 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRIBOOT: A New Data-Driven Expert for Improved Driving Simulations
Jun 12, 2024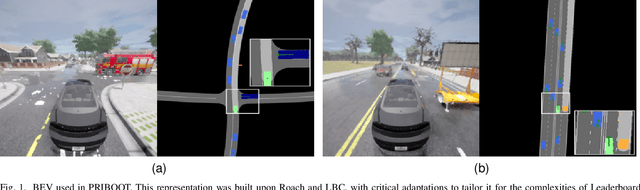
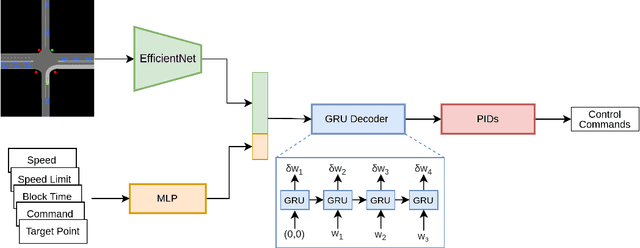
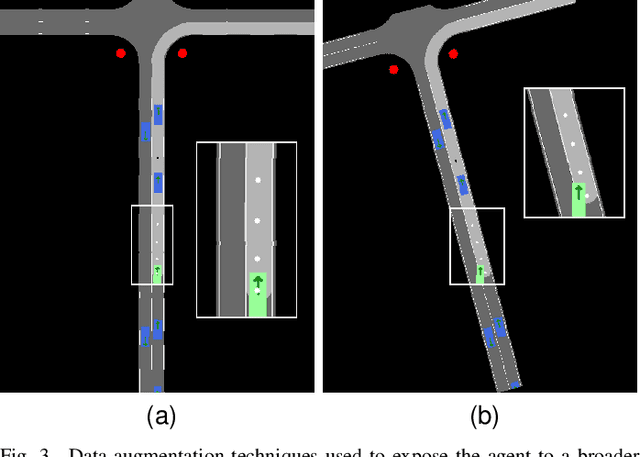

The development of Autonomous Driving (AD) systems in simulated environments like CARLA is crucial for advancing real-world automotive technologies. To drive innovation, CARLA introduced Leaderboard 2.0, significantly more challenging than its predecessor. However, current AD methods have struggled to achieve satisfactory outcomes due to a lack of sufficient ground truth data. Human driving logs provided by CARLA are insufficient, and previously successful expert agents like Autopilot and Roach, used for collecting datasets, have seen reduced effectiveness under these more demanding conditions. To overcome these data limitations, we introduce PRIBOOT, an expert agent that leverages limited human logs with privileged information. We have developed a novel BEV representation specifically tailored to meet the demands of this new benchmark and processed it as an RGB image to facilitate the application of transfer learning techniques, instead of using a set of masks. Additionally, we propose the Infraction Rate Score (IRS), a new evaluation metric designed to provide a more balanced assessment of driving performance over extended routes. PRIBOOT is the first model to achieve a Route Completion (RC) of 75% in Leaderboard 2.0, along with a Driving Score (DS) and IRS of 20% and 45%, respectively. With PRIBOOT, researchers can now generate extensive datasets, potentially solving the data availability issues that have hindered progress in this benchmark.
A community palm model
May 01, 2024Palm oil production has been identified as one of the major drivers of deforestation for tropical countries. To meet supply chain objectives, commodity producers and other stakeholders need timely information of land cover dynamics in their supply shed. However, such data are difficult to obtain from suppliers who may lack digital geographic representations of their supply sheds and production locations. Here we present a "community model," a machine learning model trained on pooled data sourced from many different stakeholders, to develop a specific land cover probability map, in this case a semi-global oil palm map. An advantage of this method is the inclusion of varied inputs, the ability to easily update the model as new training data becomes available and run the model on any year that input imagery is available. Inclusion of diverse data sources into one probability map can help establish a shared understanding across stakeholders on the presence and absence of a land cover or commodity (in this case oil palm). The model predictors are annual composites built from publicly available satellite imagery provided by Sentinel-1, Sentinel-2, and ALOS DSM. We provide map outputs as the probability of palm in a given pixel, to reflect the uncertainty of the underlying state (palm or not palm). The initial version of this model provides global accuracy estimated to be approximately 90% (at 0.5 probability threshold) from spatially partitioned test data. This model, and resulting oil palm probability map products are useful for accurately identifying the geographic footprint of palm cultivation. Used in conjunction with timely deforestation information, this palm model is useful for understanding the risk of continued oil palm plantation expansion in sensitive forest areas.
RLAD: Reinforcement Learning from Pixels for Autonomous Driving in Urban Environments
May 29, 2023Current approaches of Reinforcement Learning (RL) applied in urban Autonomous Driving (AD) focus on decoupling the perception training from the driving policy training. The main reason is to avoid training a convolution encoder alongside a policy network, which is known to have issues related to sample efficiency, degenerated feature representations, and catastrophic self-overfitting. However, this paradigm can lead to representations of the environment that are not aligned with the downstream task, which may result in suboptimal performances. To address this limitation, this paper proposes RLAD, the first Reinforcement Learning from Pixels (RLfP) method applied in the urban AD domain. We propose several techniques to enhance the performance of an RLfP algorithm in this domain, including: i) an image encoder that leverages both image augmentations and Adaptive Local Signal Mixing (A-LIX) layers; ii) WayConv1D, which is a waypoint encoder that harnesses the 2D geometrical information of the waypoints using 1D convolutions; and iii) an auxiliary loss to increase the significance of the traffic lights in the latent representation of the environment. Experimental results show that RLAD significantly outperforms all state-of-the-art RLfP methods on the NoCrash benchmark. We also present an infraction analysis on the NoCrash-regular benchmark, which indicates that RLAD performs better than all other methods in terms of both collision rate and red light infractions.
Synfeal: A Data-Driven Simulator for End-to-End Camera Localization
May 29, 2023



Collecting real-world data is often considered the bottleneck of Artificial Intelligence, stalling the research progress in several fields, one of which is camera localization. End-to-end camera localization methods are still outperformed by traditional methods, and we argue that the inconsistencies associated with the data collection techniques are restraining the potential of end-to-end methods. Inspired by the recent data-centric paradigm, we propose a framework that synthesizes large localization datasets based on realistic 3D reconstructions of the real world. Our framework, termed Synfeal: Synthetic from Real, is an open-source, data-driven simulator that synthesizes RGB images by moving a virtual camera through a realistic 3D textured mesh, while collecting the corresponding ground-truth camera poses. The results validate that the training of camera localization algorithms on datasets generated by Synfeal leads to better results when compared to datasets generated by state-of-the-art methods. Using Synfeal, we conducted the first analysis of the relationship between the size of the dataset and the performance of camera localization algorithms. Results show that the performance significantly increases with the dataset size. Our results also suggest that when a large localization dataset with high quality is available, training from scratch leads to better performances. Synfeal is publicly available at https://github.com/DanielCoelho112/synfeal.