 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCanonical Space Representation for 4D Panoptic Segmentation of Articulated Objects
Nov 07, 2025Articulated object perception presents significant challenges in computer vision, particularly because most existing methods ignore temporal dynamics despite the inherently dynamic nature of such objects. The use of 4D temporal data has not been thoroughly explored in articulated object perception and remains unexamined for panoptic segmentation. The lack of a benchmark dataset further hurt this field. To this end, we introduce Artic4D as a new dataset derived from PartNet Mobility and augmented with synthetic sensor data, featuring 4D panoptic annotations and articulation parameters. Building on this dataset, we propose CanonSeg4D, a novel 4D panoptic segmentation framework. This approach explicitly estimates per-frame offsets mapping observed object parts to a learned canonical space, thereby enhancing part-level segmentation. The framework employs this canonical representation to achieve consistent alignment of object parts across sequential frames. Comprehensive experiments on Artic4D demonstrate that the proposed CanonSeg4D outperforms state of the art approaches in panoptic segmentation accuracy in more complex scenarios. These findings highlight the effectiveness of temporal modeling and canonical alignment in dynamic object understanding, and pave the way for future advances in 4D articulated object perception.
The Impact of Prosodic Segmentation on Speech Synthesis of Spontaneous Speech
Nov 06, 2025Spontaneous speech presents several challenges for speech synthesis, particularly in capturing the natural flow of conversation, including turn-taking, pauses, and disfluencies. Although speech synthesis systems have made significant progress in generating natural and intelligible speech, primarily through architectures that implicitly model prosodic features such as pitch, intensity, and duration, the construction of datasets with explicit prosodic segmentation and their impact on spontaneous speech synthesis remains largely unexplored. This paper evaluates the effects of manual and automatic prosodic segmentation annotations in Brazilian Portuguese on the quality of speech synthesized by a non-autoregressive model, FastSpeech 2. Experimental results show that training with prosodic segmentation produced slightly more intelligible and acoustically natural speech. While automatic segmentation tends to create more regular segments, manual prosodic segmentation introduces greater variability, which contributes to more natural prosody. Analysis of neutral declarative utterances showed that both training approaches reproduced the expected nuclear accent pattern, but the prosodic model aligned more closely with natural pre-nuclear contours. To support reproducibility and future research, all datasets, source codes, and trained models are publicly available under the CC BY-NC-ND 4.0 license.
Joint Perception and Prediction for Autonomous Driving: A Survey
Dec 18, 2024Perception and prediction modules are critical components of autonomous driving systems, enabling vehicles to navigate safely through complex environments. The perception module is responsible for perceiving the environment, including static and dynamic objects, while the prediction module is responsible for predicting the future behavior of these objects. These modules are typically divided into three tasks: object detection, object tracking, and motion prediction. Traditionally, these tasks are developed and optimized independently, with outputs passed sequentially from one to the next. However, this approach has significant limitations: computational resources are not shared across tasks, the lack of joint optimization can amplify errors as they propagate throughout the pipeline, and uncertainty is rarely propagated between modules, resulting in significant information loss. To address these challenges, the joint perception and prediction paradigm has emerged, integrating perception and prediction into a unified model through multi-task learning. This strategy not only overcomes the limitations of previous methods, but also enables the three tasks to have direct access to raw sensor data, allowing richer and more nuanced environmental interpretations. This paper presents the first comprehensive survey of joint perception and prediction for autonomous driving. We propose a taxonomy that categorizes approaches based on input representation, scene context modeling, and output representation, highlighting their contributions and limitations. Additionally, we present a qualitative analysis and quantitative comparison of existing methods. Finally, we discuss future research directions based on identified gaps in the state-of-the-art.
PRIBOOT: A New Data-Driven Expert for Improved Driving Simulations
Jun 12, 2024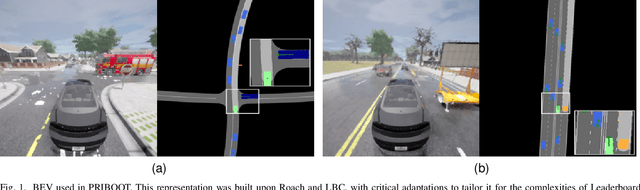
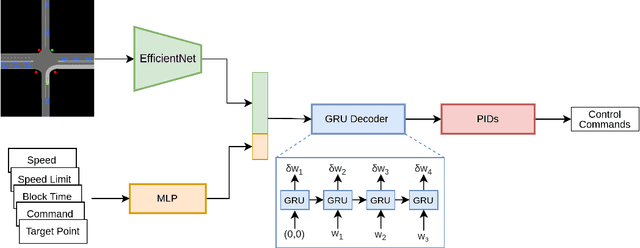
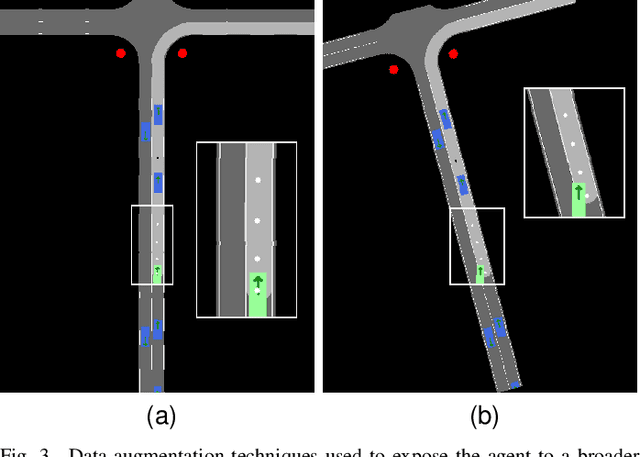

The development of Autonomous Driving (AD) systems in simulated environments like CARLA is crucial for advancing real-world automotive technologies. To drive innovation, CARLA introduced Leaderboard 2.0, significantly more challenging than its predecessor. However, current AD methods have struggled to achieve satisfactory outcomes due to a lack of sufficient ground truth data. Human driving logs provided by CARLA are insufficient, and previously successful expert agents like Autopilot and Roach, used for collecting datasets, have seen reduced effectiveness under these more demanding conditions. To overcome these data limitations, we introduce PRIBOOT, an expert agent that leverages limited human logs with privileged information. We have developed a novel BEV representation specifically tailored to meet the demands of this new benchmark and processed it as an RGB image to facilitate the application of transfer learning techniques, instead of using a set of masks. Additionally, we propose the Infraction Rate Score (IRS), a new evaluation metric designed to provide a more balanced assessment of driving performance over extended routes. PRIBOOT is the first model to achieve a Route Completion (RC) of 75% in Leaderboard 2.0, along with a Driving Score (DS) and IRS of 20% and 45%, respectively. With PRIBOOT, researchers can now generate extensive datasets, potentially solving the data availability issues that have hindered progress in this benchmark.
Volumetric Occupancy Detection: A Comparative Analysis of Mapping Algorithms
Jul 06, 2023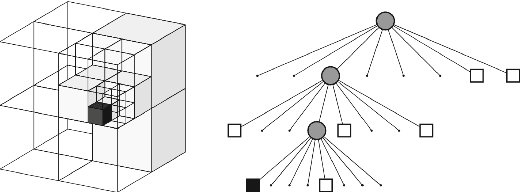
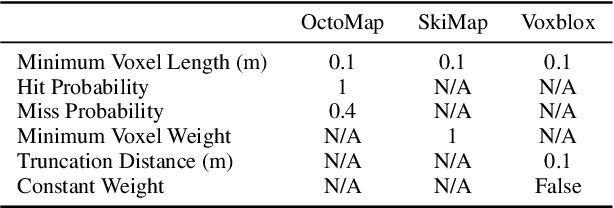
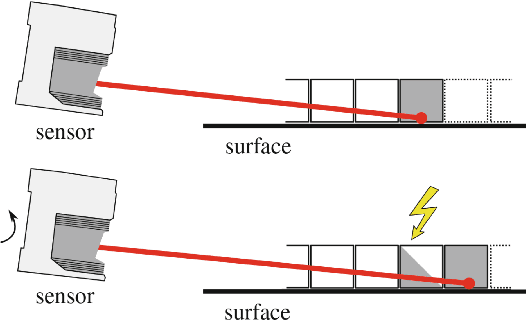
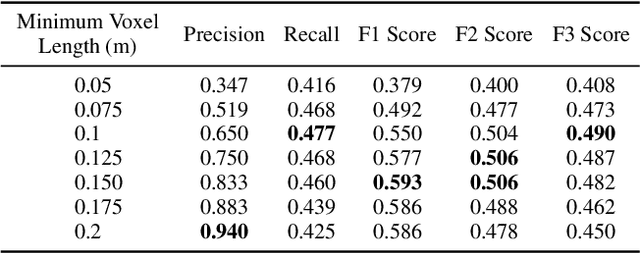
Despite the growing interest in innovative functionalities for collaborative robotics, volumetric detection remains indispensable for ensuring basic security. However, there is a lack of widely used volumetric detection frameworks specifically tailored to this domain, and existing evaluation metrics primarily focus on time and memory efficiency. To bridge this gap, the authors present a detailed comparison using a simulation environment, ground truth extraction, and automated evaluation metrics calculation. This enables the evaluation of state-of-the-art volumetric mapping algorithms, including OctoMap, SkiMap, and Voxblox, providing valuable insights and comparisons through the impact of qualitative and quantitative analyses. The study not only compares different frameworks but also explores various parameters within each framework, offering additional insights into their performance.
RLAD: Reinforcement Learning from Pixels for Autonomous Driving in Urban Environments
May 29, 2023Current approaches of Reinforcement Learning (RL) applied in urban Autonomous Driving (AD) focus on decoupling the perception training from the driving policy training. The main reason is to avoid training a convolution encoder alongside a policy network, which is known to have issues related to sample efficiency, degenerated feature representations, and catastrophic self-overfitting. However, this paradigm can lead to representations of the environment that are not aligned with the downstream task, which may result in suboptimal performances. To address this limitation, this paper proposes RLAD, the first Reinforcement Learning from Pixels (RLfP) method applied in the urban AD domain. We propose several techniques to enhance the performance of an RLfP algorithm in this domain, including: i) an image encoder that leverages both image augmentations and Adaptive Local Signal Mixing (A-LIX) layers; ii) WayConv1D, which is a waypoint encoder that harnesses the 2D geometrical information of the waypoints using 1D convolutions; and iii) an auxiliary loss to increase the significance of the traffic lights in the latent representation of the environment. Experimental results show that RLAD significantly outperforms all state-of-the-art RLfP methods on the NoCrash benchmark. We also present an infraction analysis on the NoCrash-regular benchmark, which indicates that RLAD performs better than all other methods in terms of both collision rate and red light infractions.
Synfeal: A Data-Driven Simulator for End-to-End Camera Localization
May 29, 2023



Collecting real-world data is often considered the bottleneck of Artificial Intelligence, stalling the research progress in several fields, one of which is camera localization. End-to-end camera localization methods are still outperformed by traditional methods, and we argue that the inconsistencies associated with the data collection techniques are restraining the potential of end-to-end methods. Inspired by the recent data-centric paradigm, we propose a framework that synthesizes large localization datasets based on realistic 3D reconstructions of the real world. Our framework, termed Synfeal: Synthetic from Real, is an open-source, data-driven simulator that synthesizes RGB images by moving a virtual camera through a realistic 3D textured mesh, while collecting the corresponding ground-truth camera poses. The results validate that the training of camera localization algorithms on datasets generated by Synfeal leads to better results when compared to datasets generated by state-of-the-art methods. Using Synfeal, we conducted the first analysis of the relationship between the size of the dataset and the performance of camera localization algorithms. Results show that the performance significantly increases with the dataset size. Our results also suggest that when a large localization dataset with high quality is available, training from scratch leads to better performances. Synfeal is publicly available at https://github.com/DanielCoelho112/synfeal.
A sensor-to-pattern calibration framework for multi-modal industrial collaborative cells
Oct 19, 2022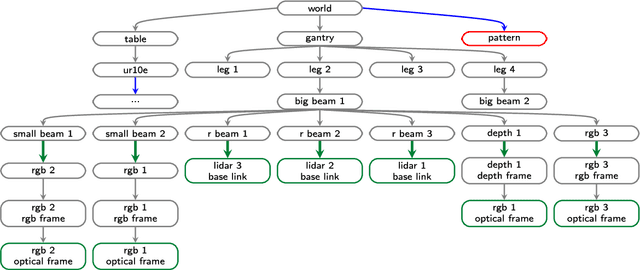

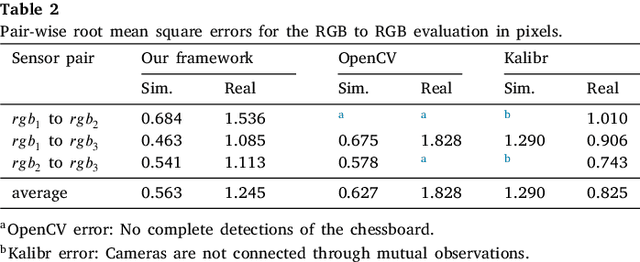
Collaborative robotic industrial cells are workspaces where robots collaborate with human operators. In this context, safety is paramount, and for that a complete perception of the space where the collaborative robot is inserted is necessary. To ensure this, collaborative cells are equipped with a large set of sensors of multiple modalities, covering the entire work volume. However, the fusion of information from all these sensors requires an accurate extrinsic calibration. The calibration of such complex systems is challenging, due to the number of sensors and modalities, and also due to the small overlapping fields of view between the sensors, which are positioned to capture different viewpoints of the cell. This paper proposes a sensor to pattern methodology that can calibrate a complex system such as a collaborative cell in a single optimization procedure. Our methodology can tackle RGB and Depth cameras, as well as LiDARs. Results show that our methodology is able to accurately calibrate a collaborative cell containing three RGB cameras, a depth camera and three 3D LiDARs.
* Journal of Manufacturing Systems