 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Dynamic Sparsity for Near-Field Spatial Non-Stationary XL-MIMO Channel Tracking
Dec 27, 2024This work considers a spatial non-stationary channel tracking problem in broadband extremely large-scale multiple-input-multiple-output (XL-MIMO) systems. In the case of spatial non-stationary, each scatterer has a certain visibility region (VR) over antennas and power change may occur among visible antennas. Concentrating on the temporal correlation of XL-MIMO channels, we design a three-layer Markov prior model and hierarchical two-dimensional (2D) Markov model to exploit the dynamic sparsity of sparse channel vectors and VRs, respectively. Then, we formulate the channel tracking problem as a bilinear measurement process, and a novel dynamic alternating maximum a posteriori (DA-MAP) framework is developed to solve the problem. The DA-MAP contains four basic modules: channel estimation module, VR detection module, grid update module, and temporal correlated module. Specifically, the first module is an inverse-free variational Bayesian inference (IF-VBI) estimator that avoids computational intensive matrix inverse each iteration; the second module is a turbo compressive sensing (Turbo-CS) algorithm that only needs small-scale matrix operations in a parallel fashion; the third module refines the polar-delay domain grid; and the fourth module can process the temporal prior information to ensure high-efficiency channel tracking. Simulations show that the proposed method can achieve a significant channel tracking performance while achieving low computational overhead.
Joint Visibility Region Detection and Channel Estimation for XL-MIMO Systems via Alternating MAP
May 07, 2024



We investigate a joint visibility region (VR) detection and channel estimation problem in extremely large-scale multiple-input-multiple-output (XL-MIMO) systems, where near-field propagation and spatial non-stationary effects exist. In this case, each scatterer can only see a subset of antennas, i.e., it has a certain VR over the antennas. Because of the spatial correlation among adjacent sub-arrays, VR of scatterers exhibits a two-dimensional (2D) clustered sparsity. We design a 2D Markov prior model to capture such a structured sparsity. Based on this, a novel alternating maximum a posteriori (MAP) framework is developed for high-accuracy VR detection and channel estimation. The alternating MAP framework consists of three basic modules: a channel estimation module, a VR detection module, and a grid update module. Specifically, the first module is a low-complexity inverse-free variational Bayesian inference (IF-VBI) algorithm that avoids the matrix inverse via minimizing a relaxed Kullback-Leibler (KL) divergence. The second module is a structured expectation propagation (EP) algorithm which has the ability to deal with complicated prior information. And the third module refines polar-domain grid parameters via gradient ascent. Simulations demonstrate the superiority of the proposed algorithm in both VR detection and channel estimation.
Learned Conjugate Gradient Descent Network for Massive MIMO Detection
Jun 11, 2019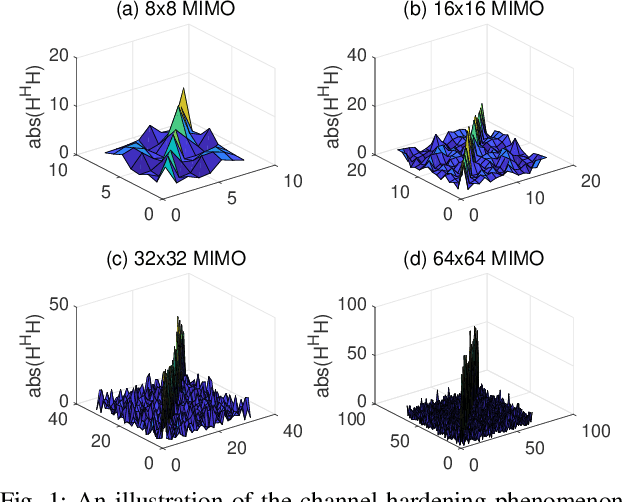
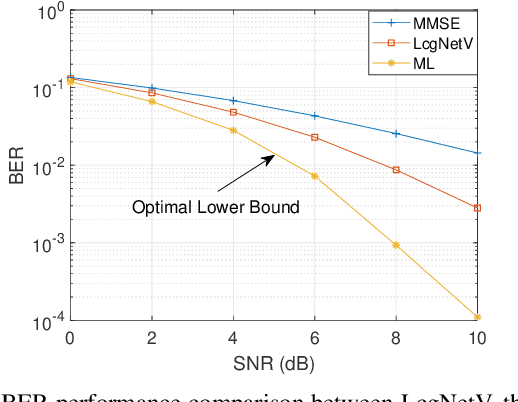
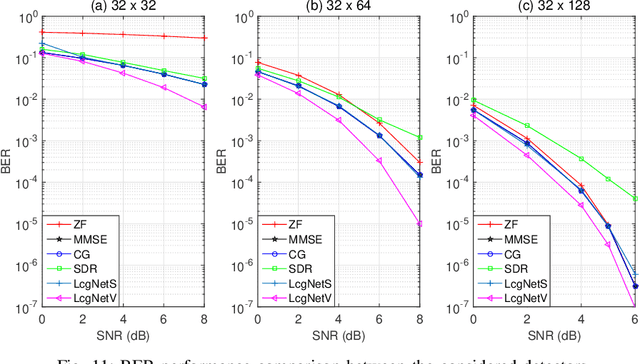
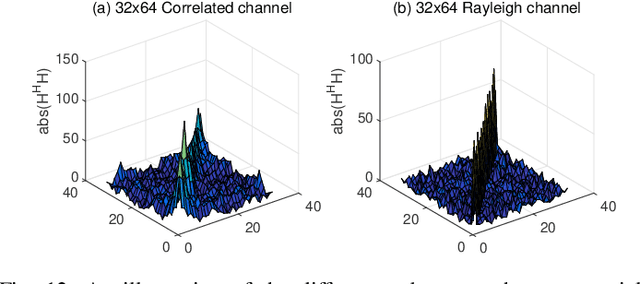
In this work, we consider the use of model-driven deep learning techniques for massive multiple-input multiple-output (MIMO) detection. Compared with conventional MIMO systems, massive MIMO promises improved spectral efficiency, coverage and range. Unfortunately, these benefits are coming at the cost of significantly increased computational complexity. To reduce the complexity of signal detection and guarantee the performance, we present a learned conjugate gradient descent network (LcgNet), which is constructed by unfolding the iterative conjugate gradient descent (CG) detector. In the proposed network, instead of calculating the exact values of the scalar step-sizes, we explicitly learn their universal values. Also, we can enhance the proposed network by augmenting the dimensions of these step-sizes. Furthermore, in order to reduce the memory costs, a novel quantized LcgNet is proposed, where a low-resolution nonuniform quantizer is integrated into the LcgNet to smartly quantize the aforementioned step-sizes. The quantizer is based on a specially designed soft staircase function with learnable parameters to adjust its shape. Meanwhile, due to fact that the number of learnable parameters is limited, the proposed networks are easy and fast to train. Numerical results demonstrate that the proposed network can achieve promising performance with much lower complexity.