 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributive Justice as the Foundational Premise of Fair ML: Unification, Extension, and Interpretation of Group Fairness Metrics
Jun 06, 2022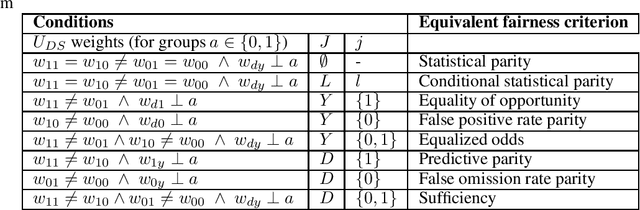

Group fairness metrics are an established way of assessing the fairness of prediction-based decision-making systems. However, these metrics are still insufficiently linked to philosophical theories, and their moral meaning is often unclear. We propose a general framework for analyzing the fairness of decision systems based on theories of distributive justice, encompassing different established ``patterns of justice'' that correspond to different normative positions. We show that the most popular group fairness metrics can be interpreted as special cases of our approach. Thus, we provide a unifying and interpretative framework for group fairness metrics that reveals the normative choices associated with each of them and that allows understanding their moral substance. At the same time, we provide an extension of the space of possible fairness metrics beyond the ones currently discussed in the fair ML literature. Our framework also allows overcoming several limitations of group fairness metrics that have been criticized in the literature, most notably (1) that they are parity-based, i.e., that they demand some form of equality between groups, which may sometimes be harmful to marginalized groups, (2) that they only compare decisions across groups, but not the resulting consequences for these groups, and (3) that the full breadth of the distributive justice literature is not sufficiently represented.
A Justice-Based Framework for the Analysis of Algorithmic Fairness-Utility Trade-Offs
Jun 06, 2022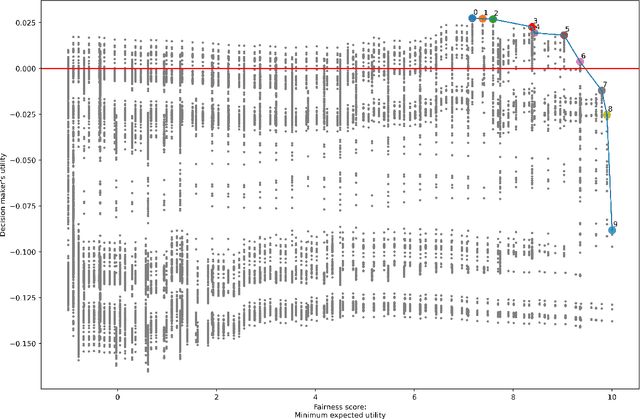
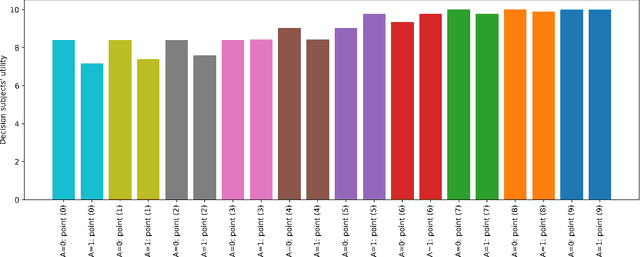
In prediction-based decision-making systems, different perspectives can be at odds: The short-term business goals of the decision makers are often in conflict with the decision subjects' wish to be treated fairly. Balancing these two perspectives is a question of values. We provide a framework to make these value-laden choices clearly visible. For this, we assume that we are given a trained model and want to find decision rules that balance the perspective of the decision maker and of the decision subjects. We provide an approach to formalize both perspectives, i.e., to assess the utility of the decision maker and the fairness towards the decision subjects. In both cases, the idea is to elicit values from decision makers and decision subjects that are then turned into something measurable. For the fairness evaluation, we build on the literature on welfare-based fairness and ask what a fair distribution of utility (or welfare) looks like. In this step, we build on well-known theories of distributive justice. This allows us to derive a fairness score that we then compare to the decision maker's utility for many different decision rules. This way, we provide an approach for balancing the utility of the decision maker and the fairness towards the decision subjects for a prediction-based decision-making system.
Gradual (In)Compatibility of Fairness Criteria
Sep 09, 2021
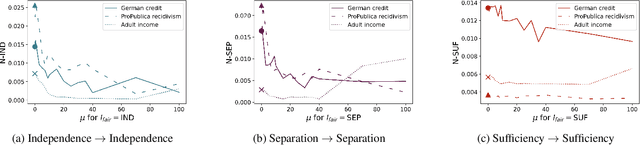
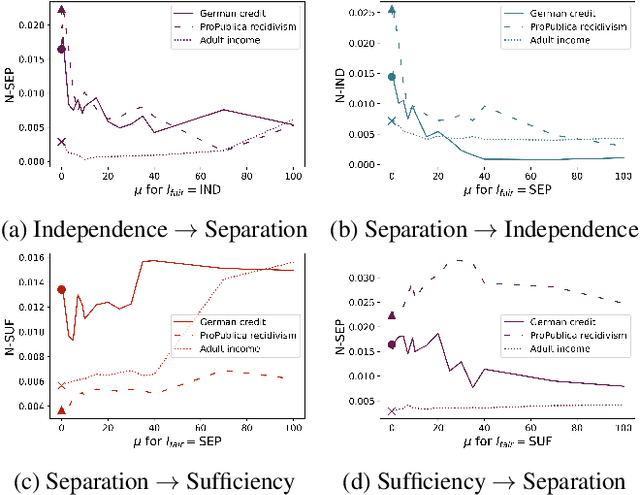
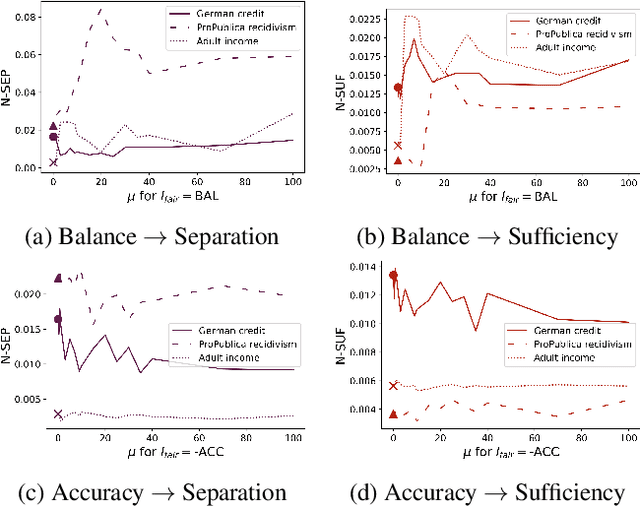
Impossibility results show that important fairness measures (independence, separation, sufficiency) cannot be satisfied at the same time under reasonable assumptions. This paper explores whether we can satisfy and/or improve these fairness measures simultaneously to a certain degree. We introduce information-theoretic formulations of the fairness measures and define degrees of fairness based on these formulations. The information-theoretic formulations suggest unexplored theoretical relations between the three fairness measures. In the experimental part, we use the information-theoretic expressions as regularizers to obtain fairness-regularized predictors for three standard datasets. Our experiments show that a) fairness regularization directly increases fairness measures, in line with existing work, and b) some fairness regularizations indirectly increase other fairness measures, as suggested by our theoretical findings. This establishes that it is possible to increase the degree to which some fairness measures are satisfied at the same time -- some fairness measures are gradually compatible.
A Systematic Approach to Group Fairness in Automated Decision Making
Sep 09, 2021
While the field of algorithmic fairness has brought forth many ways to measure and improve the fairness of machine learning models, these findings are still not widely used in practice. We suspect that one reason for this is that the field of algorithmic fairness came up with a lot of definitions of fairness, which are difficult to navigate. The goal of this paper is to provide data scientists with an accessible introduction to group fairness metrics and to give some insight into the philosophical reasoning for caring about these metrics. We will do this by considering in which sense socio-demographic groups are compared for making a statement on fairness.
* Accepted full paper at SDS2021, the 8th Swiss Conference on Data Science
On the Moral Justification of Statistical Parity
Nov 04, 2020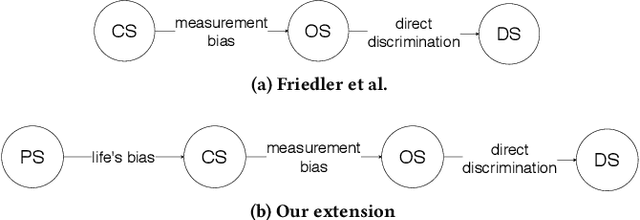



A crucial but often neglected aspect of algorithmic fairness is the question of how we justify enforcing a certain fairness metric from a moral perspective. When fairness metrics are defined, they are typically argued for by highlighting their mathematical properties. Rarely are the moral assumptions beneath the metric explained. Our aim in this paper is to consider the moral aspects associated with the statistical fairness criterion of independence (statistical parity). To this end, we consider previous work, which discusses the two worldviews "What You See Is What You Get" (WYSIWYG) and "We're All Equal" (WAE) and by doing so provides some guidance for clarifying the possible assumptions in the design of algorithms. We present an extension of this work, which centers on morality. The most natural moral extension is that independence needs to be fulfilled if and only if differences in predictive features (e.g., ability to perform well on a job, propensity to commit a crime, etc.) between socio-demographic groups are caused by unjust social disparities and measurement errors. Through two counterexamples, we demonstrate that this extension is not universally true. This means that the question of whether independence should be used or not cannot be satisfactorily answered by only considering the justness of differences in the predictive features.
Towards Data-Driven Affirmative Action Policies under Uncertainty
Jul 02, 2020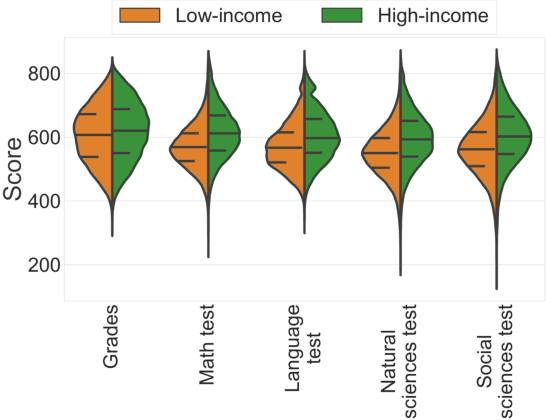
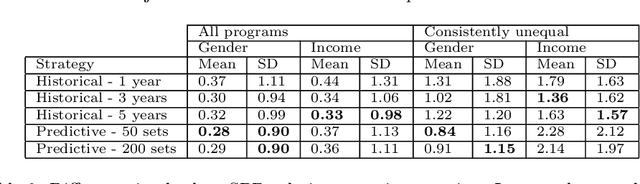
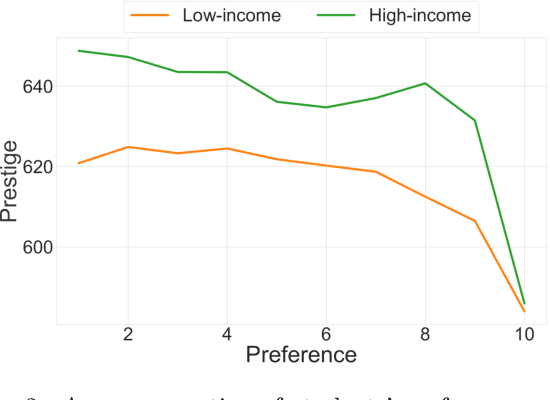

In this paper, we study university admissions under a centralized system that uses grades and standardized test scores to match applicants to university programs. We consider affirmative action policies that seek to increase the number of admitted applicants from underrepresented groups. Since such a policy has to be announced before the start of the application period, there is uncertainty about the score distribution of the students applying to each program. This poses a difficult challenge for policy-makers. We explore the possibility of using a predictive model trained on historical data to help optimize the parameters of such policies.