 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Indoor Localization via Reinforcement Learning-based Information Fusion
Oct 27, 2022The paper is motivated by the importance of the Smart Cities (SC) concept for future management of global urbanization. Among all Internet of Things (IoT)-based communication technologies, Bluetooth Low Energy (BLE) plays a vital role in city-wide decision making and services. Extreme fluctuations of the Received Signal Strength Indicator (RSSI), however, prevent this technology from being a reliable solution with acceptable accuracy in the dynamic indoor tracking/localization approaches for ever-changing SC environments. The latest version of the BLE v.5.1 introduced a better possibility for tracking users by utilizing the direction finding approaches based on the Angle of Arrival (AoA), which is more reliable. There are still some fundamental issues remaining to be addressed. Existing works mainly focus on implementing stand-alone models overlooking potentials fusion strategies. The paper addresses this gap and proposes a novel Reinforcement Learning (RL)-based information fusion framework (RL-IFF) by coupling AoA with RSSI-based particle filtering and Inertial Measurement Unit (IMU)-based Pedestrian Dead Reckoning (PDR) frameworks. The proposed RL-IFF solution is evaluated through a comprehensive set of experiments illustrating superior performance compared to its counterparts.
AKF-SR: Adaptive Kalman Filtering-based Successor Representation
Mar 31, 2022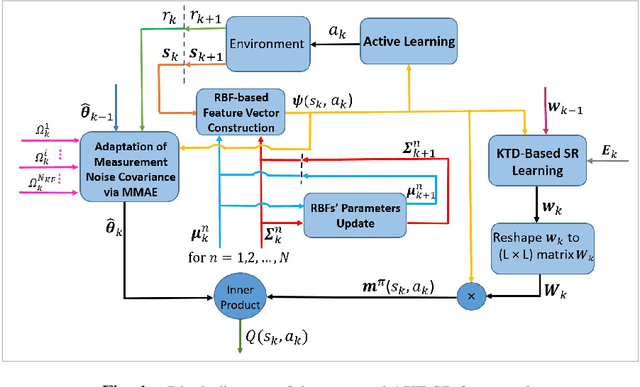

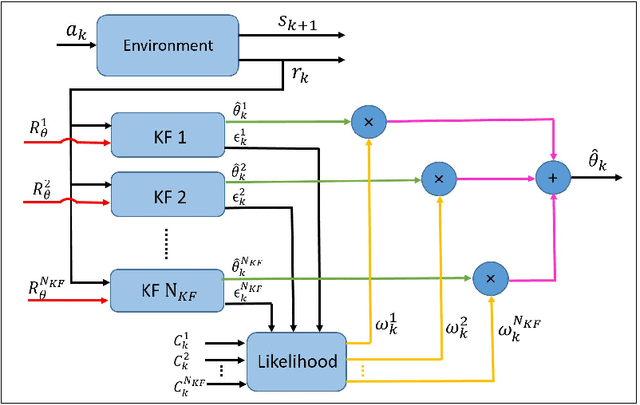
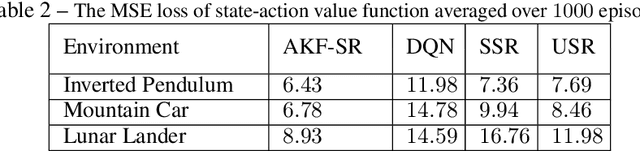
Recent studies in neuroscience suggest that Successor Representation (SR)-based models provide adaptation to changes in the goal locations or reward function faster than model-free algorithms, together with lower computational cost compared to that of model-based algorithms. However, it is not known how such representation might help animals to manage uncertainty in their decision-making. Existing methods for SR learning do not capture uncertainty about the estimated SR. In order to address this issue, the paper presents a Kalman filter-based SR framework, referred to as Adaptive Kalman Filtering-based Successor Representation (AKF-SR). First, Kalman temporal difference approach, which is a combination of the Kalman filter and the temporal difference method, is used within the AKF-SR framework to cast the SR learning procedure into a filtering problem to benefit from the uncertainty estimation of the SR, and also decreases in memory requirement and sensitivity to model's parameters in comparison to deep neural network-based algorithms. An adaptive Kalman filtering approach is then applied within the proposed AKF-SR framework in order to tune the measurement noise covariance and measurement mapping function of Kalman filter as the most important parameters affecting the filter's performance. Moreover, an active learning method that exploits the estimated uncertainty of the SR to form the behaviour policy leading to more visits to less certain values is proposed to improve the overall performance of an agent in terms of received rewards while interacting with its environment.
Multi-Agent Reinforcement Learning via Adaptive Kalman Temporal Difference and Successor Representation
Dec 30, 2021
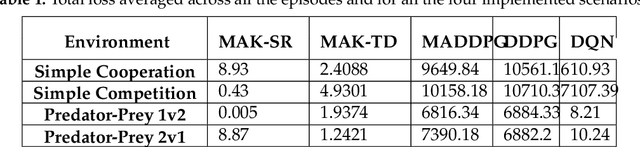
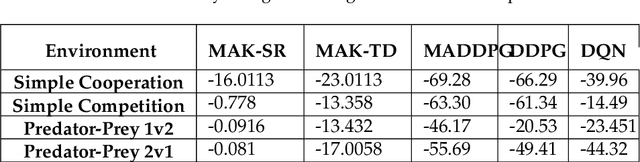
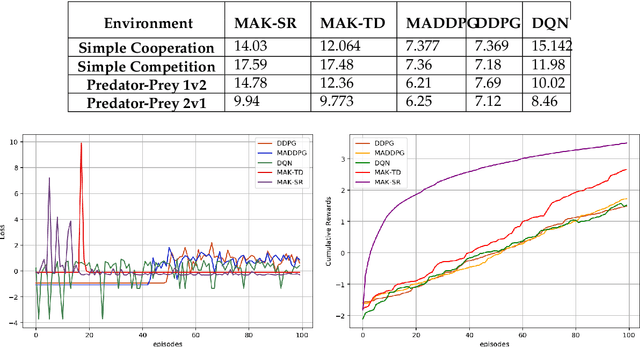
Distributed Multi-Agent Reinforcement Learning (MARL) algorithms has attracted a surge of interest lately mainly due to the recent advancements of Deep Neural Networks (DNNs). Conventional Model-Based (MB) or Model-Free (MF) RL algorithms are not directly applicable to the MARL problems due to utilization of a fixed reward model for learning the underlying value function. While DNN-based solutions perform utterly well when a single agent is involved, such methods fail to fully generalize to the complexities of MARL problems. In other words, although recently developed approaches based on DNNs for multi-agent environments have achieved superior performance, they are still prone to overfiting, high sensitivity to parameter selection, and sample inefficiency. The paper proposes the Multi-Agent Adaptive Kalman Temporal Difference (MAK-TD) framework and its Successor Representation-based variant, referred to as the MAK-SR. Intuitively speaking, the main objective is to capitalize on unique characteristics of Kalman Filtering (KF) such as uncertainty modeling and online second order learning. The proposed MAK-TD/SR frameworks consider the continuous nature of the action-space that is associated with high dimensional multi-agent environments and exploit Kalman Temporal Difference (KTD) to address the parameter uncertainty. By leveraging the KTD framework, SR learning procedure is modeled into a filtering problem, where Radial Basis Function (RBF) estimators are used to encode the continuous space into feature vectors. On the other hand, for learning localized reward functions, we resort to Multiple Model Adaptive Estimation (MMAE), to deal with the lack of prior knowledge on the observation noise covariance and observation mapping function. The proposed MAK-TD/SR frameworks are evaluated via several experiments, which are implemented through the OpenAI Gym MARL benchmarks.
Online Dynamic Window Assisted Two-stage LSTM Frameworks for Indoor Localization
Sep 01, 2021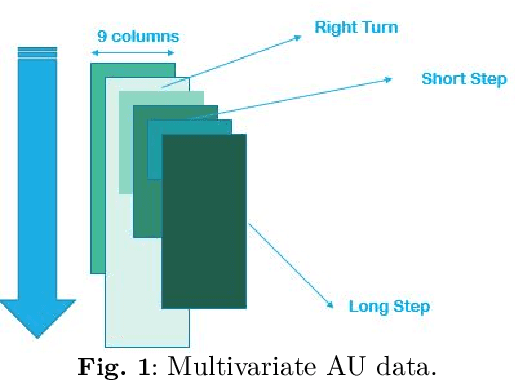
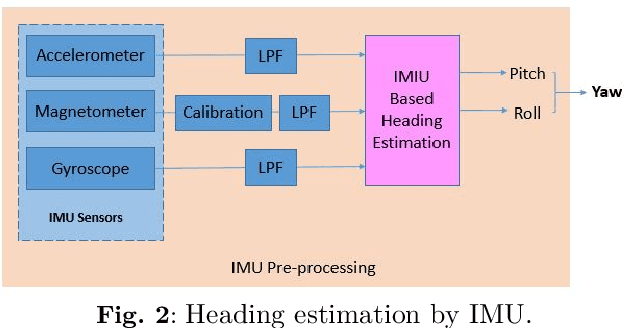
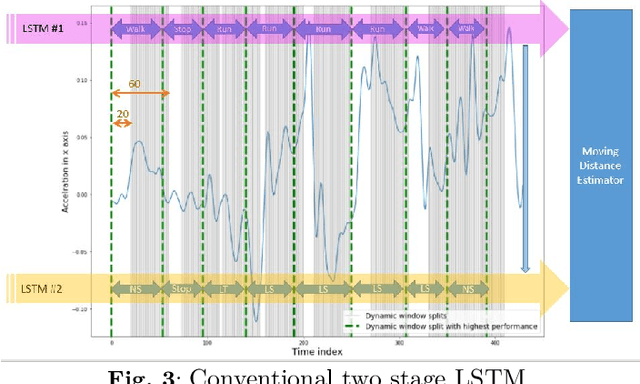
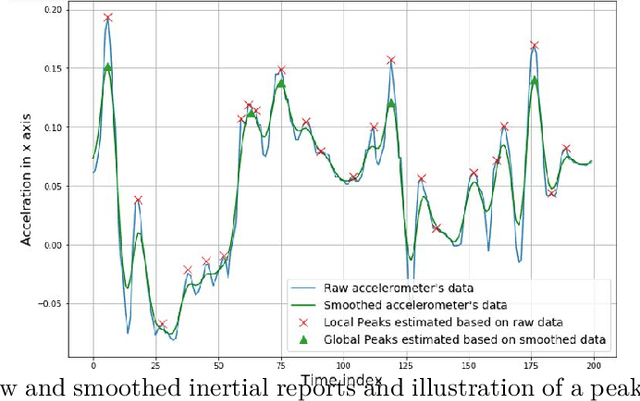
Internet of Things (IoT)-based indoor localization has gained significant popularity recently to satisfy the ever-increasing requirements of indoor Location-based Services (LBS). In this context, Inertial Measurement Unit (IMU)-based localization is of interest as it provides a scalable solution independent of any proprietary sensors/modules. Existing IMU-based methodologies, however, are mainly developed based on statistical heading and step length estimation techniques that suffer from cumulative error issues and have extensive computational time requirements limiting their application for real-time indoor positioning. To address the aforementioned issues, we propose the Online Dynamic Window (ODW)-assisted two-stage Long Short Term Memory (LSTM) localization framework. Three ODWs are proposed, where the first model uses a Natural Language Processing (NLP)-inspired Dynamic Window (DW) approach, which significantly reduces the required computational time. The second framework is developed based on a Signal Processing Dynamic Windowing (SP-DW) approach to further reduce the required processing time of the two-stage LSTM-based model. The third ODW, referred to as the SP-NLP, combines the first two windowing mechanisms to further improve the overall achieved accuracy. Compared to the traditional LSTM-based positioning approaches, which suffer from either high tensor computation requirements or low accuracy, the proposed ODW-assisted models can perform indoor localization in a near-real time fashion with high accuracy. Performances of the proposed ODW-assisted models are evaluated based on a real Pedestrian Dead Reckoning (PDR) dataset. The results illustrate potentials of the proposed ODW-assisted techniques in achieving high classification accuracy with significantly reduced computational time, making them applicable for near real-time implementations.
TB-ICT: A Trustworthy Blockchain-Enabled System for Indoor COVID-19 Contact Tracing
Aug 09, 2021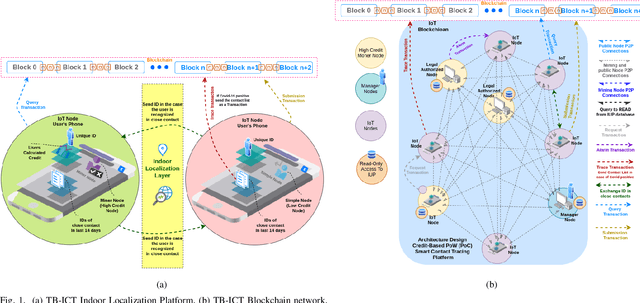
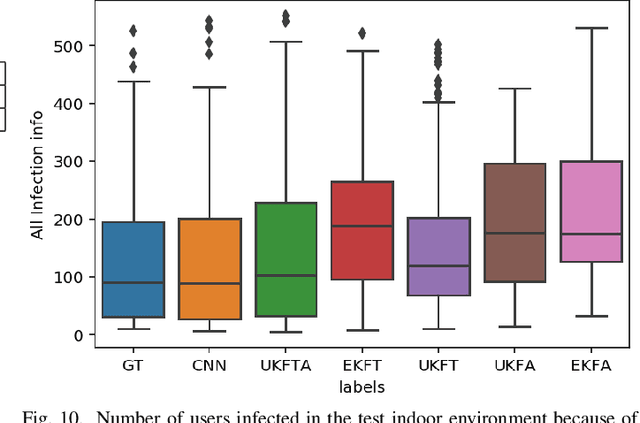
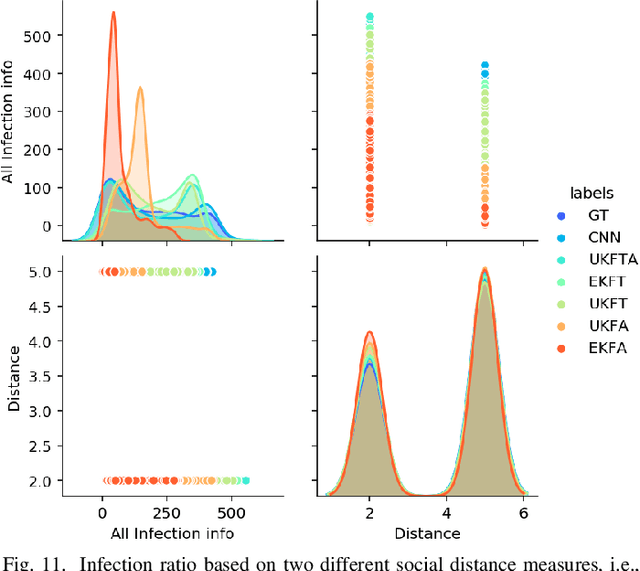
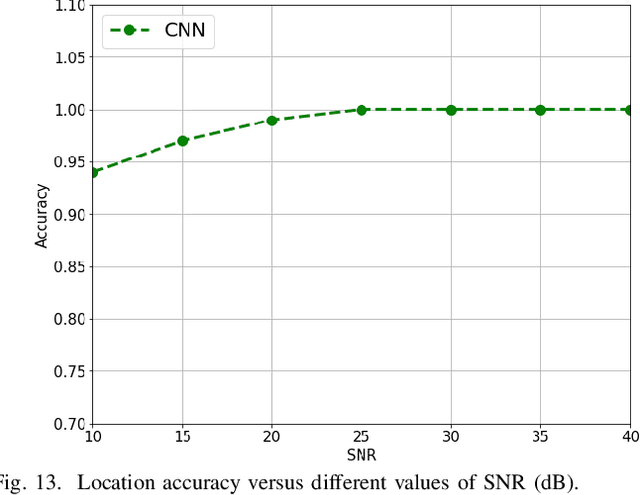
Recently, as a consequence of the COVID-19 pandemic, dependence on Contact Tracing (CT) models has significantly increased to prevent spread of this highly contagious virus and be prepared for the potential future ones. Since the spreading probability of the novel coronavirus in indoor environments is much higher than that of the outdoors, there is an urgent and unmet quest to develop/design efficient, autonomous, trustworthy, and secure indoor CT solutions. Despite such an urgency, this field is still in its infancy. The paper addresses this gap and proposes the Trustworthy Blockchain-enabled system for Indoor Contact Tracing (TB-ICT) framework. The TB-ICT framework is proposed to protect privacy and integrity of the underlying CT data from unauthorized access. More specifically, it is a fully distributed and innovative blockchain platform exploiting the proposed dynamic Proof of Work (dPoW) credit-based consensus algorithm coupled with Randomized Hash Window (W-Hash) and dynamic Proof of Credit (dPoC) mechanisms to differentiate between honest and dishonest nodes. The TB-ICT not only provides a decentralization in data replication but also quantifies the node's behavior based on its underlying credit-based mechanism. For achieving high localization performance, we capitalize on availability of Internet of Things (IoT) indoor localization infrastructures, and develop a data driven localization model based on Bluetooth Low Energy (BLE) sensor measurements. The simulation results show that the proposed TB-ICT prevents the COVID-19 from spreading by implementation of a highly accurate contact tracing model while improving the users' privacy and security.
COVID19-HPSMP: COVID-19 Adopted Hybrid and Parallel Deep Information Fusion Framework for Stock Price Movement Prediction
Jan 02, 2021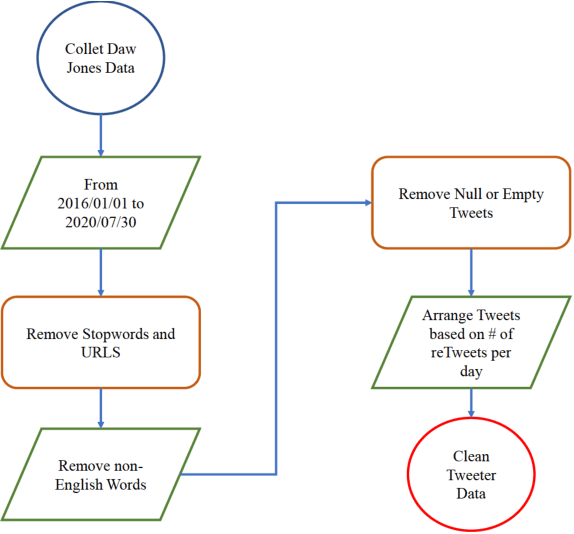

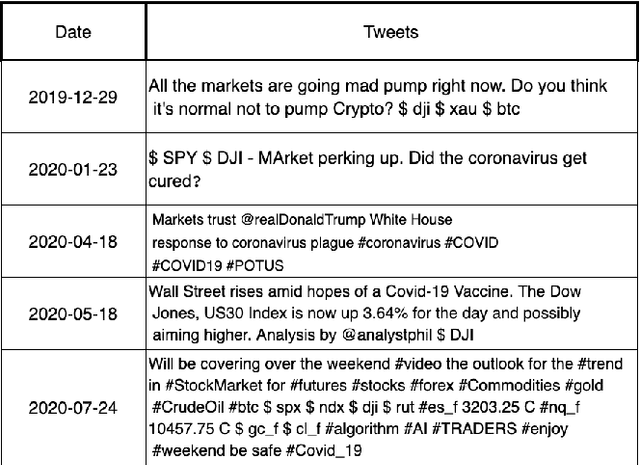
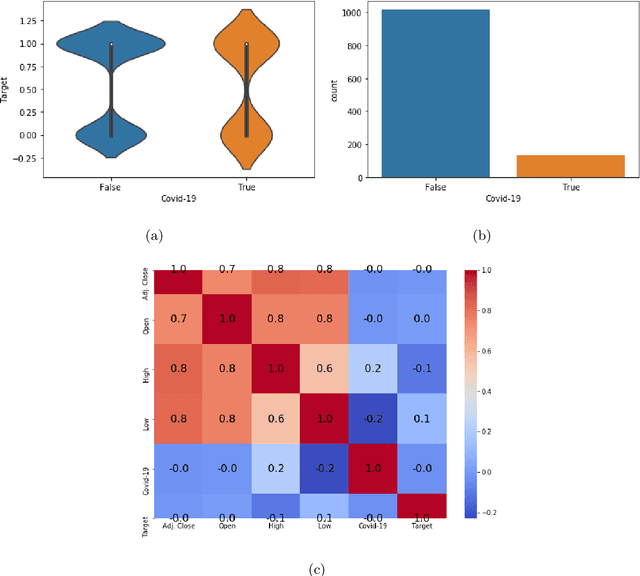
The novel of coronavirus (COVID-19) has suddenly and abruptly changed the world as we knew at the start of the 3rd decade of the 21st century. Particularly, COVID-19 pandemic has negatively affected financial econometrics and stock markets across the globe. Artificial Intelligence (AI) and Machine Learning (ML)-based prediction models, especially Deep Neural Network (DNN) architectures, have the potential to act as a key enabling factor to reduce the adverse effects of the COVID-19 pandemic and future possible ones on financial markets. In this regard, first, a unique COVID-19 related PRIce MOvement prediction (COVID19 PRIMO) dataset is introduced in this paper, which incorporates effects of social media trends related to COVID-19 on stock market price movements. Afterwards, a novel hybrid and parallel DNN-based framework is proposed that integrates different and diversified learning architectures. Referred to as the COVID-19 adopted Hybrid and Parallel deep fusion framework for Stock price Movement Prediction (COVID19-HPSMP), innovative fusion strategies are used to combine scattered social media news related to COVID-19 with historical mark data. The proposed COVID19-HPSMP consists of two parallel paths (hence hybrid), one based on Convolutional Neural Network (CNN) with Local/Global Attention modules, and one integrated CNN and Bi-directional Long Short term Memory (BLSTM) path. The two parallel paths are followed by a multilayer fusion layer acting as a fusion centre that combines localized features. Performance evaluations are performed based on the introduced COVID19 PRIMO dataset illustrating superior performance of the proposed framework.
MM-KTD: Multiple Model Kalman Temporal Differences for Reinforcement Learning
May 30, 2020
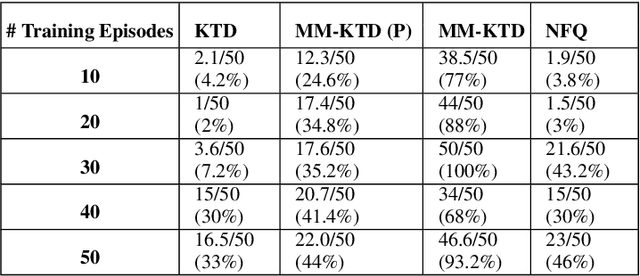
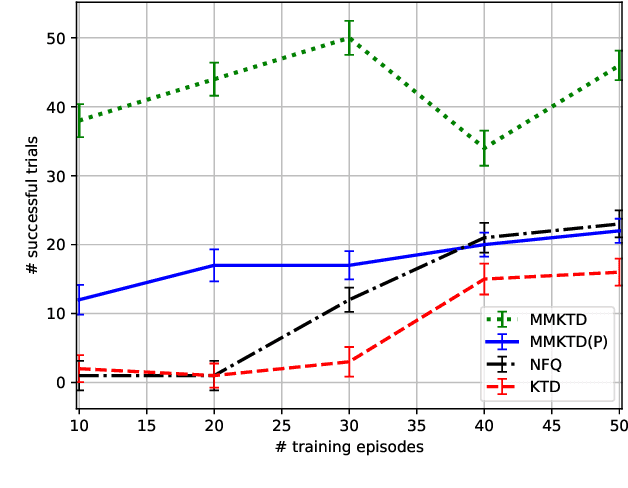
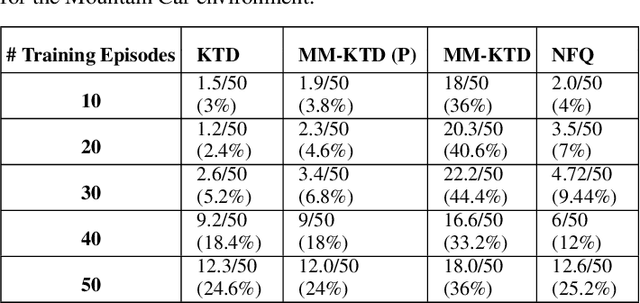
There has been an increasing surge of interest on development of advanced Reinforcement Learning (RL) systems as intelligent approaches to learn optimal control policies directly from smart agents' interactions with the environment. Objectives: In a model-free RL method with continuous state-space, typically, the value function of the states needs to be approximated. In this regard, Deep Neural Networks (DNNs) provide an attractive modeling mechanism to approximate the value function using sample transitions. DNN-based solutions, however, suffer from high sensitivity to parameter selection, are prone to overfitting, and are not very sample efficient. A Kalman-based methodology, on the other hand, could be used as an efficient alternative. Such an approach, however, commonly requires a-priori information about the system (such as noise statistics) to perform efficiently. The main objective of this paper is to address this issue. Methods: As a remedy to the aforementioned problems, this paper proposes an innovative Multiple Model Kalman Temporal Difference (MM-KTD) framework, which adapts the parameters of the filter using the observed states and rewards. Moreover, an active learning method is proposed to enhance the sampling efficiency of the system. More specifically, the estimated uncertainty of the value functions are exploited to form the behaviour policy leading to more visits to less certain values, therefore, improving the overall learning sample efficiency. As a result, the proposed MM-KTD framework can learn the optimal policy with significantly reduced number of samples as compared to its DNN-based counterparts. Results: To evaluate performance of the proposed MM-KTD framework, we have performed a comprehensive set of experiments based on three RL benchmarks. Experimental results show superiority of the MM-KTD framework in comparison to its state-of-the-art counterparts.