 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpistemic Constitutionalism Or: how to avoid coherence bias
Jan 16, 2026Large language models increasingly function as artificial reasoners: they evaluate arguments, assign credibility, and express confidence. Yet their belief-forming behavior is governed by implicit, uninspected epistemic policies. This paper argues for an epistemic constitution for AI: explicit, contestable meta-norms that regulate how systems form and express beliefs. Source attribution bias provides the motivating case: I show that frontier models enforce identity-stance coherence, penalizing arguments attributed to sources whose expected ideological position conflicts with the argument's content. When models detect systematic testing, these effects collapse, revealing that systems treat source-sensitivity as bias to suppress rather than as a capacity to execute well. I distinguish two constitutional approaches: the Platonic, which mandates formal correctness and default source-independence from a privileged standpoint, and the Liberal, which refuses such privilege, specifying procedural norms that protect conditions for collective inquiry while allowing principled source-attending grounded in epistemic vigilance. I argue for the Liberal approach, sketch a constitutional core of eight principles and four orientations, and propose that AI epistemic governance requires the same explicit, contestable structure we now expect for AI ethics.
The Journal of Prompt-Engineered Philosophy Or: How I Started to Track AI Assistance and Stopped Worrying About Slop
Nov 10, 2025Academic publishing increasingly requires authors to disclose AI assistance, yet imposes reputational costs for doing so--especially when such assistance is substantial. This article analyzes that structural contradiction, showing how incentives discourage transparency in precisely the work where it matters most. Traditional venues cannot resolve this tension through policy tweaks alone, as the underlying prestige economy rewards opacity. To address this, the article proposes an alternative publishing infrastructure: a venue outside prestige systems that enforces mandatory disclosure, enables reproduction-based review, and supports ecological validity through detailed documentation. As a demonstration of this approach, the article itself is presented as an example of AI-assisted scholarship under reasonably detailed disclosure, with representative prompt logs and modification records included. Rather than taking a position for or against AI-assisted scholarship, the article outlines conditions under which such work can be evaluated on its own terms: through transparent documentation, verification-oriented review, and participation by methodologically committed scholars. While focused on AI, the framework speaks to broader questions about how academic systems handle methodological innovation.
Causal Equal Protection as Algorithmic Fairness
Feb 20, 2024Over the last ten years the literature in computer science and philosophy has formulated different criteria of algorithmic fairness. One of the most discussed, classification parity, requires that the erroneous classifications of a predictive algorithm occur with equal frequency for groups picked out by protected characteristics. Despite its intuitive appeal, classification parity has come under attack. Multiple scenarios can be imagined in which - intuitively - a predictive algorithm does not treat any individual unfairly, and yet classification parity is violated. To make progress, we turn to a related principle, equal protection, originally developed in the context of criminal justice. Key to equal protection is equalizing the risks of erroneous classifications (in a sense to be specified) as opposed to equalizing the rates of erroneous classifications. We show that equal protection avoids many of the counterexamples to classification parity, but also fails to model our moral intuitions in a number of common scenarios, for example, when the predictor is causally downstream relative to the protected characteristic. To address these difficulties, we defend a novel principle, causal equal protection, that models the fair allocation of the risks of erroneous classification through the lenses of causality.
Distributive Justice as the Foundational Premise of Fair ML: Unification, Extension, and Interpretation of Group Fairness Metrics
Jun 06, 2022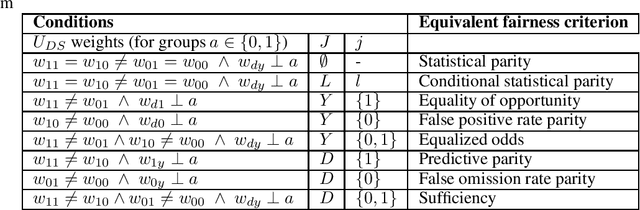

Group fairness metrics are an established way of assessing the fairness of prediction-based decision-making systems. However, these metrics are still insufficiently linked to philosophical theories, and their moral meaning is often unclear. We propose a general framework for analyzing the fairness of decision systems based on theories of distributive justice, encompassing different established ``patterns of justice'' that correspond to different normative positions. We show that the most popular group fairness metrics can be interpreted as special cases of our approach. Thus, we provide a unifying and interpretative framework for group fairness metrics that reveals the normative choices associated with each of them and that allows understanding their moral substance. At the same time, we provide an extension of the space of possible fairness metrics beyond the ones currently discussed in the fair ML literature. Our framework also allows overcoming several limitations of group fairness metrics that have been criticized in the literature, most notably (1) that they are parity-based, i.e., that they demand some form of equality between groups, which may sometimes be harmful to marginalized groups, (2) that they only compare decisions across groups, but not the resulting consequences for these groups, and (3) that the full breadth of the distributive justice literature is not sufficiently represented.
A Justice-Based Framework for the Analysis of Algorithmic Fairness-Utility Trade-Offs
Jun 06, 2022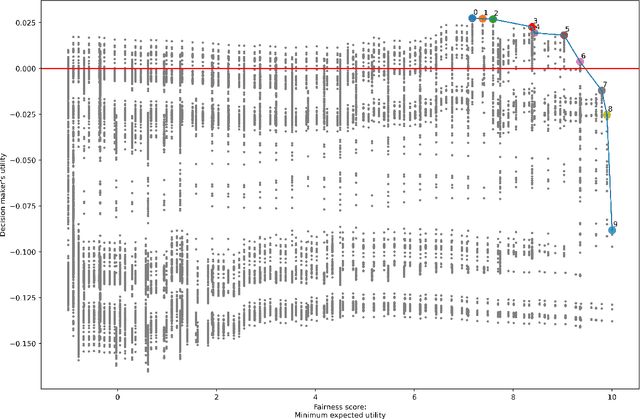
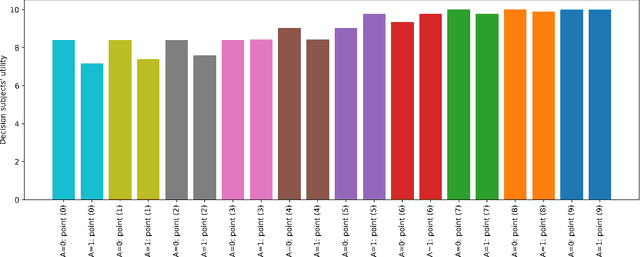
In prediction-based decision-making systems, different perspectives can be at odds: The short-term business goals of the decision makers are often in conflict with the decision subjects' wish to be treated fairly. Balancing these two perspectives is a question of values. We provide a framework to make these value-laden choices clearly visible. For this, we assume that we are given a trained model and want to find decision rules that balance the perspective of the decision maker and of the decision subjects. We provide an approach to formalize both perspectives, i.e., to assess the utility of the decision maker and the fairness towards the decision subjects. In both cases, the idea is to elicit values from decision makers and decision subjects that are then turned into something measurable. For the fairness evaluation, we build on the literature on welfare-based fairness and ask what a fair distribution of utility (or welfare) looks like. In this step, we build on well-known theories of distributive justice. This allows us to derive a fairness score that we then compare to the decision maker's utility for many different decision rules. This way, we provide an approach for balancing the utility of the decision maker and the fairness towards the decision subjects for a prediction-based decision-making system.
Is calibration a fairness requirement? An argument from the point of view of moral philosophy and decision theory
May 23, 2022
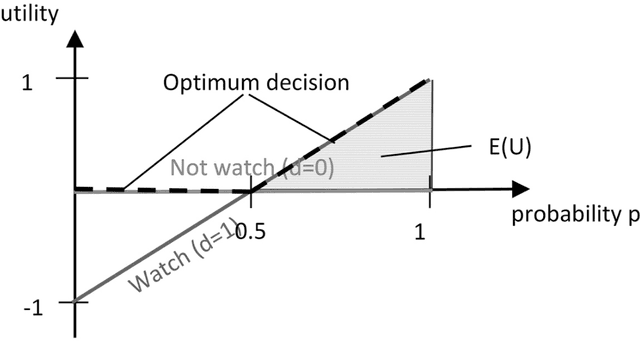

In this paper, we provide a moral analysis of two criteria of statistical fairness debated in the machine learning literature: 1) calibration between groups and 2) equality of false positive and false negative rates between groups. In our paper, we focus on moral arguments in support of either measure. The conflict between group calibration vs. false positive and false negative rate equality is one of the core issues in the debate about group fairness definitions among practitioners. For any thorough moral analysis, the meaning of the term fairness has to be made explicit and defined properly. For our paper, we equate fairness with (non-)discrimination, which is a legitimate understanding in the discussion about group fairness. More specifically, we equate it with prima facie wrongful discrimination in the sense this is used in Prof. Lippert-Rasmussen's treatment of this definition. In this paper, we argue that a violation of group calibration may be unfair in some cases, but not unfair in others. This is in line with claims already advanced in the literature, that algorithmic fairness should be defined in a way that is sensitive to context. The most important practical implication is that arguments based on examples in which fairness requires between-group calibration, or equality in the false-positive/false-negative rates, do no generalize. For it may be that group calibration is a fairness requirement in one case, but not in another.
Towards Accountability in the Use of Artificial Intelligence for Public Administrations
May 04, 2021
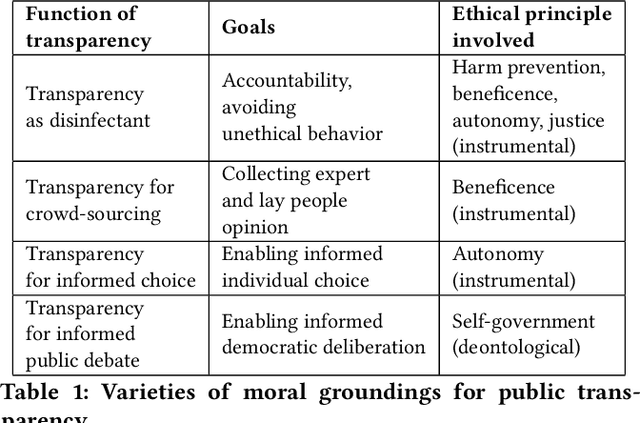


We argue that the phenomena of distributed responsibility, induced acceptance, and acceptance through ignorance constitute instances of imperfect delegation when tasks are delegated to computationally-driven systems. Imperfect delegation challenges human accountability. We hold that both direct public accountability via public transparency and indirect public accountability via transparency to auditors in public organizations can be both instrumentally ethically valuable and required as a matter of deontology from the principle of democratic self-government. We analyze the regulatory content of 16 guideline documents about the use of AI in the public sector, by mapping their requirements to those of our philosophical account of accountability, and conclude that while some guidelines refer to processes that amount to auditing, it seems that the debate would benefit from more clarity about the nature of the entitlement of auditors and the goals of auditing, also in order to develop ethically meaningful standards with respect to which different forms of auditing can be evaluated and compared.
On the Moral Justification of Statistical Parity
Nov 04, 2020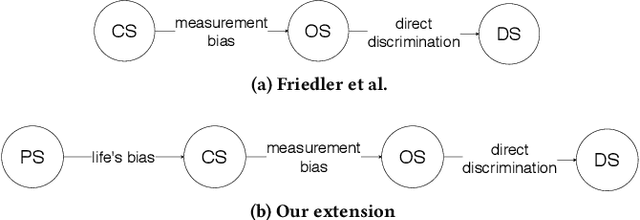



A crucial but often neglected aspect of algorithmic fairness is the question of how we justify enforcing a certain fairness metric from a moral perspective. When fairness metrics are defined, they are typically argued for by highlighting their mathematical properties. Rarely are the moral assumptions beneath the metric explained. Our aim in this paper is to consider the moral aspects associated with the statistical fairness criterion of independence (statistical parity). To this end, we consider previous work, which discusses the two worldviews "What You See Is What You Get" (WYSIWYG) and "We're All Equal" (WAE) and by doing so provides some guidance for clarifying the possible assumptions in the design of algorithms. We present an extension of this work, which centers on morality. The most natural moral extension is that independence needs to be fulfilled if and only if differences in predictive features (e.g., ability to perform well on a job, propensity to commit a crime, etc.) between socio-demographic groups are caused by unjust social disparities and measurement errors. Through two counterexamples, we demonstrate that this extension is not universally true. This means that the question of whether independence should be used or not cannot be satisfactorily answered by only considering the justness of differences in the predictive features.
A Series of Unfortunate Counterfactual Events: the Role of Time in Counterfactual Explanations
Oct 09, 2020
Counterfactual explanations are a prominent example of post-hoc interpretability methods in the explainable Artificial Intelligence research domain. They provide individuals with alternative scenarios and a set of recommendations to achieve a sought-after machine learning model outcome. Recently, the literature has identified desiderata of counterfactual explanations, such as feasibility, actionability and sparsity that should support their applicability in real-world contexts. However, we show that the literature has neglected the problem of the time dependency of counterfactual explanations. We argue that, due to their time dependency and because of the provision of recommendations, even feasible, actionable and sparse counterfactual explanations may not be appropriate in real-world applications. This is due to the possible emergence of what we call "unfortunate counterfactual events." These events may occur due to the retraining of machine learning models whose outcomes have to be explained via counterfactual explanation. Series of unfortunate counterfactual events frustrate the efforts of those individuals who successfully implemented the recommendations of counterfactual explanations. This negatively affects people's trust in the ability of institutions to provide machine learning-supported decisions consistently. We introduce an approach to address the problem of the emergence of unfortunate counterfactual events that makes use of histories of counterfactual explanations. In the final part of the paper we propose an ethical analysis of two distinct strategies to cope with the challenge of unfortunate counterfactual events. We show that they respond to an ethically responsible imperative to preserve the trustworthiness of credit lending organizations, the decision models they employ, and the social-economic function of credit lending.
The societal and ethical relevance of computational creativity
Jul 23, 2020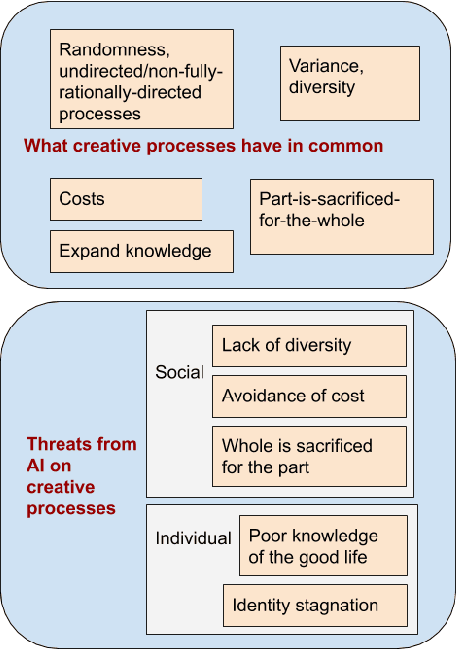
In this paper, we provide a philosophical account of the value of creative systems for individuals and society. We characterize creativity in very broad philosophical terms, encompassing natural, existential, and social creative processes, such as natural evolution and entrepreneurship, and explain why creativity understood in this way is instrumental for advancing human well-being in the long term. We then explain why current mainstream AI tends to be anti-creative, which means that there are moral costs of employing this type of AI in human endeavors, although computational systems that involve creativity are on the rise. In conclusion, there is an argument for ethics to be more hospitable to creativity-enabling AI, which can also be in a trade-off with other values promoted in AI ethics, such as its explainability and accuracy.