 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChange of Thought: Adaptive Test-Time Computation
Jul 17, 2025
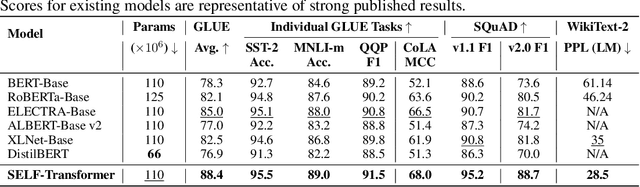

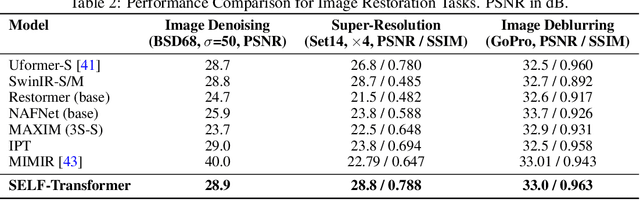
Transformers evaluated in a single, fixed-depth pass are provably limited in expressive power to the constant-depth circuit class TC0. Running a Transformer autoregressively removes that ceiling -- first in next-token prediction and, more recently, in chain-of-thought reasoning. Both regimes rely on feedback loops that decode internal states into tokens only to re-encode them in subsequent steps. While this "thinking aloud" mirrors human reasoning, biological brains iterate without externalising intermediate states as language. To boost the expressive power of encoder Transformers without resorting to token-level autoregression, we introduce the SELF-Transformer: an encoder layer that iteratively refines its own attention weights to a fixed point. Instead of producing -- in one pass -- the alignment matrix that remixes the input sequence, the SELF-Transformer iteratively updates that matrix internally, scaling test-time computation with input difficulty. This adaptivity yields up to 20\% accuracy gains on encoder-style benchmarks without increasing parameter count, demonstrating that input-adaptive alignment at test time offers substantial benefits for only a modest extra compute budget. Self-Transformers thus recover much of the expressive power of iterative reasoning while preserving the simplicity of pure encoder architectures.
DynaLay: An Introspective Approach to Dynamic Layer Selection for Deep Networks
Dec 20, 2023Deep learning models have become increasingly computationally intensive, requiring extensive computational resources and time for both training and inference. A significant contributing factor to this challenge is the uniform computational effort expended on each input example, regardless of its complexity. We introduce \textbf{DynaLay}, an alternative architecture that features a decision-making agent to adaptively select the most suitable layers for processing each input, thereby endowing the model with a remarkable level of introspection. DynaLay reevaluates more complex inputs during inference, adjusting the computational effort to optimize both performance and efficiency. The core of the system is a main model equipped with Fixed-Point Iterative (FPI) layers, capable of accurately approximating complex functions, paired with an agent that chooses these layers or a direct action based on the introspection of the models inner state. The model invests more time in processing harder examples, while minimal computation is required for easier ones. This introspective approach is a step toward developing deep learning models that "think" and "ponder", rather than "ballistically'' produce answers. Our experiments demonstrate that DynaLay achieves accuracy comparable to conventional deep models while significantly reducing computational demands.
Pipeline-Invariant Representation Learning for Neuroimaging
Aug 27, 2022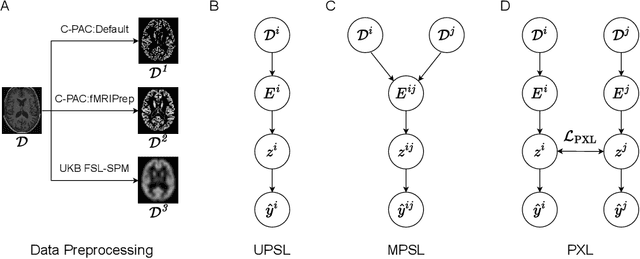

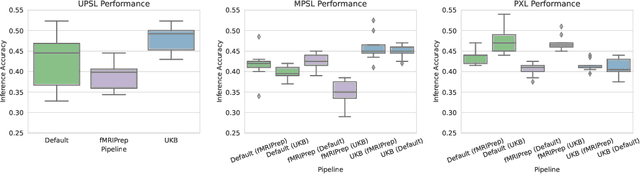
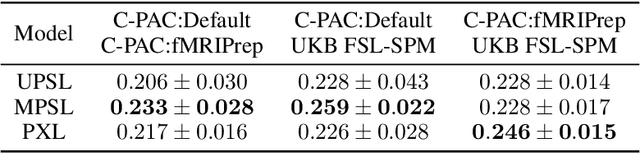
Deep learning has been widely applied in neuroimaging, including to predicting brain-phenotype relationships from magnetic resonance imaging (MRI) volumes. MRI data usually requires extensive preprocessing before it is ready for modeling, even via deep learning, in part due to its high dimensionality and heterogeneity. A growing array of MRI preprocessing pipelines have been developed each with its own strengths and limitations. Recent studies have shown that pipeline-related variation may lead to different scientific findings, even when using the identical data. Meanwhile, the machine learning community has emphasized the importance of shifting from model-centric to data-centric approaches given that data quality plays an essential role in deep learning applications. Motivated by this idea, we first evaluate how preprocessing pipeline selection can impact the downstream performance of a supervised learning model. We next propose two pipeline-invariant representation learning methodologies, MPSL and PXL, to improve consistency in classification performance and to capture similar neural network representations between pipeline pairs. Using 2000 human subjects from the UK Biobank dataset, we demonstrate that both models present unique advantages, in particular that MPSL can be used to improve out-of-sample generalization to new pipelines, while PXL can be used to improve predictive performance consistency and representational similarity within a closed pipeline set. These results suggest that our proposed models can be applied to overcome pipeline-related biases and to improve reproducibility in neuroimaging prediction tasks.
Real Time Multi-Object Detection for Helmet Safety
May 19, 2022

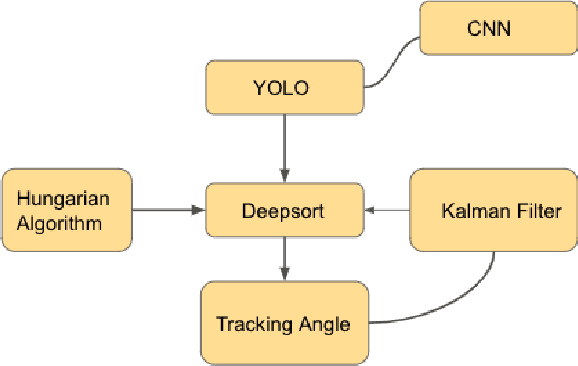
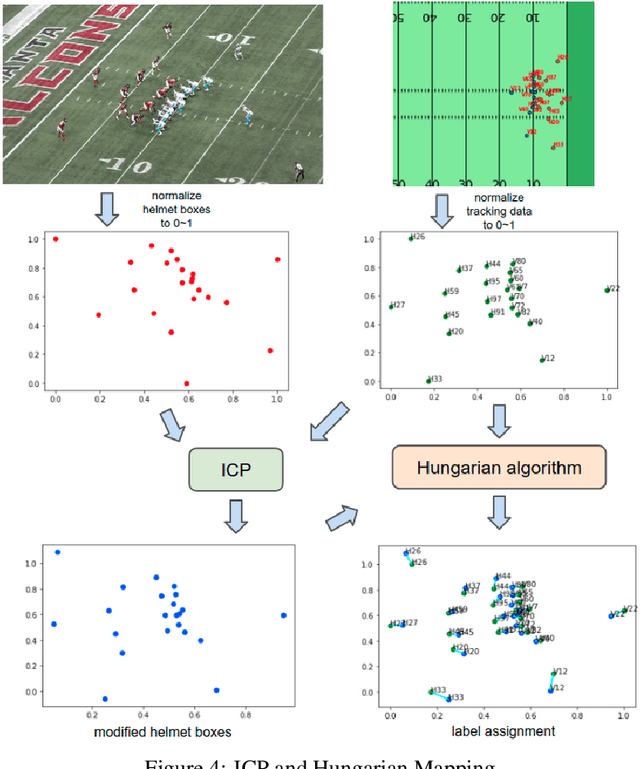
The National Football League and Amazon Web Services teamed up to develop the best sports injury surveillance and mitigation program via the Kaggle competition. Through which the NFL wants to assign specific players to each helmet, which would help accurately identify each player's "exposures" throughout a football play. We are trying to implement a computer vision based ML algorithms capable of assigning detected helmet impacts to correct players via tracking information. Our paper will explain the approach to automatically track player helmets and their collisions. This will also allow them to review previous plays and explore the trends in exposure over time.
Routing and Placement of Macros using Deep Reinforcement Learning
May 19, 2022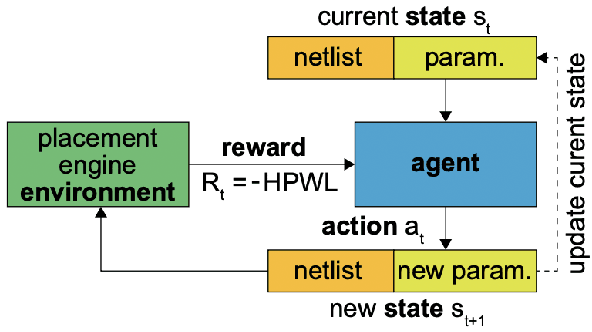
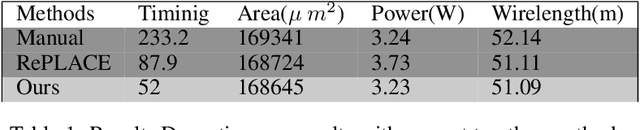
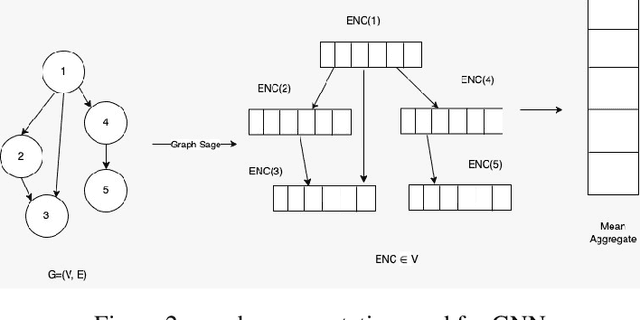
Chip placement has been one of the most time consuming task in any semi conductor area, Due to this negligence, many projects are pushed and chips availability in real markets get delayed. An engineer placing macros on a chip also needs to place it optimally to reduce the three important factors like power, performance and time. Looking at these prior problems we wanted to introduce a new method using Reinforcement Learning where we train the model to place the nodes of a chip netlist onto a chip canvas. We want to build a neural architecture that will accurately reward the agent across a wide variety of input netlist correctly.