 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLSA-PINN: Linear Boundary Connectivity Loss for Solving PDEs on Complex Geometry
Feb 03, 2023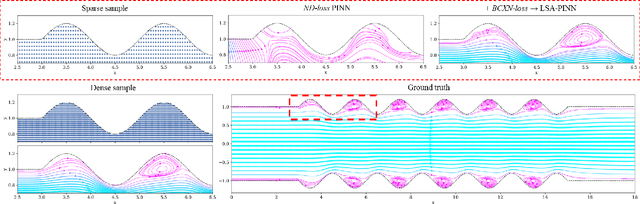
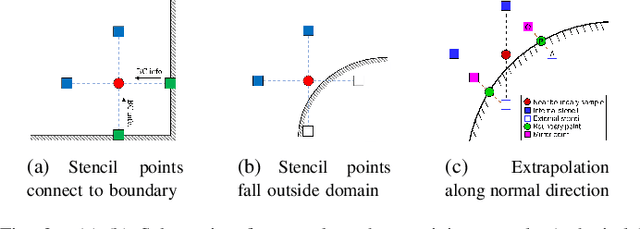
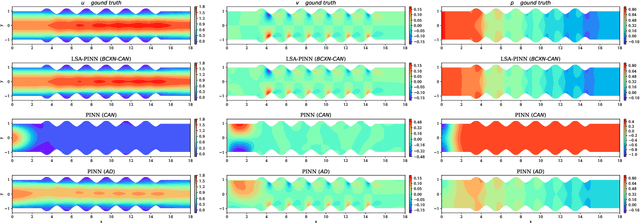
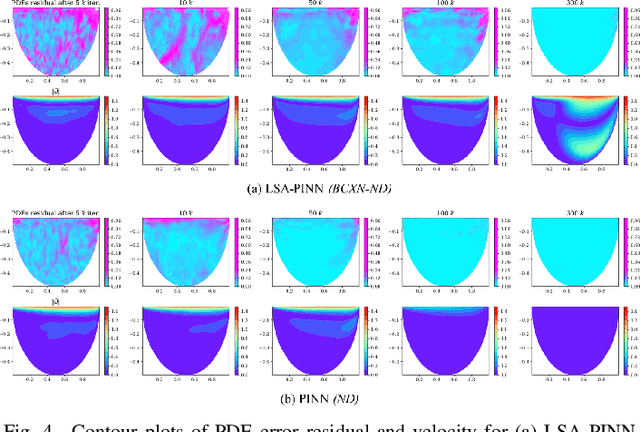
We present a novel loss formulation for efficient learning of complex dynamics from governing physics, typically described by partial differential equations (PDEs), using physics-informed neural networks (PINNs). In our experiments, existing versions of PINNs are seen to learn poorly in many problems, especially for complex geometries, as it becomes increasingly difficult to establish appropriate sampling strategy at the near boundary region. Overly dense sampling can adversely impede training convergence if the local gradient behaviors are too complex to be adequately modelled by PINNs. On the other hand, if the samples are too sparse, existing PINNs tend to overfit the near boundary region, leading to incorrect solution. To prevent such issues, we propose a new Boundary Connectivity (BCXN) loss function which provides linear local structure approximation (LSA) to the gradient behaviors at the boundary for PINN. Our BCXN-loss implicitly imposes local structure during training, thus facilitating fast physics-informed learning across entire problem domains with order of magnitude sparser training samples. This LSA-PINN method shows a few orders of magnitude smaller errors than existing methods in terms of the standard L2-norm metric, while using dramatically fewer training samples and iterations. Our proposed LSA-PINN does not pose any requirement on the differentiable property of the networks, and we demonstrate its benefits and ease of implementation on both multi-layer perceptron and convolutional neural network versions as commonly used in current PINN literature.
JAX-Accelerated Neuroevolution of Physics-informed Neural Networks: Benchmarks and Experimental Results
Dec 15, 2022



This paper introduces the use of evolutionary algorithms for solving differential equations. The solution is obtained by optimizing a deep neural network whose loss function is defined by the residual terms from the differential equations. Recent studies have used stochastic gradient descent (SGD) variants to train these physics-informed neural networks (PINNs), but these methods can struggle to find accurate solutions due to optimization challenges. When solving differential equations, it is important to find the globally optimum parameters of the network, rather than just finding a solution that works well during training. SGD only searches along a single gradient direction, so it may not be the best approach for training PINNs with their accompanying complex optimization landscapes. In contrast, evolutionary algorithms perform a parallel exploration of different solutions in order to avoid getting stuck in local optima and can potentially find more accurate solutions. However, evolutionary algorithms can be slow, which can make them difficult to use in practice. To address this, we provide a set of five benchmark problems with associated performance metrics and baseline results to support the development of evolutionary algorithms for enhanced PINN training. As a baseline, we evaluate the performance and speed of using the widely adopted Covariance Matrix Adaptation Evolution Strategy (CMA-ES) for solving PINNs. We provide the loss and training time for CMA-ES run on TensorFlow, and CMA-ES and SGD run on JAX (with GPU acceleration) for the five benchmark problems. Our results show that JAX-accelerated evolutionary algorithms, particularly CMA-ES, can be a useful approach for solving differential equations. We hope that our work will support the exploration and development of alternative optimization algorithms for the complex task of optimizing PINNs.
CAN-PINN: A Fast Physics-Informed Neural Network Based on Coupled-Automatic-Numerical Differentiation Method
Oct 29, 2021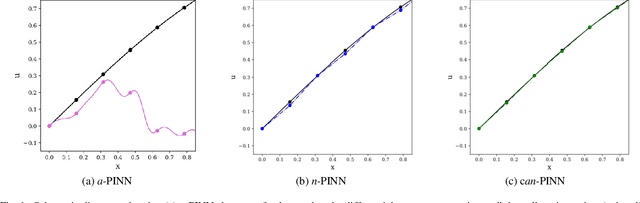
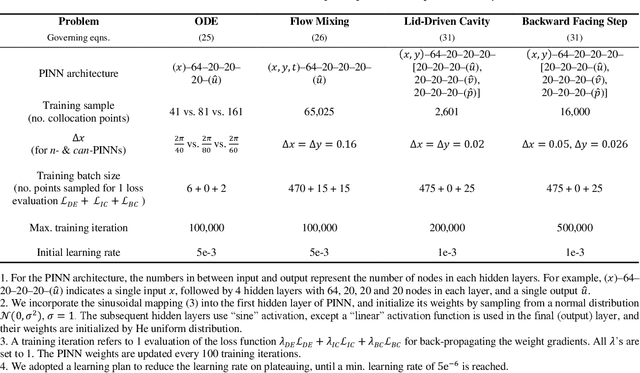
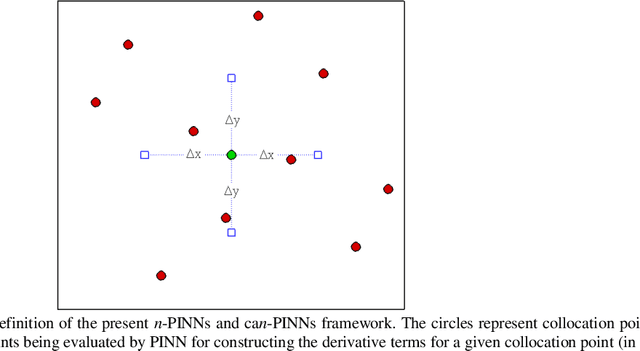
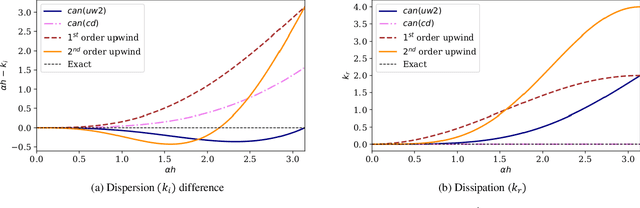
In this study, novel physics-informed neural network (PINN) methods for coupling neighboring support points and automatic differentiation (AD) through Taylor series expansion are proposed to allow efficient training with improved accuracy. The computation of differential operators required for PINNs loss evaluation at collocation points are conventionally obtained via AD. Although AD has the advantage of being able to compute the exact gradients at any point, such PINNs can only achieve high accuracies with large numbers of collocation points, otherwise they are prone to optimizing towards unphysical solution. To make PINN training fast, the dual ideas of using numerical differentiation (ND)-inspired method and coupling it with AD are employed to define the loss function. The ND-based formulation for training loss can strongly link neighboring collocation points to enable efficient training in sparse sample regimes, but its accuracy is restricted by the interpolation scheme. The proposed coupled-automatic-numerical differentiation framework, labeled as can-PINN, unifies the advantages of AD and ND, providing more robust and efficient training than AD-based PINNs, while further improving accuracy by up to 1-2 orders of magnitude relative to ND-based PINNs. For a proof-of-concept demonstration of this can-scheme to fluid dynamic problems, two numerical-inspired instantiations of can-PINN schemes for the convection and pressure gradient terms were derived to solve the incompressible Navier-Stokes (N-S) equations. The superior performance of can-PINNs is demonstrated on several challenging problems, including the flow mixing phenomena, lid driven flow in a cavity, and channel flow over a backward facing step. The results reveal that for challenging problems like these, can-PINNs can consistently achieve very good accuracy whereas conventional AD-based PINNs fail.
Learning in Sinusoidal Spaces with Physics-Informed Neural Networks
Sep 20, 2021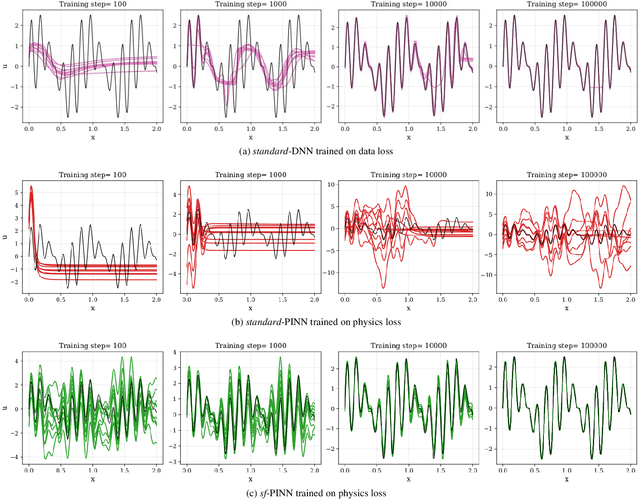
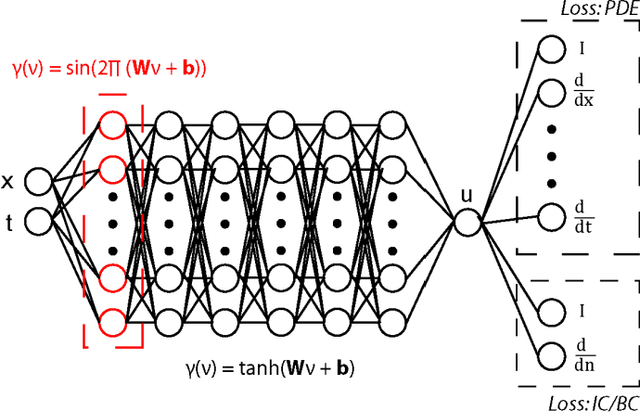

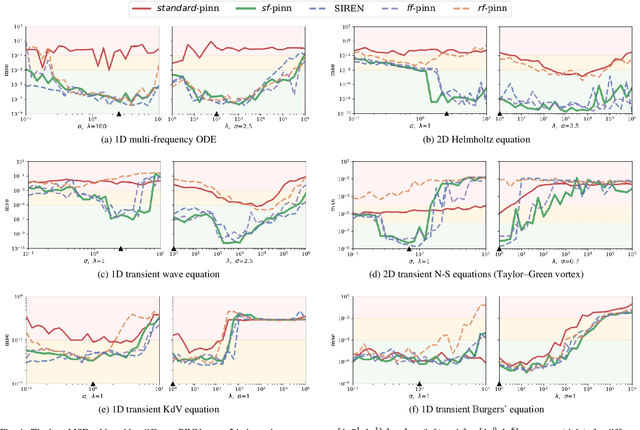
A physics-informed neural network (PINN) uses physics-augmented loss functions, e.g., incorporating the residual term from governing differential equations, to ensure its output is consistent with fundamental physics laws. However, it turns out to be difficult to train an accurate PINN model for many problems in practice. In this paper, we address this issue through a novel perspective on the merits of learning in sinusoidal spaces with PINNs. By analyzing asymptotic behavior at model initialization, we first prove that a PINN of increasing size (i.e., width and depth) induces a bias towards flat outputs. Notably, a flat function is a trivial solution to many physics differential equations, hence, deceptively minimizing the residual term of the augmented loss while being far from the true solution. We then show that the sinusoidal mapping of inputs, in an architecture we label as sf-PINN, is able to elevate output variability, thus avoiding being trapped in the deceptive local minimum. In addition, the level of variability can be effectively modulated to match high-frequency patterns in the problem at hand. A key facet of this paper is the comprehensive empirical study that demonstrates the efficacy of learning in sinusoidal spaces with PINNs for a wide range of forward and inverse modelling problems spanning multiple physics domains.
Improved Surrogate Modeling of Fluid Dynamics with Physics-Informed Neural Networks
May 05, 2021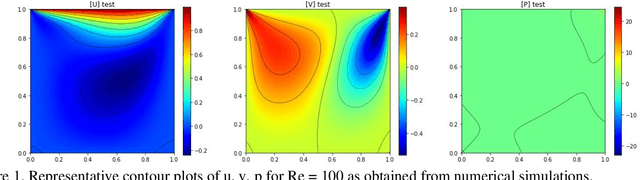
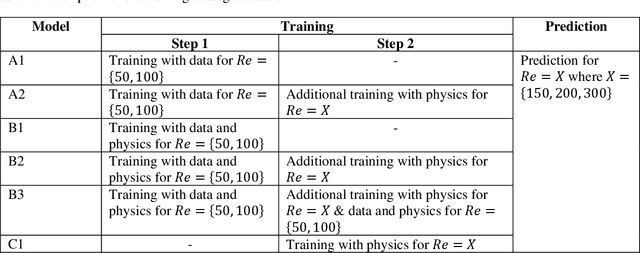
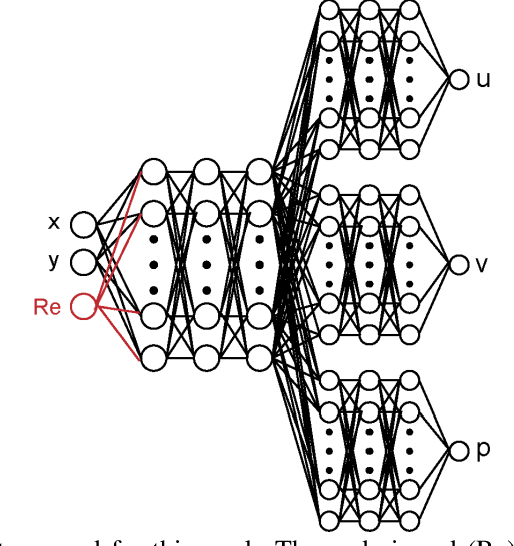
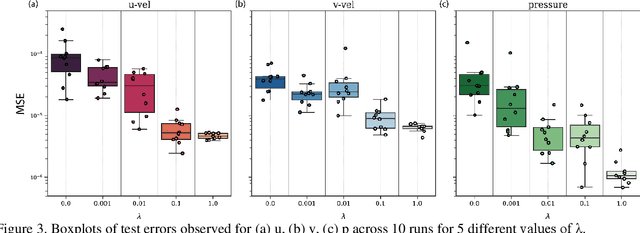
Physics-Informed Neural Networks (PINNs) have recently shown great promise as a way of incorporating physics-based domain knowledge, including fundamental governing equations, into neural network models for many complex engineering systems. They have been particularly effective in the area of inverse problems, where boundary conditions may be ill-defined, and data-absent scenarios, where typical supervised learning approaches will fail. Here, we further explore the use of this modeling methodology to surrogate modeling of a fluid dynamical system, and demonstrate additional undiscussed and interesting advantages of such a modeling methodology over conventional data-driven approaches: 1) improving the model's predictive performance even with incomplete description of the underlying physics; 2) improving the robustness of the model to noise in the dataset; 3) reduced effort to convergence during optimization for a new, previously unseen scenario by transfer optimization of a pre-existing model. Hence, we noticed the inclusion of a physics-based regularization term can substantially improve the equivalent data-driven surrogate model in many substantive ways, including an order of magnitude improvement in test error when the dataset is very noisy, and a 2-3x improvement when only partial physics is included. In addition, we propose a novel transfer optimization scheme for use in such surrogate modeling scenarios and demonstrate an approximately 3x improvement in speed to convergence and an order of magnitude improvement in predictive performance over conventional Xavier initialization for training of new scenarios.