 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCITB: A Benchmark for Continual Instruction Tuning
Oct 23, 2023Continual learning (CL) is a paradigm that aims to replicate the human ability to learn and accumulate knowledge continually without forgetting previous knowledge and transferring it to new tasks. Recent instruction tuning (IT) involves fine-tuning models to make them more adaptable to solving NLP tasks in general. However, it is still uncertain how instruction tuning works in the context of CL tasks. This challenging yet practical problem is formulated as Continual Instruction Tuning (CIT). In this work, we establish a CIT benchmark consisting of learning and evaluation protocols. We curate two long dialogue task streams of different types, InstrDialog and InstrDialog++, to study various CL methods systematically. Our experiments show that existing CL methods do not effectively leverage the rich natural language instructions, and fine-tuning an instruction-tuned model sequentially can yield similar or better results. We further explore different aspects that might affect the learning of CIT. We hope this benchmark will facilitate more research in this direction.
Turn-Level Active Learning for Dialogue State Tracking
Oct 23, 2023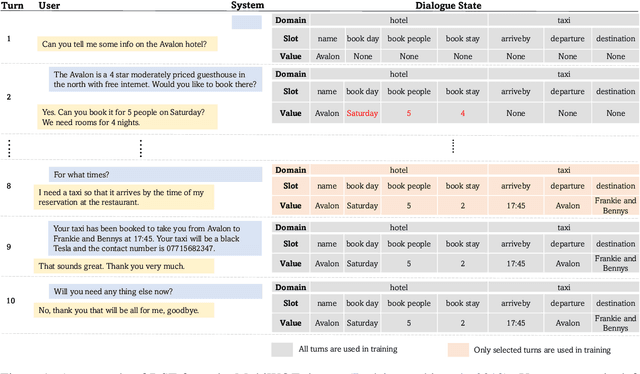
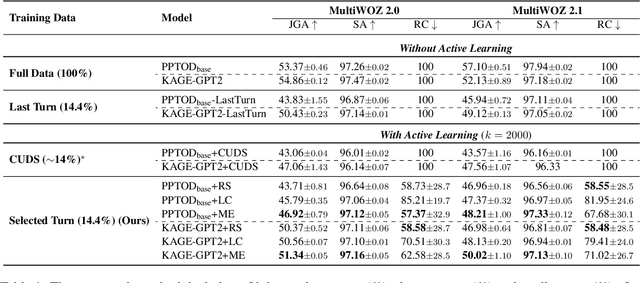
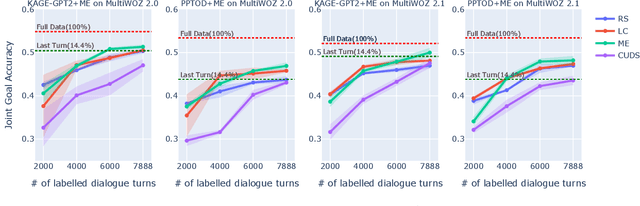

Dialogue state tracking (DST) plays an important role in task-oriented dialogue systems. However, collecting a large amount of turn-by-turn annotated dialogue data is costly and inefficient. In this paper, we propose a novel turn-level active learning framework for DST to actively select turns in dialogues to annotate. Given the limited labelling budget, experimental results demonstrate the effectiveness of selective annotation of dialogue turns. Additionally, our approach can effectively achieve comparable DST performance to traditional training approaches with significantly less annotated data, which provides a more efficient way to annotate new dialogue data.
How Do Large Language Models Capture the Ever-changing World Knowledge? A Review of Recent Advances
Oct 11, 2023Although large language models (LLMs) are impressive in solving various tasks, they can quickly be outdated after deployment. Maintaining their up-to-date status is a pressing concern in the current era. This paper provides a comprehensive review of recent advances in aligning LLMs with the ever-changing world knowledge without re-training from scratch. We categorize research works systemically and provide in-depth comparisons and discussion. We also discuss existing challenges and highlight future directions to facilitate research in this field. We release the paper list at https://github.com/hyintell/awesome-refreshing-llms
HRGCN: Heterogeneous Graph-level Anomaly Detection with Hierarchical Relation-augmented Graph Neural Networks
Aug 28, 2023This work considers the problem of heterogeneous graph-level anomaly detection. Heterogeneous graphs are commonly used to represent behaviours between different types of entities in complex industrial systems for capturing as much information about the system operations as possible. Detecting anomalous heterogeneous graphs from a large set of system behaviour graphs is crucial for many real-world applications like online web/mobile service and cloud access control. To address the problem, we propose HRGCN, an unsupervised deep heterogeneous graph neural network, to model complex heterogeneous relations between different entities in the system for effectively identifying these anomalous behaviour graphs. HRGCN trains a hierarchical relation-augmented Heterogeneous Graph Neural Network (HetGNN), which learns better graph representations by modelling the interactions among all the system entities and considering both source-to-destination entity (node) types and their relation (edge) types. Extensive evaluation on two real-world application datasets shows that HRGCN outperforms state-of-the-art competing anomaly detection approaches. We further present a real-world industrial case study to justify the effectiveness of HRGCN in detecting anomalous (e.g., congested) network devices in a mobile communication service. HRGCN is available at https://github.com/jiaxililearn/HRGCN.
Is Neural Topic Modelling Better than Clustering? An Empirical Study on Clustering with Contextual Embeddings for Topics
Apr 21, 2022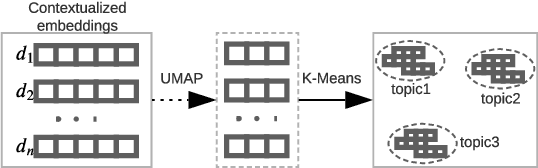
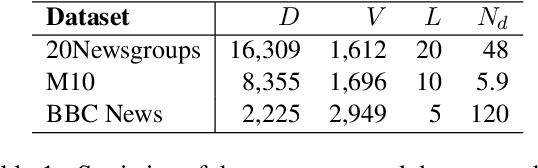
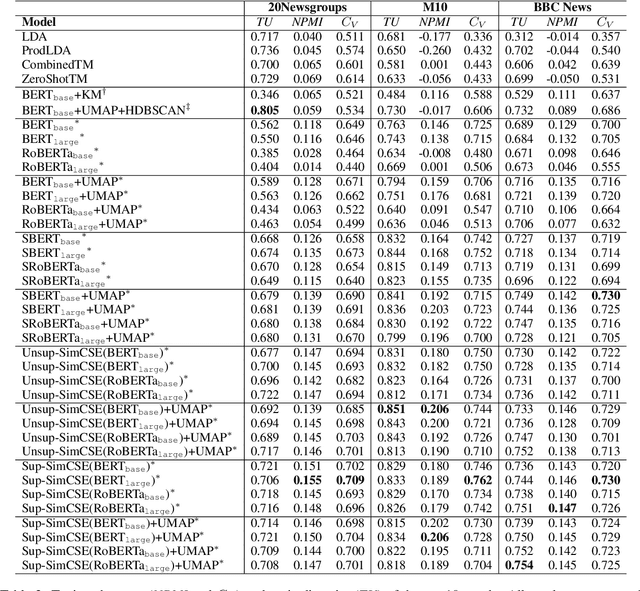
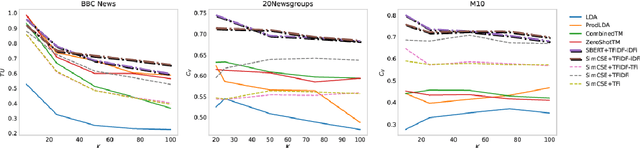
Recent work incorporates pre-trained word embeddings such as BERT embeddings into Neural Topic Models (NTMs), generating highly coherent topics. However, with high-quality contextualized document representations, do we really need sophisticated neural models to obtain coherent and interpretable topics? In this paper, we conduct thorough experiments showing that directly clustering high-quality sentence embeddings with an appropriate word selecting method can generate more coherent and diverse topics than NTMs, achieving also higher efficiency and simplicity.