 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimplicity Lies in the Eye of the Beholder: A Strategic Perspective on Controllers in Reactive Synthesis
Sep 04, 2025In the game-theoretic approach to controller synthesis, we model the interaction between a system to be controlled and its environment as a game between these entities, and we seek an appropriate (e.g., winning or optimal) strategy for the system. This strategy then serves as a formal blueprint for a real-world controller. A common belief is that simple (e.g., using limited memory) strategies are better: corresponding controllers are easier to conceive and understand, and cheaper to produce and maintain. This invited contribution focuses on the complexity of strategies in a variety of synthesis contexts. We discuss recent results concerning memory and randomness, and take a brief look at what lies beyond our traditional notions of complexity for strategies.
Mixing Any Cocktail with Limited Ingredients: On the Structure of Payoff Sets in Multi-Objective MDPs and its Impact on Randomised Strategies
Feb 25, 2025We consider multi-dimensional payoff functions in Markov decision processes, and ask whether a given expected payoff vector can be achieved or not. In general, pure strategies (i.e., not resorting to randomisation) do not suffice for this problem. We study the structure of the set of expected payoff vectors of all strategies given a multi-dimensional payoff function and its consequences regarding randomisation requirements for strategies. In particular, we prove that for any payoff for which the expectation is well-defined under all strategies, it is sufficient to mix (i.e., randomly select a pure strategy at the start of a play and committing to it for the rest of the play) finitely many pure strategies to approximate any expected payoff vector up to any precision. Furthermore, for any payoff for which the expected payoff is finite under all strategies, any expected payoff can be obtained exactly by mixing finitely many strategies.
Games Where You Can Play Optimally with Finite Memory
Jan 12, 2020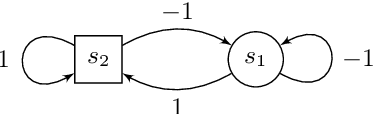
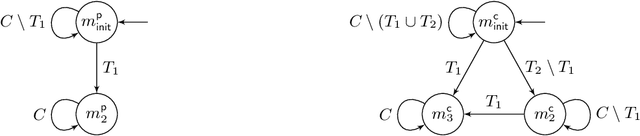
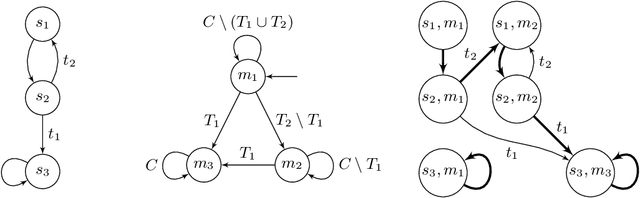
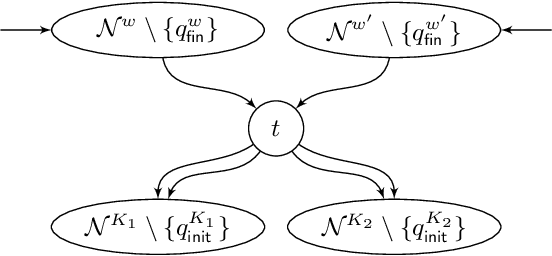
For decades, two-player (antagonistic) games on graphs have been a framework of choice for many important problems in theoretical computer science. A notorious one is controller synthesis, which can be rephrased through the game-theoretic metaphor as the quest for a winning strategy of the system in a game against its antagonistic environment. Depending on the specification, optimal strategies might be simple or quite complex, for example having to use (possibly infinite) memory. Hence, research strives to understand which settings allow for simple strategies. In 2005, Gimbert and Zielonka provided a complete characterization of preference relations (a formal framework to model specifications and game objectives) that admit memoryless optimal strategies for both players. In the last fifteen years however, practical applications have driven the community toward games with complex or multiple objectives, where memory --- finite or infinite --- is almost always required. Despite much effort, the exact frontiers of the class of preference relations that admit finite-memory optimal strategies still elude us. In this work, we establish a complete characterization of preference relations that admit optimal strategies using arena-independent finite memory, generalizing the work of Gimbert and Zielonka to the finite-memory case. We also prove an equivalent to their celebrated corollary of utmost practical interest: if both players have optimal (arena-independent-)finite-memory strategies in all one-player games, then it is also the case in all two-player games. Finally, we pinpoint the boundaries of our results with regard to the literature: our work completely covers the case of arena-independent memory (e.g., multiple parity objectives, lower- and upper-bounded energy objectives), and paves the way to the arena-dependent case (e.g., multiple lower-bounded energy objectives).
Simple Strategies in Multi-Objective MDPs (Technical Report)
Oct 25, 2019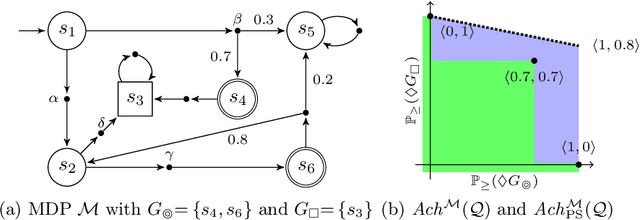
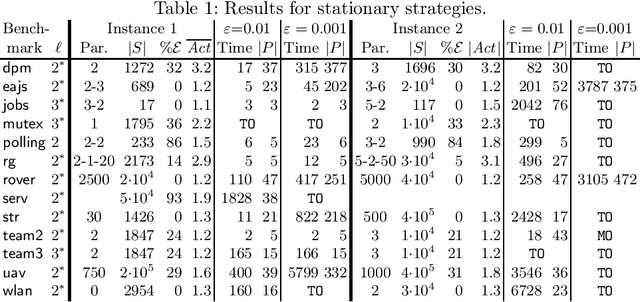
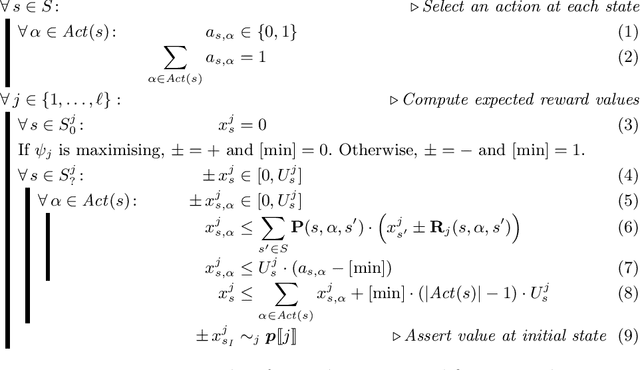
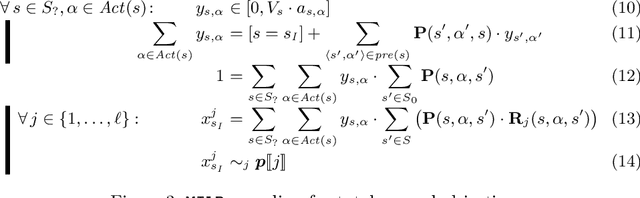
We consider the verification of multiple expected reward objectives at once on Markov decision processes (MDPs). This enables a trade-off analysis among multiple objectives by obtaining the Pareto front. We focus on strategies that are easy to employ and implement. That is, strategies that are pure (no randomization) and have bounded memory. We show that checking whether a point is achievable by a pure stationary strategy is NP-complete, even for two objectives, and we provide an MILP encoding to solve the corresponding problem. The bounded memory case can be reduced to the stationary one by a product construction. Experimental results using \Storm and Gurobi show the feasibility of our algorithms.
Life is Random, Time is Not: Markov Decision Processes with Window Objectives
Jan 11, 2019

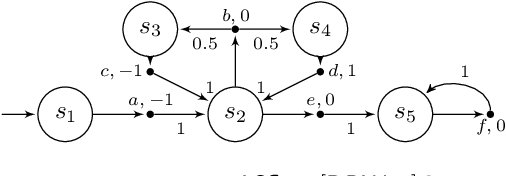
The window mechanism was introduced by Chatterjee et al. [1] to strengthen classical game objectives with time bounds. It permits to synthesize system controllers that exhibit acceptable behaviors within a configurable time frame, all along their infinite execution, in contrast to the traditional objectives that only require correctness of behaviors in the limit. The window concept has proved its interest in a variety of two-player zero-sum games, thanks to the ability to reason about such time bounds in system specifications, but also the increased tractability that it usually yields. In this work, we extend the window framework to stochastic environments by considering the fundamental threshold probability problem in Markov decision processes for window objectives. That is, given such an objective, we want to synthesize strategies that guarantee satisfying runs with a given probability. We solve this problem for the usual variants of window objectives, where either the time frame is set as a parameter, or we ask if such a time frame exists. We develop a generic approach for window-based objectives and instantiate it for the classical mean-payoff and parity objectives, already considered in games. Our work paves the way to a wide use of the window mechanism in stochastic models. [1] Krishnendu Chatterjee, Laurent Doyen, Mickael Randour, and Jean-Fran\c{c}ois Raskin. Looking at mean-payoff and total-payoff through windows. Inf. Comput., 242:25-52, 2015.
Threshold Constraints with Guarantees for Parity Objectives in Markov Decision Processes
Apr 27, 2017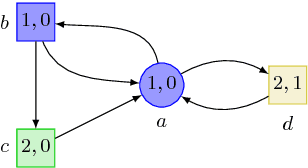
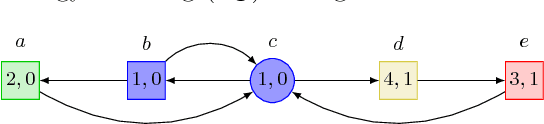
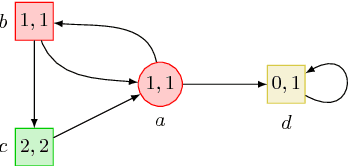
The beyond worst-case synthesis problem was introduced recently by Bruy\`ere et al. [BFRR14]: it aims at building system controllers that provide strict worst-case performance guarantees against an antagonistic environment while ensuring higher expected performance against a stochastic model of the environment. Our work extends the framework of [BFRR14] and follow-up papers, which focused on quantitative objectives, by addressing the case of $\omega$-regular conditions encoded as parity objectives, a natural way to represent functional requirements of systems. We build strategies that satisfy a main parity objective on all plays, while ensuring a secondary one with sufficient probability. This setting raises new challenges in comparison to quantitative objectives, as one cannot easily mix different strategies without endangering the functional properties of the system. We establish that, for all variants of this problem, deciding the existence of a strategy lies in ${\sf NP} \cap {\sf coNP}$, the same complexity class as classical parity games. Hence, our framework provides additional modeling power while staying in the same complexity class. [BFRR14] V\'eronique Bruy\`ere, Emmanuel Filiot, Mickael Randour, and Jean-Fran\c{c}ois Raskin. Meet your expectations with guarantees: Beyond worst-case synthesis in quantitative games. In Ernst W. Mayr and Natacha Portier, editors, 31st International Symposium on Theoretical Aspects of Computer Science, STACS 2014, March 5-8, 2014, Lyon, France, volume 25 of LIPIcs, pages 199-213. Schloss Dagstuhl - Leibniz - Zentrum fuer Informatik, 2014.