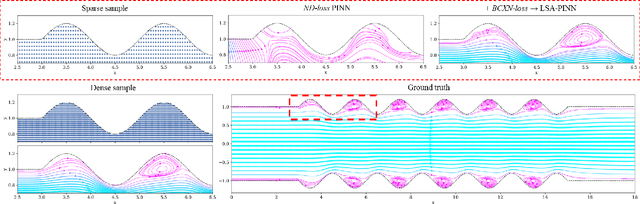
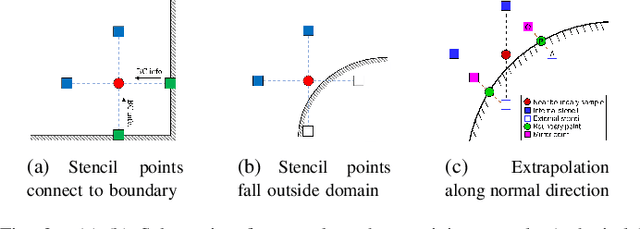
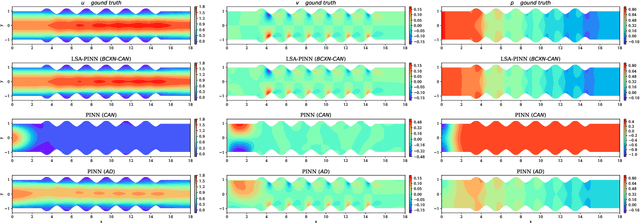
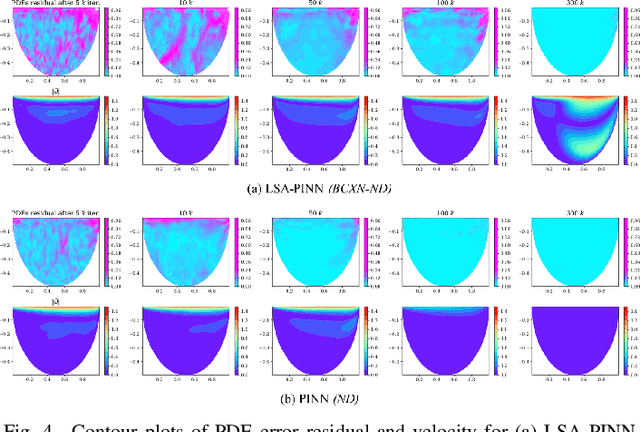
We present a novel loss formulation for efficient learning of complex dynamics from governing physics, typically described by partial differential equations (PDEs), using physics-informed neural networks (PINNs). In our experiments, existing versions of PINNs are seen to learn poorly in many problems, especially for complex geometries, as it becomes increasingly difficult to establish appropriate sampling strategy at the near boundary region. Overly dense sampling can adversely impede training convergence if the local gradient behaviors are too complex to be adequately modelled by PINNs. On the other hand, if the samples are too sparse, existing PINNs tend to overfit the near boundary region, leading to incorrect solution. To prevent such issues, we propose a new Boundary Connectivity (BCXN) loss function which provides linear local structure approximation (LSA) to the gradient behaviors at the boundary for PINN. Our BCXN-loss implicitly imposes local structure during training, thus facilitating fast physics-informed learning across entire problem domains with order of magnitude sparser training samples. This LSA-PINN method shows a few orders of magnitude smaller errors than existing methods in terms of the standard L2-norm metric, while using dramatically fewer training samples and iterations. Our proposed LSA-PINN does not pose any requirement on the differentiable property of the networks, and we demonstrate its benefits and ease of implementation on both multi-layer perceptron and convolutional neural network versions as commonly used in current PINN literature.
Graph Neural Network Based Surrogate Model of Physics Simulations for Geometry Design
Feb 01, 2023



Computational Intelligence (CI) techniques have shown great potential as a surrogate model of expensive physics simulation, with demonstrated ability to make fast predictions, albeit at the expense of accuracy in some cases. For many scientific and engineering problems involving geometrical design, it is desirable for the surrogate models to precisely describe the change in geometry and predict the consequences. In that context, we develop graph neural networks (GNNs) as fast surrogate models for physics simulation, which allow us to directly train the models on 2/3D geometry designs that are represented by an unstructured mesh or point cloud, without the need for any explicit or hand-crafted parameterization. We utilize an encoder-processor-decoder-type architecture which can flexibly make prediction at both node level and graph level. The performance of our proposed GNN-based surrogate model is demonstrated on 2 example applications: feature designs in the domain of additive engineering and airfoil design in the domain of aerodynamics. The models show good accuracy in their predictions on a separate set of test geometries after training, with almost instant prediction speeds, as compared to O(hour) for the high-fidelity simulations required otherwise.
CAN-PINN: A Fast Physics-Informed Neural Network Based on Coupled-Automatic-Numerical Differentiation Method
Oct 29, 2021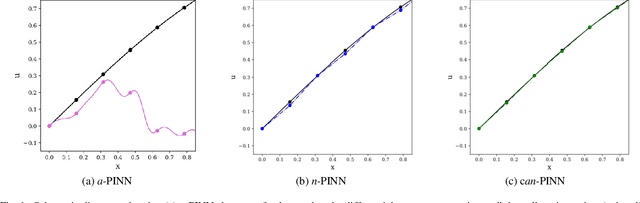
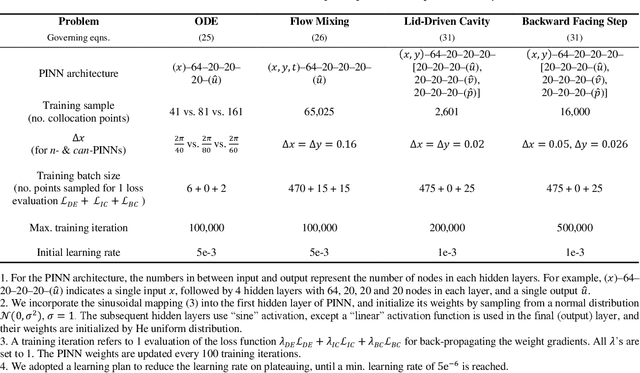
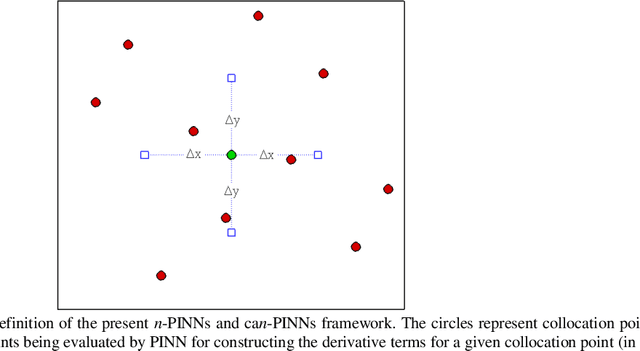
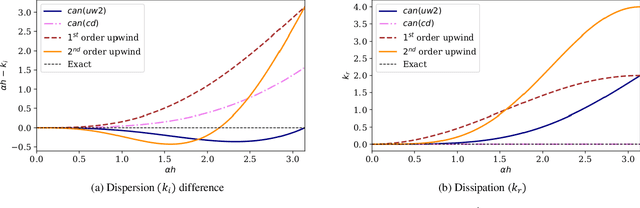
In this study, novel physics-informed neural network (PINN) methods for coupling neighboring support points and automatic differentiation (AD) through Taylor series expansion are proposed to allow efficient training with improved accuracy. The computation of differential operators required for PINNs loss evaluation at collocation points are conventionally obtained via AD. Although AD has the advantage of being able to compute the exact gradients at any point, such PINNs can only achieve high accuracies with large numbers of collocation points, otherwise they are prone to optimizing towards unphysical solution. To make PINN training fast, the dual ideas of using numerical differentiation (ND)-inspired method and coupling it with AD are employed to define the loss function. The ND-based formulation for training loss can strongly link neighboring collocation points to enable efficient training in sparse sample regimes, but its accuracy is restricted by the interpolation scheme. The proposed coupled-automatic-numerical differentiation framework, labeled as can-PINN, unifies the advantages of AD and ND, providing more robust and efficient training than AD-based PINNs, while further improving accuracy by up to 1-2 orders of magnitude relative to ND-based PINNs. For a proof-of-concept demonstration of this can-scheme to fluid dynamic problems, two numerical-inspired instantiations of can-PINN schemes for the convection and pressure gradient terms were derived to solve the incompressible Navier-Stokes (N-S) equations. The superior performance of can-PINNs is demonstrated on several challenging problems, including the flow mixing phenomena, lid driven flow in a cavity, and channel flow over a backward facing step. The results reveal that for challenging problems like these, can-PINNs can consistently achieve very good accuracy whereas conventional AD-based PINNs fail.
Improved Surrogate Modeling of Fluid Dynamics with Physics-Informed Neural Networks
May 05, 2021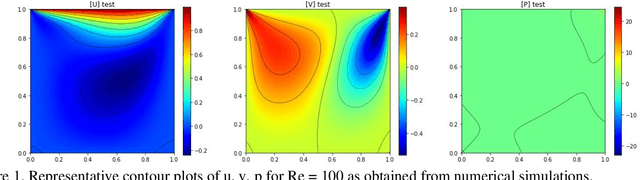
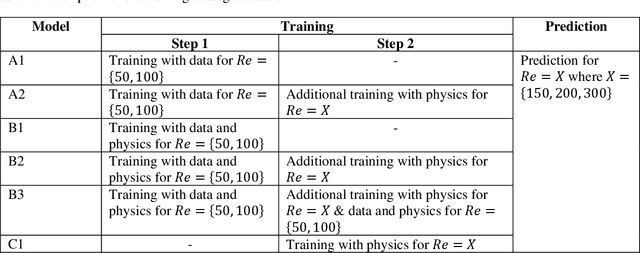
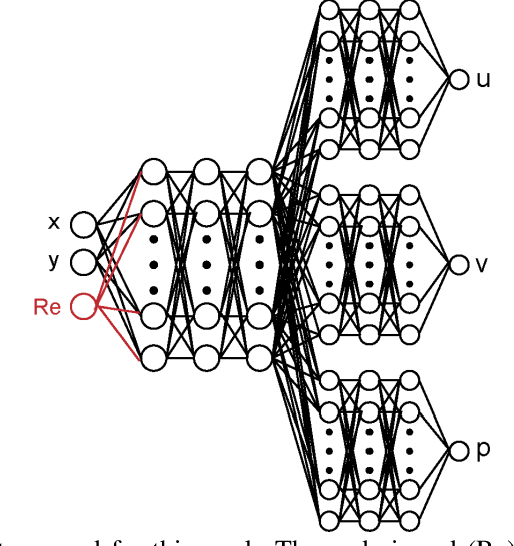
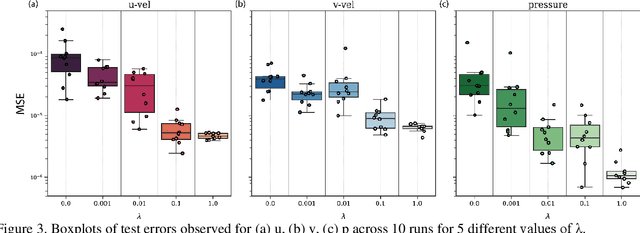
Physics-Informed Neural Networks (PINNs) have recently shown great promise as a way of incorporating physics-based domain knowledge, including fundamental governing equations, into neural network models for many complex engineering systems. They have been particularly effective in the area of inverse problems, where boundary conditions may be ill-defined, and data-absent scenarios, where typical supervised learning approaches will fail. Here, we further explore the use of this modeling methodology to surrogate modeling of a fluid dynamical system, and demonstrate additional undiscussed and interesting advantages of such a modeling methodology over conventional data-driven approaches: 1) improving the model's predictive performance even with incomplete description of the underlying physics; 2) improving the robustness of the model to noise in the dataset; 3) reduced effort to convergence during optimization for a new, previously unseen scenario by transfer optimization of a pre-existing model. Hence, we noticed the inclusion of a physics-based regularization term can substantially improve the equivalent data-driven surrogate model in many substantive ways, including an order of magnitude improvement in test error when the dataset is very noisy, and a 2-3x improvement when only partial physics is included. In addition, we propose a novel transfer optimization scheme for use in such surrogate modeling scenarios and demonstrate an approximately 3x improvement in speed to convergence and an order of magnitude improvement in predictive performance over conventional Xavier initialization for training of new scenarios.