 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactored Latent-Dynamic Conditional Random Fields for Single and Multi-label Sequence Modeling
Nov 12, 2019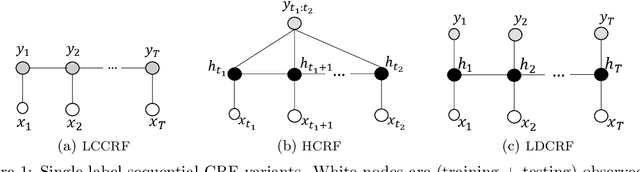

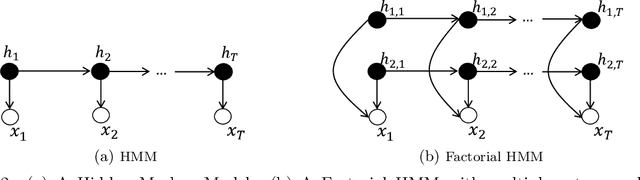

Conditional Random Fields (CRF) are frequently applied for labeling and segmenting sequence data. Morency et al. (2007) introduced hidden state variables in a labeled CRF structure in order to model the latent dynamics within class labels, thus improving the labeling performance. Such a model is known as Latent-Dynamic CRF (LDCRF). We present Factored LDCRF (FLDCRF), a structure that allows multiple latent dynamics of the class labels to interact with each other. Including such latent-dynamic interactions leads to improved labeling performance on single-label and multi-label sequence modeling tasks. We apply our FLDCRF models on two single-label (one nested cross-validation) and one multi-label sequence tagging (nested cross-validation) experiments across two different datasets - UCI gesture phase data and UCI opportunity data. FLDCRF outperforms all state-of-the-art sequence models, i.e., CRF, LDCRF, LSTM, LSTM-CRF, Factorial CRF, Coupled CRF and a multi-label LSTM model in all our experiments. In addition, LSTM based models display inconsistent performance across validation and test data, and pose diffculty to select models on validation data during our experiments. FLDCRF offers easier model selection, consistency across validation and test performance and lucid model intuition. FLDCRF is also much faster to train compared to LSTM, even without a GPU. FLDCRF outshines the best LSTM model by ~4% on a single-label task on UCI gesture phase data and outperforms LSTM performance by ~2% on average across nested cross-validation test sets on the multi-label sequence tagging experiment on UCI opportunity data. The idea of FLDCRF can be extended to joint (multi-agent interactions) and heterogeneous (discrete and continuous) state space models.
Context Model for Pedestrian Intention Prediction using Factored Latent-Dynamic Conditional Random Fields
Jul 27, 2019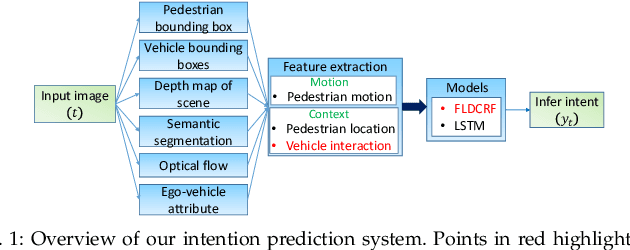
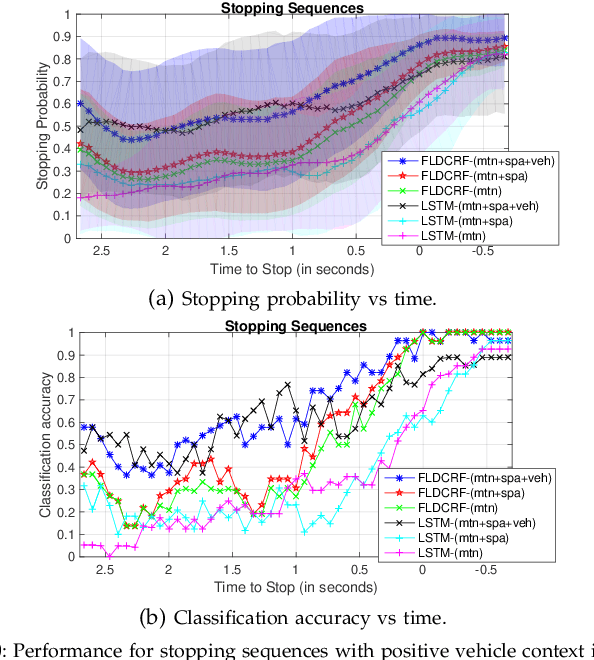

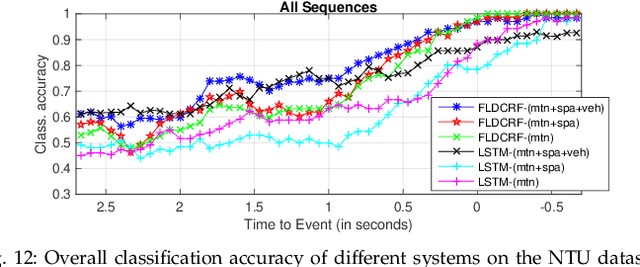
Smooth handling of pedestrian interactions is a key requirement for Autonomous Vehicles (AV) and Advanced Driver Assistance Systems (ADAS). Such systems call for early and accurate prediction of a pedestrian's crossing/not-crossing behaviour in front of the vehicle. Existing approaches to pedestrian behaviour prediction make use of pedestrian motion, his/her location in a scene and static context variables such as traffic lights, zebra crossings etc. We stress on the necessity of early prediction for smooth operation of such systems. We introduce the influence of vehicle interactions on pedestrian intention for this purpose. In this paper, we show a discernible advance in prediction time aided by the inclusion of such vehicle interaction context. We apply our methods to two different datasets, one in-house collected - NTU dataset and another public real-life benchmark - JAAD dataset. We also propose a generic graphical model Factored Latent-Dynamic Conditional Random Fields (FLDCRF) for single and multi-label sequence prediction as well as joint interaction modeling tasks. FLDCRF outperforms Long Short-Term Memory (LSTM) networks across the datasets ($\sim$100 sequences per dataset) over identical time-series features. While the existing best system predicts pedestrian stopping behaviour with 70\% accuracy 0.38 seconds before the actual events, our system achieves such accuracy at least 0.9 seconds on an average before the actual events across datasets.