 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Perception and Prediction for Autonomous Driving: A Survey
Dec 18, 2024Perception and prediction modules are critical components of autonomous driving systems, enabling vehicles to navigate safely through complex environments. The perception module is responsible for perceiving the environment, including static and dynamic objects, while the prediction module is responsible for predicting the future behavior of these objects. These modules are typically divided into three tasks: object detection, object tracking, and motion prediction. Traditionally, these tasks are developed and optimized independently, with outputs passed sequentially from one to the next. However, this approach has significant limitations: computational resources are not shared across tasks, the lack of joint optimization can amplify errors as they propagate throughout the pipeline, and uncertainty is rarely propagated between modules, resulting in significant information loss. To address these challenges, the joint perception and prediction paradigm has emerged, integrating perception and prediction into a unified model through multi-task learning. This strategy not only overcomes the limitations of previous methods, but also enables the three tasks to have direct access to raw sensor data, allowing richer and more nuanced environmental interpretations. This paper presents the first comprehensive survey of joint perception and prediction for autonomous driving. We propose a taxonomy that categorizes approaches based on input representation, scene context modeling, and output representation, highlighting their contributions and limitations. Additionally, we present a qualitative analysis and quantitative comparison of existing methods. Finally, we discuss future research directions based on identified gaps in the state-of-the-art.
Volumetric Occupancy Detection: A Comparative Analysis of Mapping Algorithms
Jul 06, 2023Despite the growing interest in innovative functionalities for collaborative robotics, volumetric detection remains indispensable for ensuring basic security. However, there is a lack of widely used volumetric detection frameworks specifically tailored to this domain, and existing evaluation metrics primarily focus on time and memory efficiency. To bridge this gap, the authors present a detailed comparison using a simulation environment, ground truth extraction, and automated evaluation metrics calculation. This enables the evaluation of state-of-the-art volumetric mapping algorithms, including OctoMap, SkiMap, and Voxblox, providing valuable insights and comparisons through the impact of qualitative and quantitative analyses. The study not only compares different frameworks but also explores various parameters within each framework, offering additional insights into their performance.
A sensor-to-pattern calibration framework for multi-modal industrial collaborative cells
Oct 19, 2022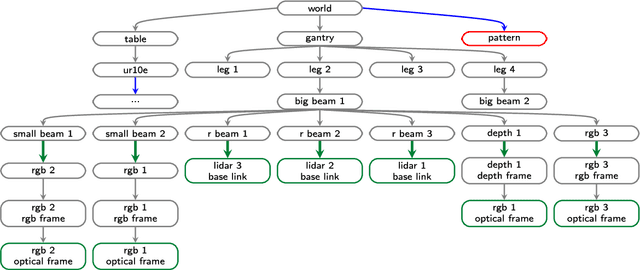
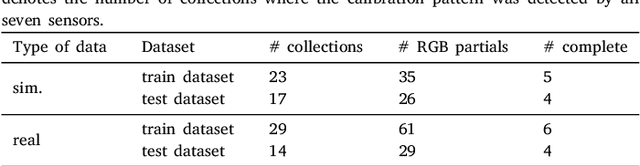

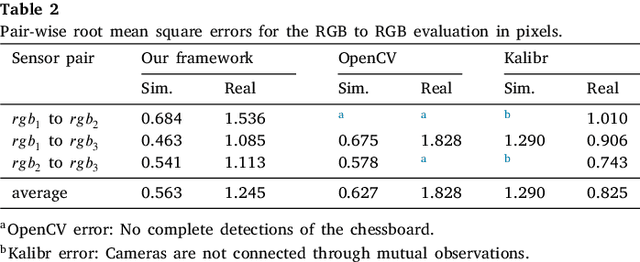
Collaborative robotic industrial cells are workspaces where robots collaborate with human operators. In this context, safety is paramount, and for that a complete perception of the space where the collaborative robot is inserted is necessary. To ensure this, collaborative cells are equipped with a large set of sensors of multiple modalities, covering the entire work volume. However, the fusion of information from all these sensors requires an accurate extrinsic calibration. The calibration of such complex systems is challenging, due to the number of sensors and modalities, and also due to the small overlapping fields of view between the sensors, which are positioned to capture different viewpoints of the cell. This paper proposes a sensor to pattern methodology that can calibrate a complex system such as a collaborative cell in a single optimization procedure. Our methodology can tackle RGB and Depth cameras, as well as LiDARs. Results show that our methodology is able to accurately calibrate a collaborative cell containing three RGB cameras, a depth camera and three 3D LiDARs.
* Journal of Manufacturing Systems