 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Reinforcement Learning via Adaptive Kalman Temporal Difference and Successor Representation
Paper and Code
Dec 30, 2021
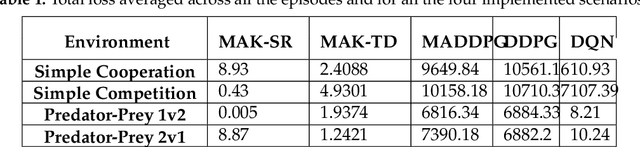
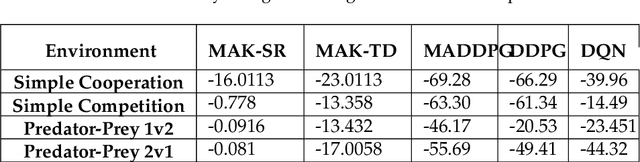
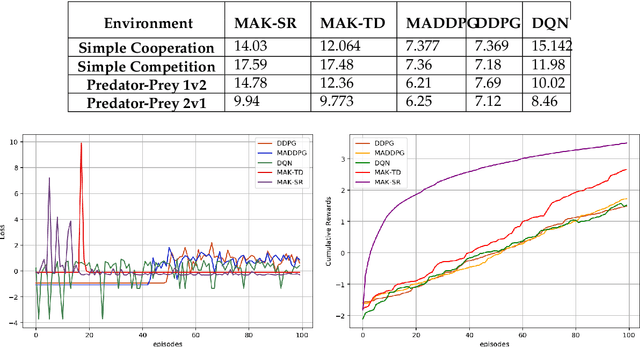
Distributed Multi-Agent Reinforcement Learning (MARL) algorithms has attracted a surge of interest lately mainly due to the recent advancements of Deep Neural Networks (DNNs). Conventional Model-Based (MB) or Model-Free (MF) RL algorithms are not directly applicable to the MARL problems due to utilization of a fixed reward model for learning the underlying value function. While DNN-based solutions perform utterly well when a single agent is involved, such methods fail to fully generalize to the complexities of MARL problems. In other words, although recently developed approaches based on DNNs for multi-agent environments have achieved superior performance, they are still prone to overfiting, high sensitivity to parameter selection, and sample inefficiency. The paper proposes the Multi-Agent Adaptive Kalman Temporal Difference (MAK-TD) framework and its Successor Representation-based variant, referred to as the MAK-SR. Intuitively speaking, the main objective is to capitalize on unique characteristics of Kalman Filtering (KF) such as uncertainty modeling and online second order learning. The proposed MAK-TD/SR frameworks consider the continuous nature of the action-space that is associated with high dimensional multi-agent environments and exploit Kalman Temporal Difference (KTD) to address the parameter uncertainty. By leveraging the KTD framework, SR learning procedure is modeled into a filtering problem, where Radial Basis Function (RBF) estimators are used to encode the continuous space into feature vectors. On the other hand, for learning localized reward functions, we resort to Multiple Model Adaptive Estimation (MMAE), to deal with the lack of prior knowledge on the observation noise covariance and observation mapping function. The proposed MAK-TD/SR frameworks are evaluated via several experiments, which are implemented through the OpenAI Gym MARL benchmarks.