 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliability Gaps Between Groups in COMPAS Dataset
Aug 29, 2023



This paper investigates the inter-rater reliability of risk assessment instruments (RAIs). The main question is whether different, socially salient groups are affected differently by a lack of inter-rater reliability of RAIs, that is, whether mistakes with respect to different groups affects them differently. The question is investigated with a simulation study of the COMPAS dataset. A controlled degree of noise is injected into the input data of a predictive model; the noise can be interpreted as a synthetic rater that makes mistakes. The main finding is that there are systematic differences in output reliability between groups in the COMPAS dataset. The sign of the difference depends on the kind of inter-rater statistic that is used (Cohen's Kappa, Byrt's PABAK, ICC), and in particular whether or not a correction of predictions prevalences of the groups is used.
ML Interpretability: Simple Isn't Easy
Nov 24, 2022The interpretability of ML models is important, but it is not clear what it amounts to. So far, most philosophers have discussed the lack of interpretability of black-box models such as neural networks, and methods such as explainable AI that aim to make these models more transparent. The goal of this paper is to clarify the nature of interpretability by focussing on the other end of the 'interpretability spectrum'. The reasons why some models, linear models and decision trees, are highly interpretable will be examined, and also how more general models, MARS and GAM, retain some degree of interpretability. I find that while there is heterogeneity in how we gain interpretability, what interpretability is in particular cases can be explicated in a clear manner.
Emergence of Concepts in DNNs?
Nov 11, 2022The present paper reviews and discusses work from computer science that proposes to identify concepts in internal representations (hidden layers) of DNNs. It is examined, first, how existing methods actually identify concepts that are supposedly represented in DNNs. Second, it is discussed how conceptual spaces -- sets of concepts in internal representations -- are shaped by a tradeoff between predictive accuracy and compression. These issues are critically examined by drawing on philosophy. While there is evidence that DNNs able to represent non-trivial inferential relations between concepts, our ability to identify concepts is severely limited.
Gradual (In)Compatibility of Fairness Criteria
Sep 09, 2021
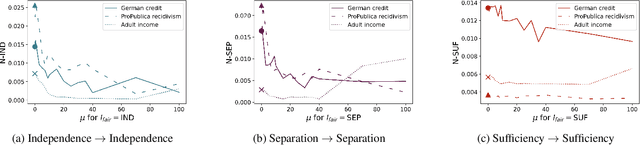
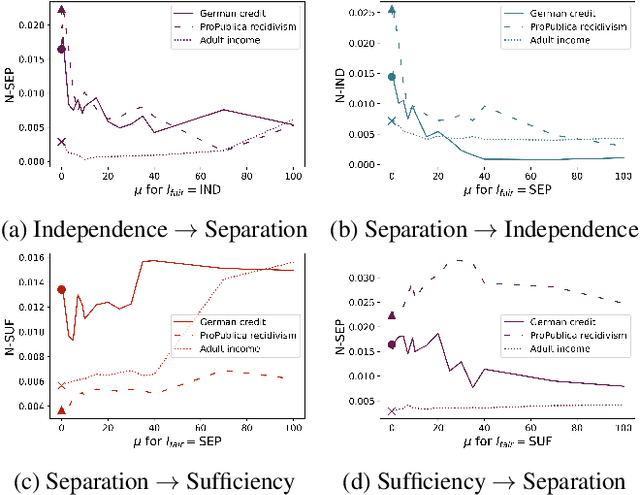
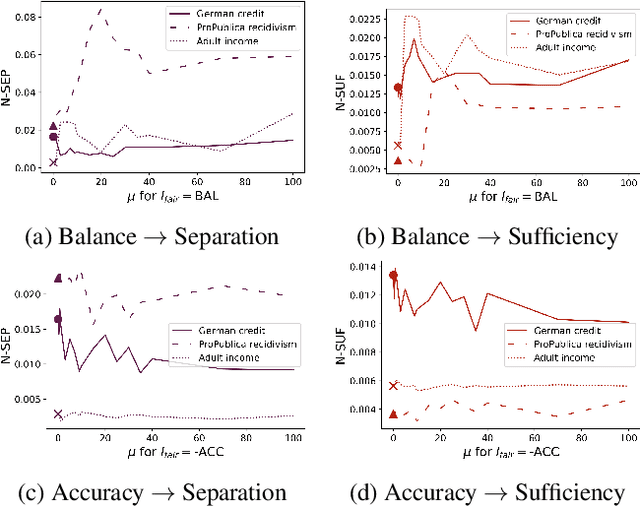
Impossibility results show that important fairness measures (independence, separation, sufficiency) cannot be satisfied at the same time under reasonable assumptions. This paper explores whether we can satisfy and/or improve these fairness measures simultaneously to a certain degree. We introduce information-theoretic formulations of the fairness measures and define degrees of fairness based on these formulations. The information-theoretic formulations suggest unexplored theoretical relations between the three fairness measures. In the experimental part, we use the information-theoretic expressions as regularizers to obtain fairness-regularized predictors for three standard datasets. Our experiments show that a) fairness regularization directly increases fairness measures, in line with existing work, and b) some fairness regularizations indirectly increase other fairness measures, as suggested by our theoretical findings. This establishes that it is possible to increase the degree to which some fairness measures are satisfied at the same time -- some fairness measures are gradually compatible.