 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForecasting the Past: Gradient-Based Distribution Shift Detection in Trajectory Prediction
Apr 14, 2026Trajectory prediction models often fail in real-world automated driving due to distributional shifts between training and test conditions. Such distributional shifts, whether behavioural or environmental, pose a critical risk by causing the model to make incorrect forecasts in unfamiliar situations. We propose a self-supervised method that trains a decoder in a post-hoc fashion on the self-supervised task of forecasting the second half of observed trajectories from the first half. The L2 norm of the gradient of this forecasting loss with respect to the decoder's final layer defines a score to identify distribution shifts. Our approach, first, does not affect the trajectory prediction model, ensuring no interference with original prediction performance and second, demonstrates substantial improvements on distribution shift detection for trajectory prediction on the Shifts and Argoverse datasets. Moreover, we show that this method can also be used to early detect collisions of a deep Q-Network motion planner in the Highway simulator. Source code is available at https://github.com/Michedev/forecasting-the-past.
Diffusion Model Guided Sampling with Pixel-Wise Aleatoric Uncertainty Estimation
Nov 29, 2024



Despite the remarkable progress in generative modelling, current diffusion models lack a quantitative approach to assess image quality. To address this limitation, we propose to estimate the pixel-wise aleatoric uncertainty during the sampling phase of diffusion models and utilise the uncertainty to improve the sample generation quality. The uncertainty is computed as the variance of the denoising scores with a perturbation scheme that is specifically designed for diffusion models. We then show that the aleatoric uncertainty estimates are related to the second-order derivative of the diffusion noise distribution. We evaluate our uncertainty estimation algorithm and the uncertainty-guided sampling on the ImageNet and CIFAR-10 datasets. In our comparisons with the related work, we demonstrate promising results in filtering out low quality samples. Furthermore, we show that our guided approach leads to better sample generation in terms of FID scores.
Generalization and Robustness Implications in Object-Centric Learning
Jul 01, 2021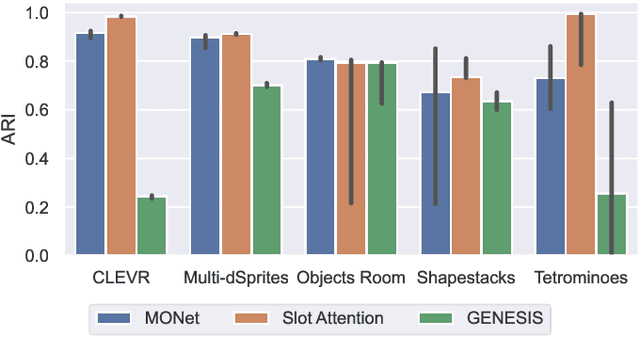
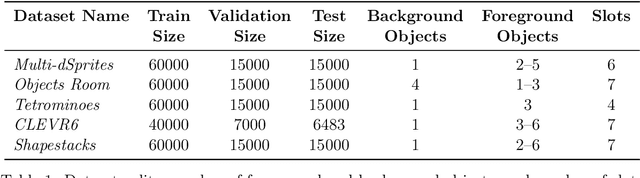

The idea behind object-centric representation learning is that natural scenes can better be modeled as compositions of objects and their relations as opposed to distributed representations. This inductive bias can be injected into neural networks to potentially improve systematic generalization and learning efficiency of downstream tasks in scenes with multiple objects. In this paper, we train state-of-the-art unsupervised models on five common multi-object datasets and evaluate segmentation accuracy and downstream object property prediction. In addition, we study systematic generalization and robustness by investigating the settings where either single objects are out-of-distribution -- e.g., having unseen colors, textures, and shapes -- or global properties of the scene are altered -- e.g., by occlusions, cropping, or increasing the number of objects. From our experimental study, we find object-centric representations to be generally useful for downstream tasks and robust to shifts in the data distribution, especially if shifts affect single objects.