 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuildings Detection in VHR SAR Images Using Fully Convolution Neural Networks
Aug 14, 2018



This paper addresses the highly challenging problem of automatically detecting man-made structures especially buildings in very high resolution (VHR) synthetic aperture radar (SAR) images. In this context, the paper has two major contributions: Firstly, it presents a novel and generic workflow that initially classifies the spaceborne TomoSAR point clouds $ - $ generated by processing VHR SAR image stacks using advanced interferometric techniques known as SAR tomography (TomoSAR) $ - $ into buildings and non-buildings with the aid of auxiliary information (i.e., either using openly available 2-D building footprints or adopting an optical image classification scheme) and later back project the extracted building points onto the SAR imaging coordinates to produce automatic large-scale benchmark labelled (buildings/non-buildings) SAR datasets. Secondly, these labelled datasets (i.e., building masks) have been utilized to construct and train the state-of-the-art deep Fully Convolution Neural Networks with an additional Conditional Random Field represented as a Recurrent Neural Network to detect building regions in a single VHR SAR image. Such a cascaded formation has been successfully employed in computer vision and remote sensing fields for optical image classification but, to our knowledge, has not been applied to SAR images. The results of the building detection are illustrated and validated over a TerraSAR-X VHR spotlight SAR image covering approximately 39 km$ ^2 $ $ - $ almost the whole city of Berlin $ - $ with mean pixel accuracies of around 93.84%
Deep 2.5D Vehicle Classification with Sparse SfM Depth Prior for Automated Toll Systems
May 11, 2018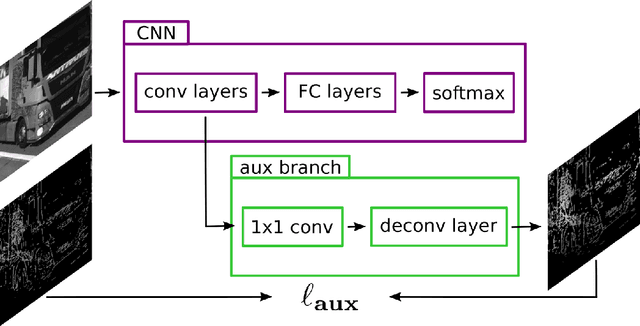


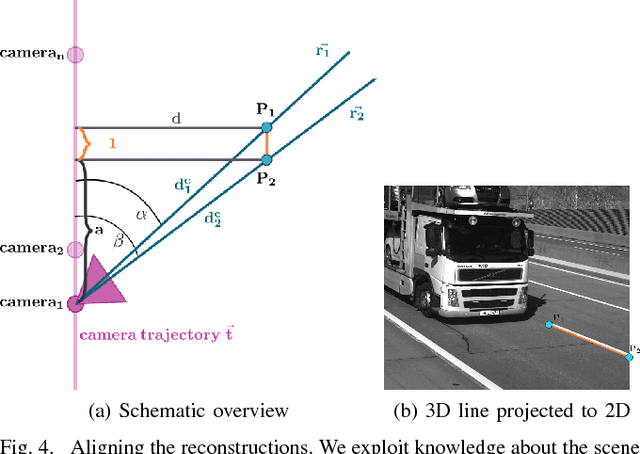
Automated toll systems rely on proper classification of the passing vehicles. This is especially difficult when the images used for classification only cover parts of the vehicle. To obtain information about the whole vehicle. we reconstruct the vehicle as 3D object and exploit this additional information within a Convolutional Neural Network (CNN). However, when using deep networks for 3D object classification, large amounts of dense 3D models are required for good accuracy, which are often neither available nor feasible to process due to memory requirements. Therefore, in our method we reproject the 3D object onto the image plane using the reconstructed points, lines or both. We utilize this sparse depth prior within an auxiliary network branch that acts as a regularizer during training. We show that this auxiliary regularizer helps to improve accuracy compared to 2D classification on a real-world dataset. Furthermore due to the design of the network, at test time only the 2D camera images are required for classification which enables the usage in portable computer vision systems.