 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActor-Action Semantic Segmentation with Region Masks
Paper and Code
Jul 23, 2018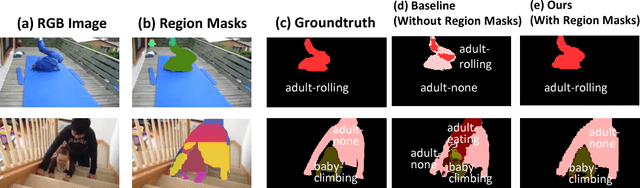

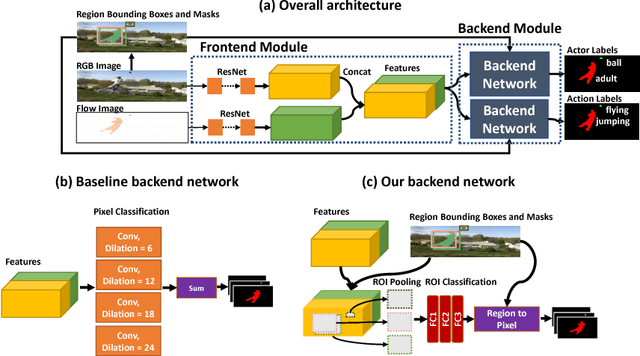

In this paper, we study the actor-action semantic segmentation problem, which requires joint labeling of both actor and action categories in video frames. One major challenge for this task is that when an actor performs an action, different body parts of the actor provide different types of cues for the action category and may receive inconsistent action labeling when they are labeled independently. To address this issue, we propose an end-to-end region-based actor-action segmentation approach which relies on region masks from an instance segmentation algorithm. Our main novelty is to avoid labeling pixels in a region mask independently - instead we assign a single action label to these pixels to achieve consistent action labeling. When a pixel belongs to multiple region masks, max pooling is applied to resolve labeling conflicts. Our approach uses a two-stream network as the front-end (which learns features capturing both appearance and motion information), and uses two region-based segmentation networks as the back-end (which takes the fused features from the two-stream network as the input and predicts actor-action labeling). Experiments on the A2D dataset demonstrate that both the region-based segmentation strategy and the fused features from the two-stream network contribute to the performance improvements. The proposed approach outperforms the state-of-the-art results by more than 8% in mean class accuracy, and more than 5% in mean class IOU, which validates its effectiveness.