 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIFT: Selective-Index For Fast Compute of RAG Prefill by Exploiting Attention Invariance
Jun 08, 2026Retrieval-Augmented Generation (RAG) injects LLM queries with relevant documents to improve response quality. This injection increases prompt length and slows time to first token (TTFT). Unlike standard queries, RAG queries have a unique property of context reuse where the same documents recur across user queries. Thus, fully recomputing documents for every RAG query does redundant compute and increases TTFT. Prior works precompute KV tensors of RAG documents offline and coarsely recompute some tokens during online prefill. However, such KV reuse is often slower than full recomputation on modern GPUs due to high-latency disk transfers. Further, such a coarse-grained recomputation degrades accuracy. To address these limitations, this paper proposes SIFT: Selective-Index For Fast Compute of RAG Prefill by Exploiting Attention Invariance. SIFT processes documents offline and extracts fine-grained locations of high attention scores for each document. Next, we identify the following attention invariance insights that enable us to exploit the extracted locations during runtime: (1) Local-Attention Invariance: The location of high attention scores within a document remain invariant to surrounding documents. This helps us predict the location of high scores where the document attends to itself. (2) Cross-Attention Consistency: Keys with high intra-document attention also attract cross-attention from subsequent documents. This helps us predict the location of high scores where the document attends to future documents. Critically, SIFT stores no KV data and only stores locations of high scores in the form of two compact bit vectors. SIFT's storage is up to 24,000x smaller than KV tensors, obviating costly disk transfers. During prefill, SIFT computes the attention only for the marked locations and improves TTFT by 1.71x while holding accuracy within 1% of full recompute.
Élivágar: Efficient Quantum Circuit Search for Classification
Jan 17, 2024



Designing performant and noise-robust circuits for Quantum Machine Learning (QML) is challenging -- the design space scales exponentially with circuit size, and there are few well-supported guiding principles for QML circuit design. Although recent Quantum Circuit Search (QCS) methods attempt to search for performant QML circuits that are also robust to hardware noise, they directly adopt designs from classical Neural Architecture Search (NAS) that are misaligned with the unique constraints of quantum hardware, resulting in high search overheads and severe performance bottlenecks. We present \'Eliv\'agar, a novel resource-efficient, noise-guided QCS framework. \'Eliv\'agar innovates in all three major aspects of QCS -- search space, search algorithm and candidate evaluation strategy -- to address the design flaws in current classically-inspired QCS methods. \'Eliv\'agar achieves hardware-efficiency and avoids an expensive circuit-mapping co-search via noise- and device topology-aware candidate generation. By introducing two cheap-to-compute predictors, Clifford noise resilience and Representational capacity, \'Eliv\'agar decouples the evaluation of noise robustness and performance, enabling early rejection of low-fidelity circuits and reducing circuit evaluation costs. Due to its resource-efficiency, \'Eliv\'agar can further search for data embeddings, significantly improving performance. Based on a comprehensive evaluation of \'Eliv\'agar on 12 real quantum devices and 9 QML applications, \'Eliv\'agar achieves 5.3% higher accuracy and a 271$\times$ speedup compared to state-of-the-art QCS methods.
Skipper: Improving the Reach and Fidelity of Quantum Annealers by Skipping Long Chains
Dec 01, 2023Quantum Annealers (QAs) operate as single-instruction machines, lacking a SWAP operation to overcome limited qubit connectivity. Consequently, multiple physical qubits are chained to form a program qubit with higher connectivity, resulting in a drastically diminished effective QA capacity by up to 33x. We observe that in QAs: (a) chain lengths exhibit a power-law distribution, a few dominant chains holding substantially more qubits than others; and (b) about 25% of physical qubits remain unused, getting isolated between these chains. We propose Skipper, a software technique that enhances the capacity and fidelity of QAs by skipping dominant chains and substituting their program qubit with two readout results. Using a 5761-qubit QA, we demonstrate that Skipper can tackle up to 59% (Avg. 28%) larger problems when eleven chains are skipped. Additionally, Skipper can improve QA fidelity by up to 44% (Avg. 33%) when cutting five chains (32 runs). Users can specify up to eleven chain cuts in Skipper, necessitating about 2,000 distinct quantum executable runs. To mitigate this, we introduce Skipper-G, a greedy scheme that skips sub-problems less likely to hold the global optimum, executing a maximum of 23 quantum executables with eleven chain trims. Skipper-G can boost QA fidelity by up to 41% (Avg. 29%) when cutting five chains (11 runs).
Enigma: Privacy-Preserving Execution of QAOA on Untrusted Quantum Computers
Nov 22, 2023
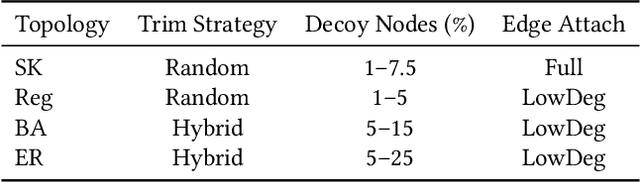


Quantum computers can solve problems that are beyond the capabilities of conventional computers. As quantum computers are expensive and hard to maintain, the typical model for performing quantum computation is to send the circuit to a quantum cloud provider. This leads to privacy concerns for commercial entities as an untrusted server can learn protected information from the provided circuit. Current proposals for Secure Quantum Computing (SQC) either rely on emerging technologies (such as quantum networks) or incur prohibitive overheads (for Quantum Homomorphic Encryption). The goal of our paper is to enable low-cost privacy-preserving quantum computation that can be used with current systems. We propose Enigma, a suite of privacy-preserving schemes specifically designed for the Quantum Approximate Optimization Algorithm (QAOA). Unlike previous SQC techniques that obfuscate quantum circuits, Enigma transforms the input problem of QAOA, such that the resulting circuit and the outcomes are unintelligible to the server. We introduce three variants of Enigma. Enigma-I protects the coefficients of QAOA using random phase flipping and fudging of values. Enigma-II protects the nodes of the graph by introducing decoy qubits, which are indistinguishable from primary ones. Enigma-III protects the edge information of the graph by modifying the graph such that each node has an identical number of connections. For all variants of Enigma, we demonstrate that we can still obtain the solution for the original problem. We evaluate Enigma using IBM quantum devices and show that the privacy improvements of Enigma come at only a small reduction in fidelity (1%-13%).
FrozenQubits: Boosting Fidelity of QAOA by Skipping Hotspot Nodes
Oct 31, 2022


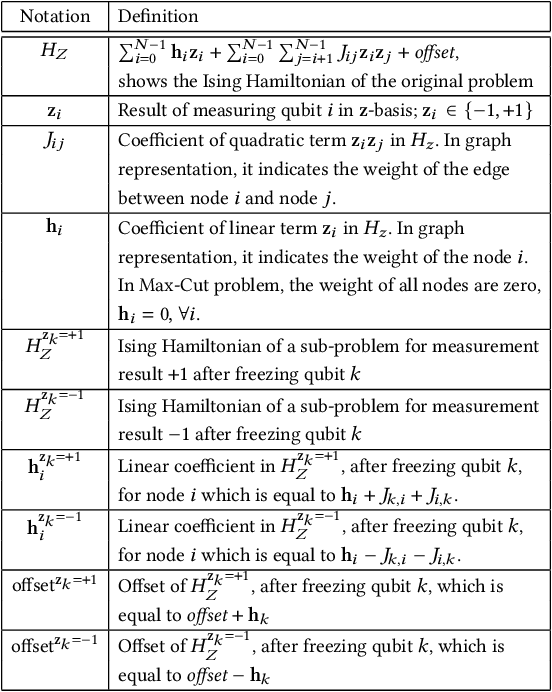
Quantum Approximate Optimization Algorithm (QAOA) is one of the leading candidates for demonstrating the quantum advantage using near-term quantum computers. Unfortunately, high device error rates limit us from reliably running QAOA circuits for problems with more than a few qubits. In QAOA, the problem graph is translated into a quantum circuit such that every edge corresponds to two 2-qubit CNOT operations in each layer of the circuit. As CNOTs are extremely error-prone, the fidelity of QAOA circuits is dictated by the number of edges in the problem graph. We observe that majority of graphs corresponding to real-world applications follow the ``power-law`` distribution, where some hotspot nodes have significantly higher number of connections. We leverage this insight and propose ``FrozenQubits`` that freezes the hotspot nodes or qubits and intelligently partitions the state-space of the given problem into several smaller sub-spaces which are then solved independently. The corresponding QAOA sub-circuits are significantly less vulnerable to gate and decoherence errors due to the reduced number of CNOT operations in each sub-circuit. Unlike prior circuit-cutting approaches, FrozenQubits does not require any exponentially complex post-processing step. Our evaluations with 5,300 QAOA circuits on eight different quantum computers from IBM shows that FrozenQubits can improve the quality of solutions by 8.73x on average (and by up to 57x), albeit utilizing 2x more quantum resources.
MAZE: Data-Free Model Stealing Attack Using Zeroth-Order Gradient Estimation
May 06, 2020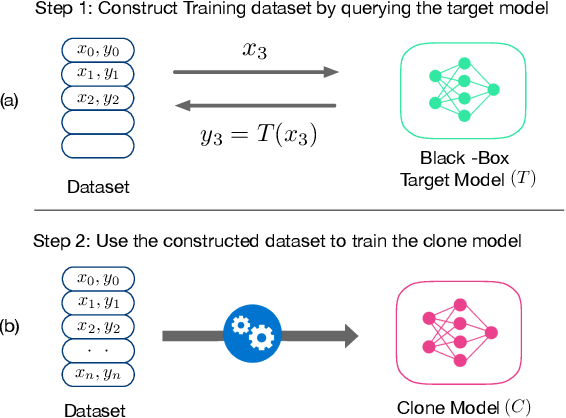
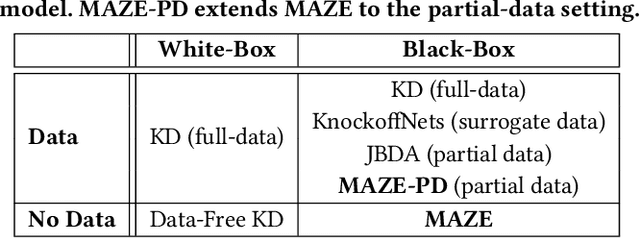

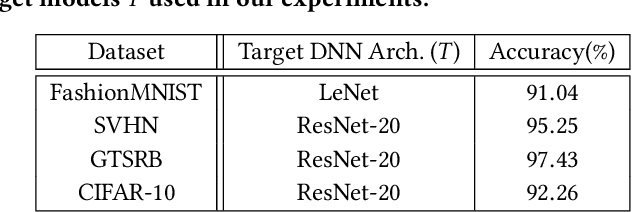
Model Stealing (MS) attacks allow an adversary with black-box access to a Machine Learning model to replicate its functionality, compromising the confidentiality of the model. Such attacks train a clone model by using the predictions of the target model for different inputs. The effectiveness of such attacks relies heavily on the availability of data necessary to query the target model. Existing attacks either assume partial access to the dataset of the target model or availability of an alternate dataset with semantic similarities. This paper proposes MAZE -- a data-free model stealing attack using zeroth-order gradient estimation. In contrast to prior works, MAZE does not require any data and instead creates synthetic data using a generative model. Inspired by recent works in data-free Knowledge Distillation (KD), we train the generative model using a disagreement objective to produce inputs that maximize disagreement between the clone and the target model. However, unlike the white-box setting of KD, where the gradient information is available, training a generator for model stealing requires performing black-box optimization, as it involves accessing the target model under attack. MAZE relies on zeroth-order gradient estimation to perform this optimization and enables a highly accurate MS attack. Our evaluation with four datasets shows that MAZE provides a normalized clone accuracy in the range of 0.91x to 0.99x, and outperforms even the recent attacks that rely on partial data (JBDA, clone accuracy 0.13x to 0.69x) and surrogate data (KnockoffNets, clone accuracy 0.52x to 0.97x). We also study an extension of MAZE in the partial-data setting and develop MAZE-PD, which generates synthetic data closer to the target distribution. MAZE-PD further improves the clone accuracy (0.97x to 1.0x) and reduces the query required for the attack by 2x-24x.