 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrioritized Variable-length Test Cases Generation for Finite State Machines
Apr 03, 2022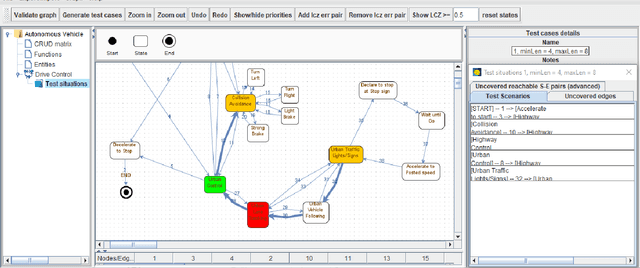
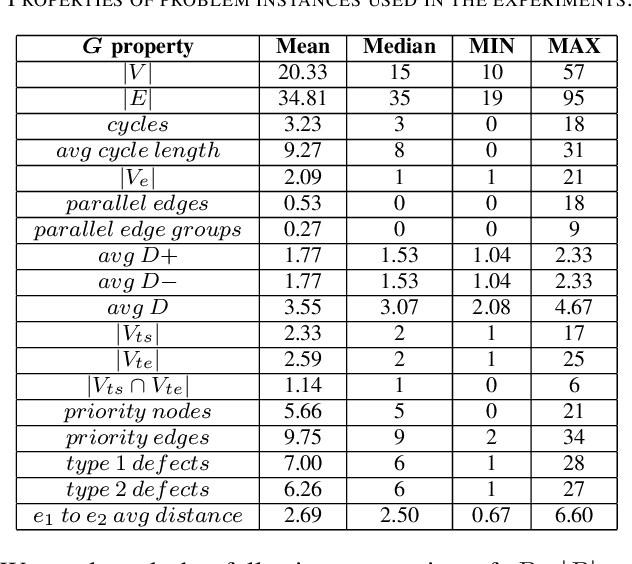
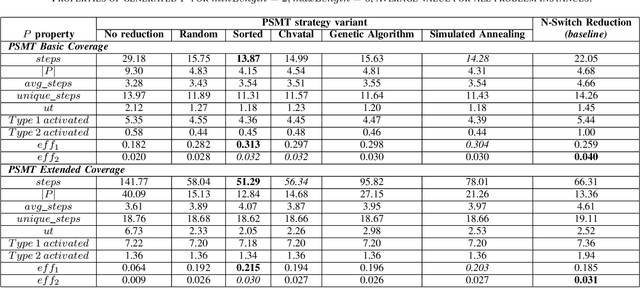
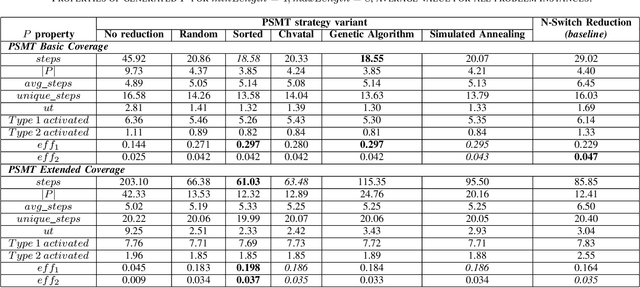
Model-based Testing (MBT) is an effective approach for testing when parts of a system-under-test have the characteristics of a finite state machine (FSM). Despite various strategies in the literature on this topic, little work exists to handle special testing situations. More specifically, when concurrently: (1) the test paths can start and end only in defined states of the FSM, (2) a prioritization mechanism that requires only defined states and transitions of the FSM to be visited by test cases is required, and (3) the test paths must be in a given length range, not necessarily of explicit uniform length. This paper presents a test generation strategy that satisfies all these requirements. A concurrent combination of these requirements is highly practical for real industrial testing. Six variants of possible algorithms to implement this strategy are described. Using a mixture of 180 problem instances from real automotive and defense projects and artificially generated FSMs, all variants are compared with a baseline strategy based on an established N-switch coverage concept modification. Various properties of the generated test paths and their potential to activate fictional defects defined in FSMs are evaluated. The presented strategy outperforms the baseline in most problem configurations. Out of the six analyzed variants, three give the best results even though a universal best performer is hard to identify. Depending on the application of the FSM, the strategy and evaluation presented in this paper are applicable both in testing functional and non-functional software requirements.
Overview of Test Coverage Criteria for Test Case Generation from Finite State Machines Modelled as Directed Graphs
Mar 17, 2022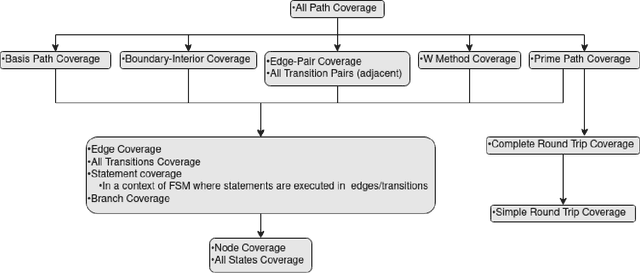
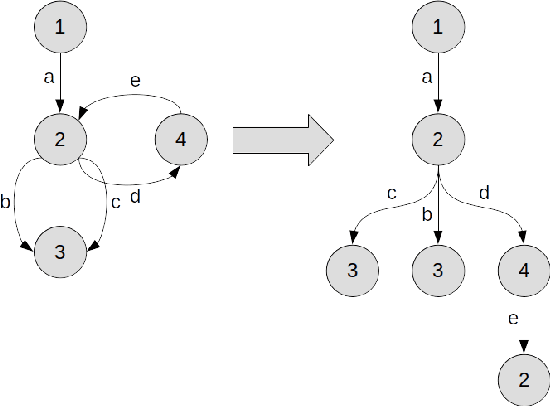
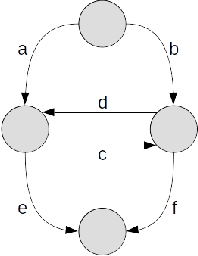
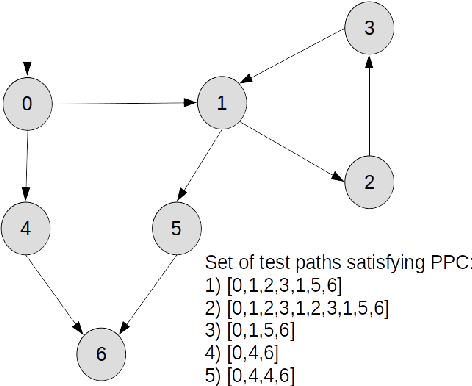
Test Coverage criteria are an essential concept for test engineers when generating the test cases from a System Under Test model. They are routinely used in test case generation for user interfaces, middleware, and back-end system parts for software, electronics, or Internet of Things (IoT) systems. Test Coverage criteria define the number of actions or combinations by which a system is tested, informally determining a potential "strength" of a test set. As no previous study summarized all commonly used test coverage criteria for Finite State Machines and comprehensively discussed them regarding their subsumption, equivalence, or non-comparability, this paper provides this overview. In this study, 14 most common test coverage criteria and seven of their synonyms for Finite State Machines defined via a directed graph are summarized and compared. The results give researchers and industry testing engineers a helpful overview when setting a software-based or IoT system test strategy.
Utilising Flow Aggregation to Classify Benign Imitating Attacks
Mar 06, 2021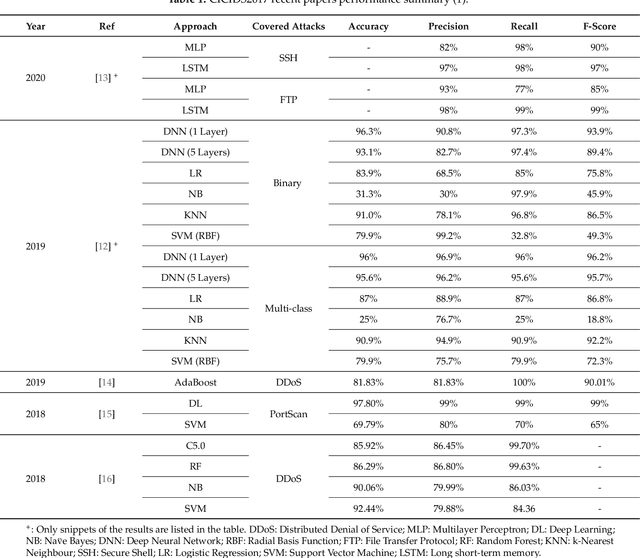
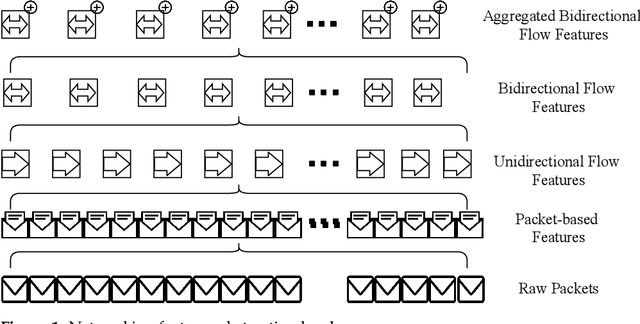
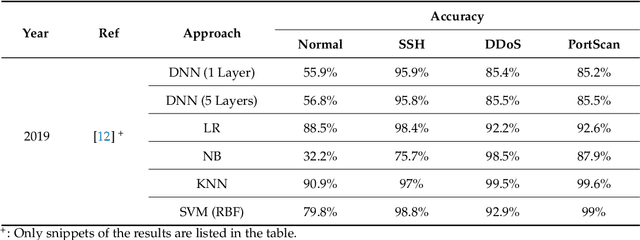
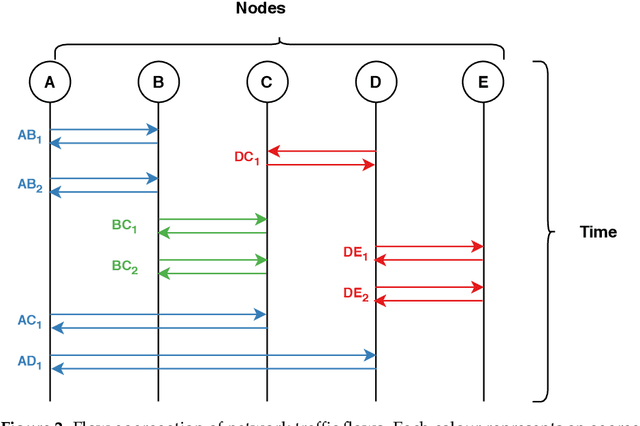
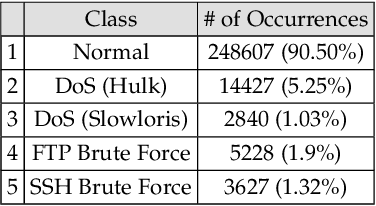
Cyber-attacks continue to grow, both in terms of volume and sophistication. This is aided by an increase in available computational power, expanding attack surfaces, and advancements in the human understanding of how to make attacks undetectable. Unsurprisingly, machine learning is utilised to defend against these attacks. In many applications, the choice of features is more important than the choice of model. A range of studies have, with varying degrees of success, attempted to discriminate between benign traffic and well-known cyber-attacks. The features used in these studies are broadly similar and have demonstrated their effectiveness in situations where cyber-attacks do not imitate benign behaviour. To overcome this barrier, in this manuscript, we introduce new features based on a higher level of abstraction of network traffic. Specifically, we perform flow aggregation by grouping flows with similarities. This additional level of feature abstraction benefits from cumulative information, thus qualifying the models to classify cyber-attacks that mimic benign traffic. The performance of the new features is evaluated using the benchmark CICIDS2017 dataset, and the results demonstrate their validity and effectiveness. This novel proposal will improve the detection accuracy of cyber-attacks and also build towards a new direction of feature extraction for complex ones.
* 21 pages, 6 figures
Leveraging Siamese Networks for One-Shot Intrusion Detection Model
Jun 27, 2020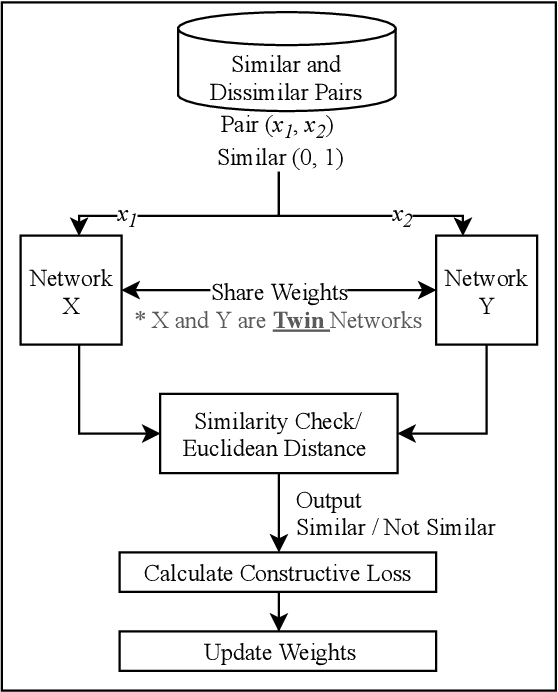

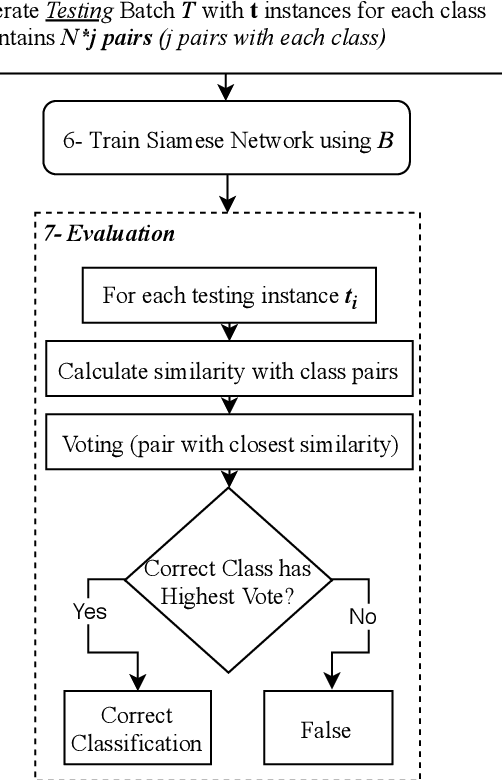
The use of supervised Machine Learning (ML) to enhance Intrusion Detection Systems has been the subject of significant research. Supervised ML is based upon learning by example, demanding significant volumes of representative instances for effective training and the need to re-train the model for every unseen cyber-attack class. However, retraining the models in-situ renders the network susceptible to attacks owing to the time-window required to acquire a sufficient volume of data. Although anomaly detection systems provide a coarse-grained defence against unseen attacks, these approaches are significantly less accurate and suffer from high false-positive rates. Here, a complementary approach referred to as 'One-Shot Learning', whereby a limited number of examples of a new attack-class is used to identify a new attack-class (out of many) is detailed. The model grants a new cyber-attack classification without retraining. A Siamese Network is trained to differentiate between classes based on pairs similarities, rather than features, allowing to identify new and previously unseen attacks. The performance of a pre-trained model to classify attack-classes based only on one example is evaluated using three datasets. Results confirm the adaptability of the model in classifying unseen attacks and the trade-off between performance and the need for distinctive class representation.
A Hybrid Q-Learning Sine-Cosine-based Strategy for Addressing the Combinatorial Test Suite Minimization Problem
Apr 27, 2018


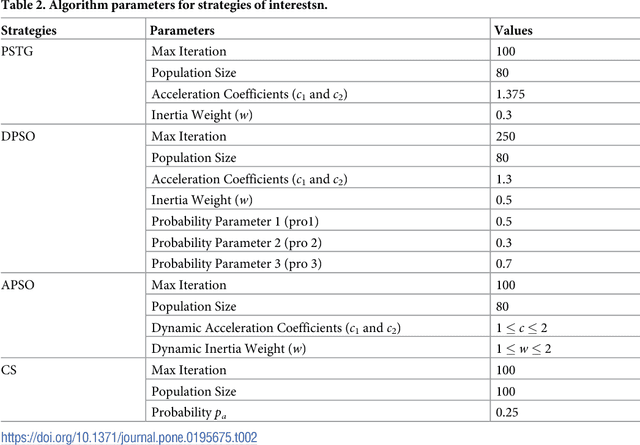
The sine-cosine algorithm (SCA) is a new population-based meta-heuristic algorithm. In addition to exploiting sine and cosine functions to perform local and global searches (hence the name sine-cosine), the SCA introduces several random and adaptive parameters to facilitate the search process. Although it shows promising results, the search process of the SCA is vulnerable to local minima/maxima due to the adoption of a fixed switch probability and the bounded magnitude of the sine and cosine functions (from -1 to 1). In this paper, we propose a new hybrid Q-learning sine-cosine- based strategy, called the Q-learning sine-cosine algorithm (QLSCA). Within the QLSCA, we eliminate the switching probability. Instead, we rely on the Q-learning algorithm (based on the penalty and reward mechanism) to dynamically identify the best operation during runtime. Additionally, we integrate two new operations (L\'evy flight motion and crossover) into the QLSCA to facilitate jumping out of local minima/maxima and enhance the solution diversity. To assess its performance, we adopt the QLSCA for the combinatorial test suite minimization problem. Experimental results reveal that the QLSCA is statistically superior with regard to test suite size reduction compared to recent state-of-the-art strategies, including the original SCA, the particle swarm test generator (PSTG), adaptive particle swarm optimization (APSO) and the cuckoo search strategy (CS) at the 95% confidence level. However, concerning the comparison with discrete particle swarm optimization (DPSO), there is no significant difference in performance at the 95% confidence level. On a positive note, the QLSCA statistically outperforms the DPSO in certain configurations at the 90% confidence level.
* 41 pages