 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-KTD: Multiple Model Kalman Temporal Differences for Reinforcement Learning
May 30, 2020
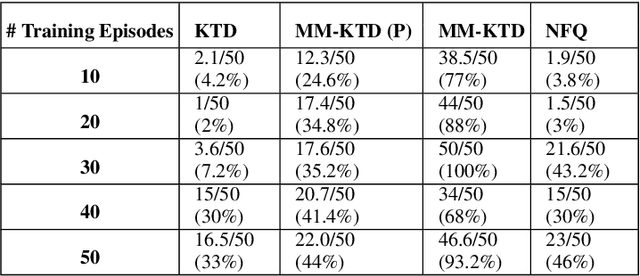
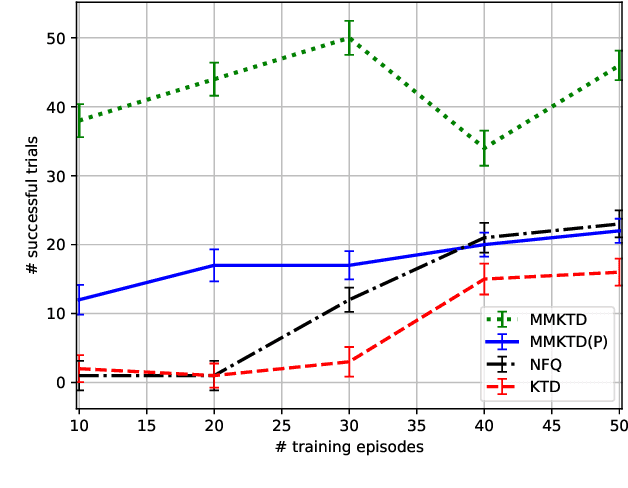
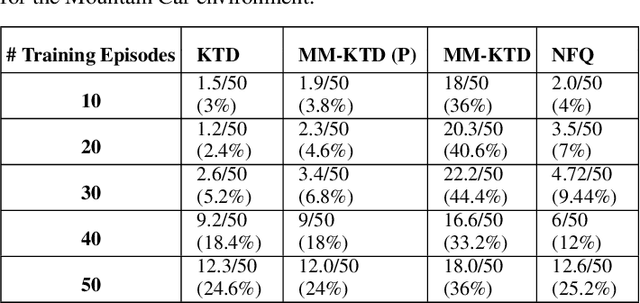
There has been an increasing surge of interest on development of advanced Reinforcement Learning (RL) systems as intelligent approaches to learn optimal control policies directly from smart agents' interactions with the environment. Objectives: In a model-free RL method with continuous state-space, typically, the value function of the states needs to be approximated. In this regard, Deep Neural Networks (DNNs) provide an attractive modeling mechanism to approximate the value function using sample transitions. DNN-based solutions, however, suffer from high sensitivity to parameter selection, are prone to overfitting, and are not very sample efficient. A Kalman-based methodology, on the other hand, could be used as an efficient alternative. Such an approach, however, commonly requires a-priori information about the system (such as noise statistics) to perform efficiently. The main objective of this paper is to address this issue. Methods: As a remedy to the aforementioned problems, this paper proposes an innovative Multiple Model Kalman Temporal Difference (MM-KTD) framework, which adapts the parameters of the filter using the observed states and rewards. Moreover, an active learning method is proposed to enhance the sampling efficiency of the system. More specifically, the estimated uncertainty of the value functions are exploited to form the behaviour policy leading to more visits to less certain values, therefore, improving the overall learning sample efficiency. As a result, the proposed MM-KTD framework can learn the optimal policy with significantly reduced number of samples as compared to its DNN-based counterparts. Results: To evaluate performance of the proposed MM-KTD framework, we have performed a comprehensive set of experiments based on three RL benchmarks. Experimental results show superiority of the MM-KTD framework in comparison to its state-of-the-art counterparts.