 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext Model for Pedestrian Intention Prediction using Factored Latent-Dynamic Conditional Random Fields
Jul 27, 2019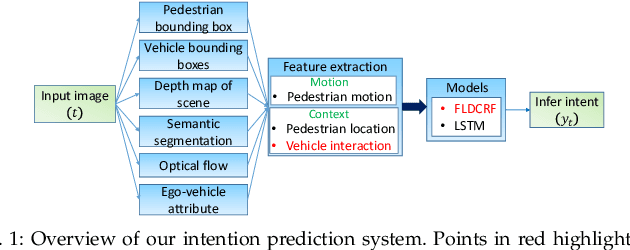
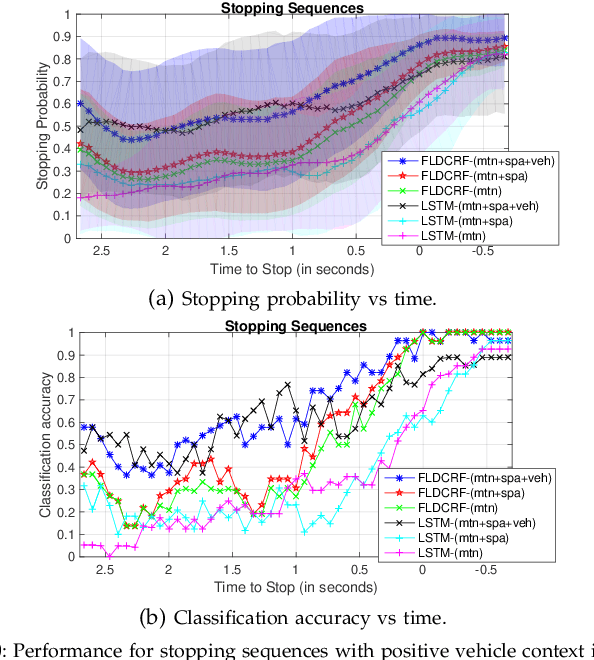

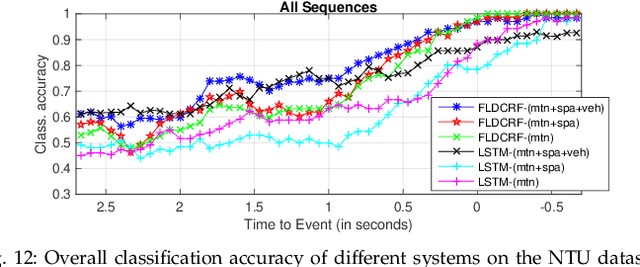
Smooth handling of pedestrian interactions is a key requirement for Autonomous Vehicles (AV) and Advanced Driver Assistance Systems (ADAS). Such systems call for early and accurate prediction of a pedestrian's crossing/not-crossing behaviour in front of the vehicle. Existing approaches to pedestrian behaviour prediction make use of pedestrian motion, his/her location in a scene and static context variables such as traffic lights, zebra crossings etc. We stress on the necessity of early prediction for smooth operation of such systems. We introduce the influence of vehicle interactions on pedestrian intention for this purpose. In this paper, we show a discernible advance in prediction time aided by the inclusion of such vehicle interaction context. We apply our methods to two different datasets, one in-house collected - NTU dataset and another public real-life benchmark - JAAD dataset. We also propose a generic graphical model Factored Latent-Dynamic Conditional Random Fields (FLDCRF) for single and multi-label sequence prediction as well as joint interaction modeling tasks. FLDCRF outperforms Long Short-Term Memory (LSTM) networks across the datasets ($\sim$100 sequences per dataset) over identical time-series features. While the existing best system predicts pedestrian stopping behaviour with 70\% accuracy 0.38 seconds before the actual events, our system achieves such accuracy at least 0.9 seconds on an average before the actual events across datasets.
Actor-Action Semantic Segmentation with Region Masks
Jul 23, 2018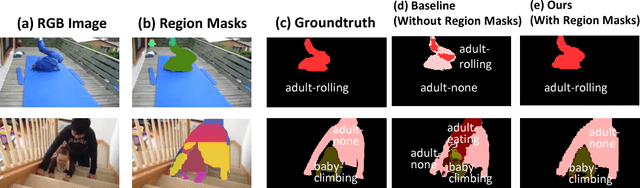

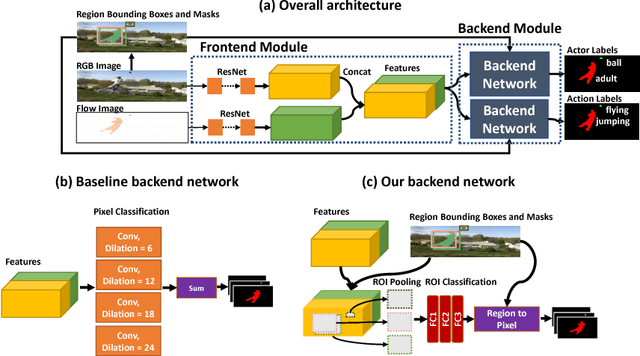

In this paper, we study the actor-action semantic segmentation problem, which requires joint labeling of both actor and action categories in video frames. One major challenge for this task is that when an actor performs an action, different body parts of the actor provide different types of cues for the action category and may receive inconsistent action labeling when they are labeled independently. To address this issue, we propose an end-to-end region-based actor-action segmentation approach which relies on region masks from an instance segmentation algorithm. Our main novelty is to avoid labeling pixels in a region mask independently - instead we assign a single action label to these pixels to achieve consistent action labeling. When a pixel belongs to multiple region masks, max pooling is applied to resolve labeling conflicts. Our approach uses a two-stream network as the front-end (which learns features capturing both appearance and motion information), and uses two region-based segmentation networks as the back-end (which takes the fused features from the two-stream network as the input and predicts actor-action labeling). Experiments on the A2D dataset demonstrate that both the region-based segmentation strategy and the fused features from the two-stream network contribute to the performance improvements. The proposed approach outperforms the state-of-the-art results by more than 8% in mean class accuracy, and more than 5% in mean class IOU, which validates its effectiveness.
Methods for Collision-Free Navigation of Multiple Mobile Robots in Unknown Cluttered Environments
Jan 27, 2014Navigation and guidance of autonomous vehicles is a fundamental problem in robotics, which has attracted intensive research in recent decades. This report is mainly concerned with provable collision avoidance of multiple autonomous vehicles operating in unknown cluttered environments, using reactive decentralized navigation laws, where obstacle information is supplied by some sensor system. Recently, robust and decentralized variants of model predictive control based navigation systems have been applied to vehicle navigation problems. Properties such as provable collision avoidance under disturbance and provable convergence to a target have been shown; however these often require significant computational and communicative capabilities, and don't consider sensor constraints, making real time use somewhat difficult. There also seems to be opportunity to develop a better trade-off between tractability, optimality, and robustness. The main contributions of this work are as follows; firstly, the integration of the robust model predictive control concept with reactive navigation strategies based on local path planning, which is applied to both holonomic and unicycle vehicle models subjected to acceleration bounds and disturbance; secondly, the extension of model predictive control type methods to situations where the information about the obstacle is limited to a discrete ray-based sensor model, for which provably safe, convergent boundary following can be shown; and thirdly the development of novel constraints allowing decentralized coordination of multiple vehicles using a robust model predictive control type approach, where a single communication exchange is used per control update, vehicles are allowed to perform planning simultaneously, and coherency objectives are avoided.