 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlannerRFT: Reinforcing Diffusion Planners through Closed-Loop and Sample-Efficient Fine-Tuning
Jan 19, 2026Diffusion-based planners have emerged as a promising approach for human-like trajectory generation in autonomous driving. Recent works incorporate reinforcement fine-tuning to enhance the robustness of diffusion planners through reward-oriented optimization in a generation-evaluation loop. However, they struggle to generate multi-modal, scenario-adaptive trajectories, hindering the exploitation efficiency of informative rewards during fine-tuning. To resolve this, we propose PlannerRFT, a sample-efficient reinforcement fine-tuning framework for diffusion-based planners. PlannerRFT adopts a dual-branch optimization that simultaneously refines the trajectory distribution and adaptively guides the denoising process toward more promising exploration, without altering the original inference pipeline. To support parallel learning at scale, we develop nuMax, an optimized simulator that achieves 10 times faster rollout compared to native nuPlan. Extensive experiments shows that PlannerRFT yields state-of-the-art performance with distinct behaviors emerging during the learning process.
V2F-Net: Explicit Decomposition of Occluded Pedestrian Detection
Apr 07, 2021
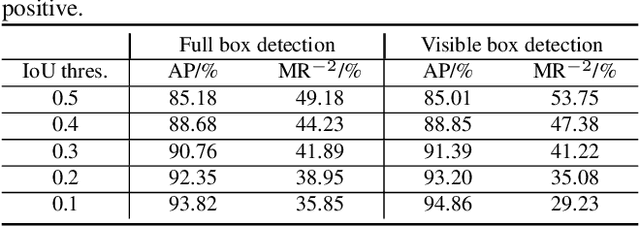
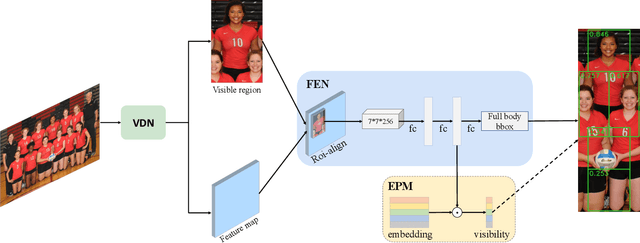

Occlusion is very challenging in pedestrian detection. In this paper, we propose a simple yet effective method named V2F-Net, which explicitly decomposes occluded pedestrian detection into visible region detection and full body estimation. V2F-Net consists of two sub-networks: Visible region Detection Network (VDN) and Full body Estimation Network (FEN). VDN tries to localize visible regions and FEN estimates full-body box on the basis of the visible box. Moreover, to further improve the estimation of full body, we propose a novel Embedding-based Part-aware Module (EPM). By supervising the visibility for each part, the network is encouraged to extract features with essential part information. We experimentally show the effectiveness of V2F-Net by conducting several experiments on two challenging datasets. V2F-Net achieves 5.85% AP gains on CrowdHuman and 2.24% MR-2 improvements on CityPersons compared to FPN baseline. Besides, the consistent gain on both one-stage and two-stage detector validates the generalizability of our method.
Y^2Seq2Seq: Cross-Modal Representation Learning for 3D Shape and Text by Joint Reconstruction and Prediction of View and Word Sequences
Nov 07, 2018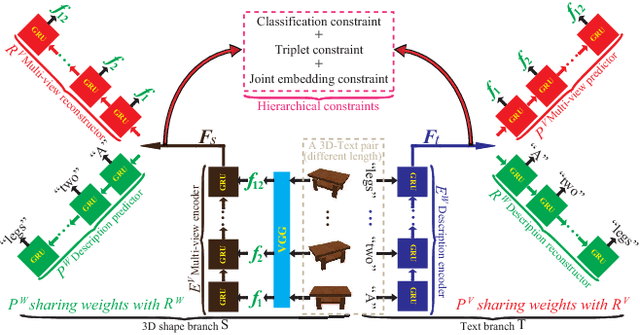

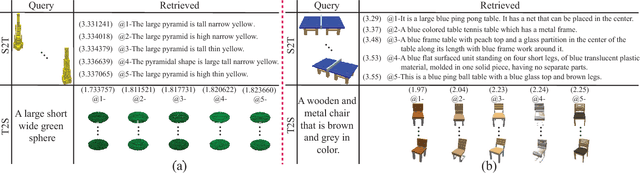
A recent method employs 3D voxels to represent 3D shapes, but this limits the approach to low resolutions due to the computational cost caused by the cubic complexity of 3D voxels. Hence the method suffers from a lack of detailed geometry. To resolve this issue, we propose Y^2Seq2Seq, a view-based model, to learn cross-modal representations by joint reconstruction and prediction of view and word sequences. Specifically, the network architecture of Y^2Seq2Seq bridges the semantic meaning embedded in the two modalities by two coupled `Y' like sequence-to-sequence (Seq2Seq) structures. In addition, our novel hierarchical constraints further increase the discriminability of the cross-modal representations by employing more detailed discriminative information. Experimental results on cross-modal retrieval and 3D shape captioning show that Y^2Seq2Seq outperforms the state-of-the-art methods.
View Inter-Prediction GAN: Unsupervised Representation Learning for 3D Shapes by Learning Global Shape Memories to Support Local View Predictions
Nov 07, 2018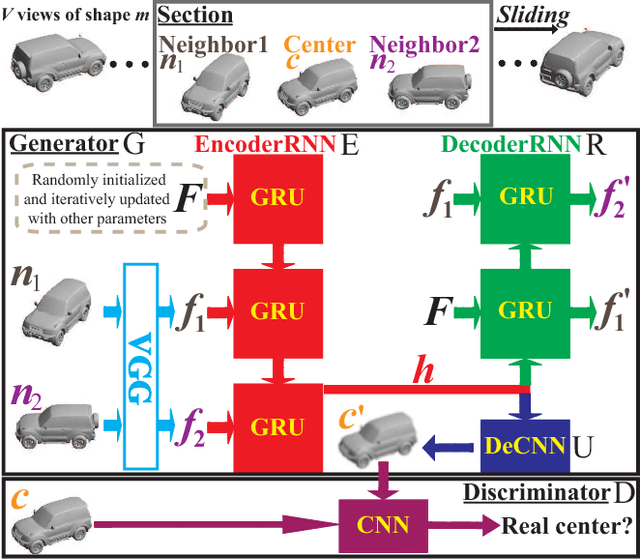

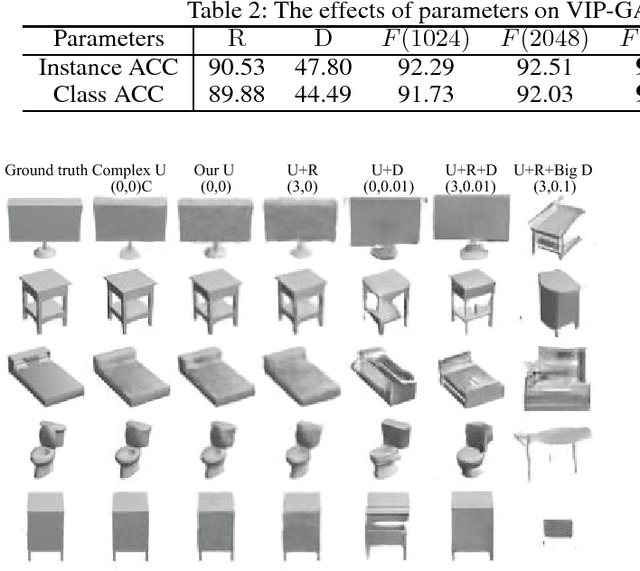

In this paper we present a novel unsupervised representation learning approach for 3D shapes, which is an important research challenge as it avoids the manual effort required for collecting supervised data. Our method trains an RNN-based neural network architecture to solve multiple view inter-prediction tasks for each shape. Given several nearby views of a shape, we define view inter-prediction as the task of predicting the center view between the input views, and reconstructing the input views in a low-level feature space. The key idea of our approach is to implement the shape representation as a shape-specific global memory that is shared between all local view inter-predictions for each shape. Intuitively, this memory enables the system to aggregate information that is useful to better solve the view inter-prediction tasks for each shape, and to leverage the memory as a view-independent shape representation. Our approach obtains the best results using a combination of L_2 and adversarial losses for the view inter-prediction task. We show that VIP-GAN outperforms state-of-the-art methods in unsupervised 3D feature learning on three large scale 3D shape benchmarks.