 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransient Noise Removal via Diffusion-based Speech Inpainting
Aug 12, 2025In this paper, we present PGDI, a diffusion-based speech inpainting framework for restoring missing or severely corrupted speech segments. Unlike previous methods that struggle with speaker variability or long gap lengths, PGDI can accurately reconstruct gaps of up to one second in length while preserving speaker identity, prosody, and environmental factors such as reverberation. Central to this approach is classifier guidance, specifically phoneme-level guidance, which substantially improves reconstruction fidelity. PGDI operates in a speaker-independent manner and maintains robustness even when long segments are completely masked by strong transient noise, making it well-suited for real-world applications, such as fireworks, door slams, hammer strikes, and construction noise. Through extensive experiments across diverse speakers and gap lengths, we demonstrate PGDI's superior inpainting performance and its ability to handle challenging acoustic conditions. We consider both scenarios, with and without access to the transcript during inference, showing that while the availability of text further enhances performance, the model remains effective even in its absence. For audio samples, visit: https://mordehaym.github.io/PGDI/
Socially Pertinent Robots in Gerontological Healthcare
Apr 11, 2024
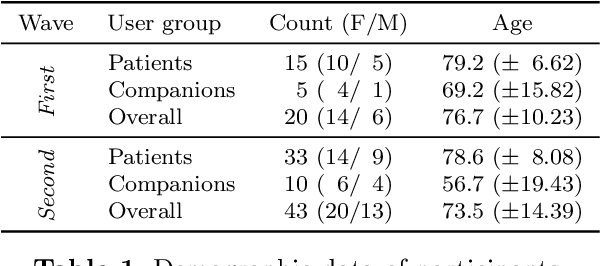
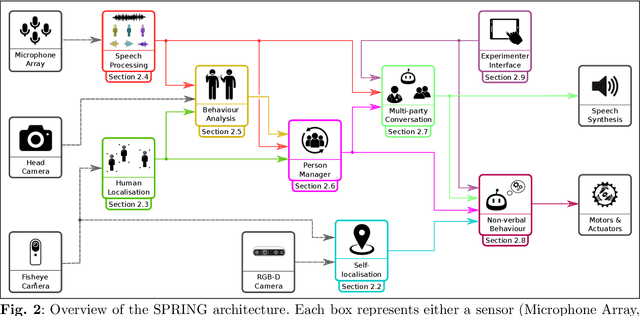
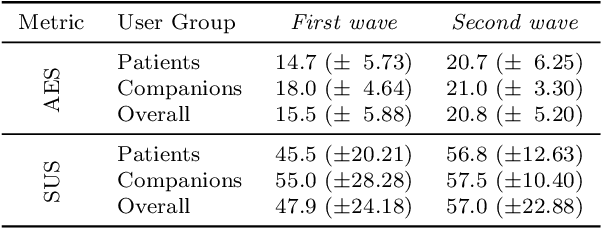
Despite the many recent achievements in developing and deploying social robotics, there are still many underexplored environments and applications for which systematic evaluation of such systems by end-users is necessary. While several robotic platforms have been used in gerontological healthcare, the question of whether or not a social interactive robot with multi-modal conversational capabilities will be useful and accepted in real-life facilities is yet to be answered. This paper is an attempt to partially answer this question, via two waves of experiments with patients and companions in a day-care gerontological facility in Paris with a full-sized humanoid robot endowed with social and conversational interaction capabilities. The software architecture, developed during the H2020 SPRING project, together with the experimental protocol, allowed us to evaluate the acceptability (AES) and usability (SUS) with more than 60 end-users. Overall, the users are receptive to this technology, especially when the robot perception and action skills are robust to environmental clutter and flexible to handle a plethora of different interactions.
Single-Microphone Speaker Separation and Voice Activity Detection in Noisy and Reverberant Environments
Jan 07, 2024



Speech separation involves extracting an individual speaker's voice from a multi-speaker audio signal. The increasing complexity of real-world environments, where multiple speakers might converse simultaneously, underscores the importance of effective speech separation techniques. This work presents a single-microphone speaker separation network with TF attention aiming at noisy and reverberant environments. We dub this new architecture as Separation TF Attention Network (Sep-TFAnet). In addition, we present a variant of the separation network, dubbed $ \text{Sep-TFAnet}^{\text{VAD}}$, which incorporates a voice activity detector (VAD) into the separation network. The separation module is based on a temporal convolutional network (TCN) backbone inspired by the Conv-Tasnet architecture with multiple modifications. Rather than a learned encoder and decoder, we use short-time Fourier transform (STFT) and inverse short-time Fourier transform (iSTFT) for the analysis and synthesis, respectively. Our system is specially developed for human-robotic interactions and should support online mode. The separation capabilities of $ \text{Sep-TFAnet}^{\text{VAD}}$ and Sep-TFAnet were evaluated and extensively analyzed under several acoustic conditions, demonstrating their advantages over competing methods. Since separation networks trained on simulated data tend to perform poorly on real recordings, we also demonstrate the ability of the proposed scheme to better generalize to realistic examples recorded in our acoustic lab by a humanoid robot. Project page: https://Sep-TFAnet.github.io