 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnihilation of Spurious Minima in Two-Layer ReLU Networks
Oct 12, 2022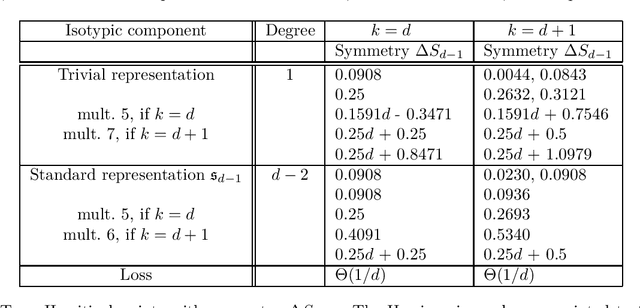
We study the optimization problem associated with fitting two-layer ReLU neural networks with respect to the squared loss, where labels are generated by a target network. Use is made of the rich symmetry structure to develop a novel set of tools for studying the mechanism by which over-parameterization annihilates spurious minima. Sharp analytic estimates are obtained for the loss and the Hessian spectrum at different minima, and it is proved that adding neurons can turn symmetric spurious minima into saddles; minima of lesser symmetry require more neurons. Using Cauchy's interlacing theorem, we prove the existence of descent directions in certain subspaces arising from the symmetry structure of the loss function. This analytic approach uses techniques, new to the field, from algebraic geometry, representation theory and symmetry breaking, and confirms rigorously the effectiveness of over-parameterization in making the associated loss landscape accessible to gradient-based methods. For a fixed number of neurons and inputs, the spectral results remain true under symmetry breaking perturbation of the target.
Analytic Study of Families of Spurious Minima in Two-Layer ReLU Neural Networks
Jul 21, 2021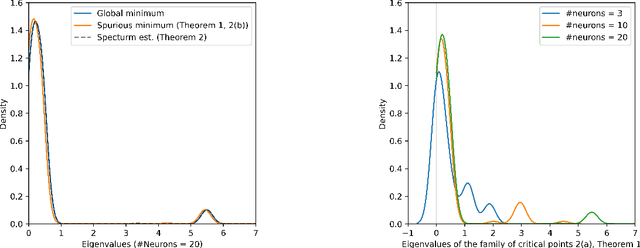

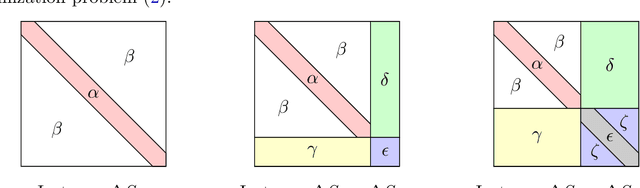
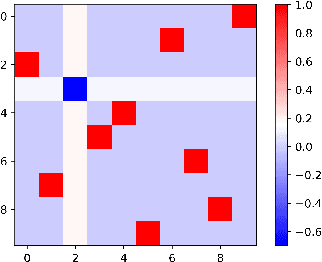
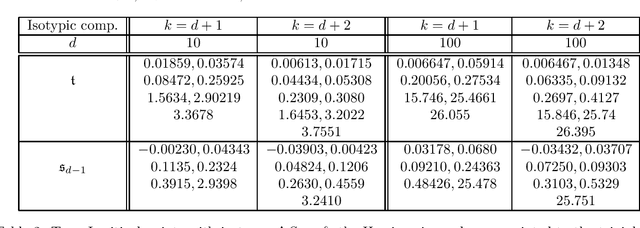
We study the optimization problem associated with fitting two-layer ReLU neural networks with respect to the squared loss, where labels are generated by a target network. We make use of the rich symmetry structure to develop a novel set of tools for studying families of spurious minima. In contrast to existing approaches which operate in limiting regimes, our technique directly addresses the nonconvex loss landscape for a finite number of inputs $d$ and neurons $k$, and provides analytic, rather than heuristic, information. In particular, we derive analytic estimates for the loss at different minima, and prove that modulo $O(d^{-1/2})$-terms the Hessian spectrum concentrates near small positive constants, with the exception of $\Theta(d)$ eigenvalues which grow linearly with~$d$. We further show that the Hessian spectrum at global and spurious minima coincide to $O(d^{-1/2})$-order, thus challenging our ability to argue about statistical generalization through local curvature. Lastly, our technique provides the exact \emph{fractional} dimensionality at which families of critical points turn from saddles into spurious minima. This makes possible the study of the creation and the annihilation of spurious minima using powerful tools from equivariant bifurcation theory.
Equivariant bifurcation, quadratic equivariants, and symmetry breaking for the standard representation of $S_n$
Jul 06, 2021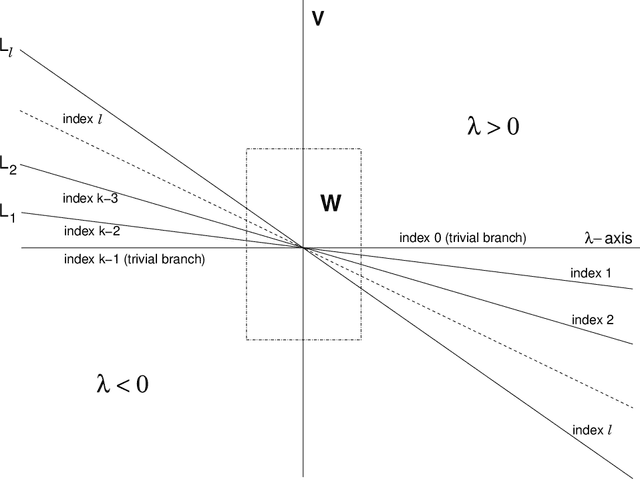
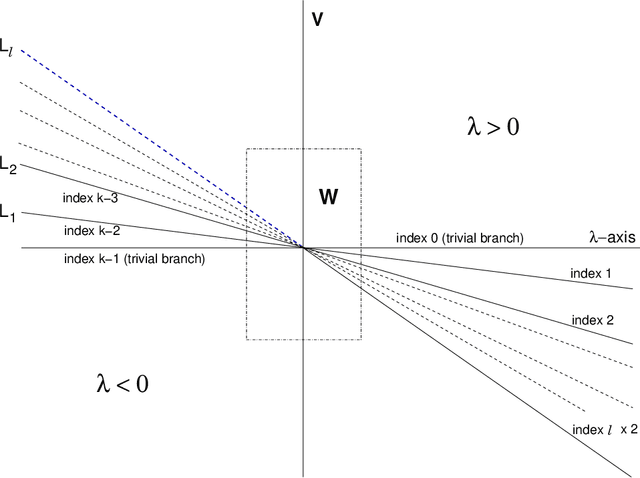

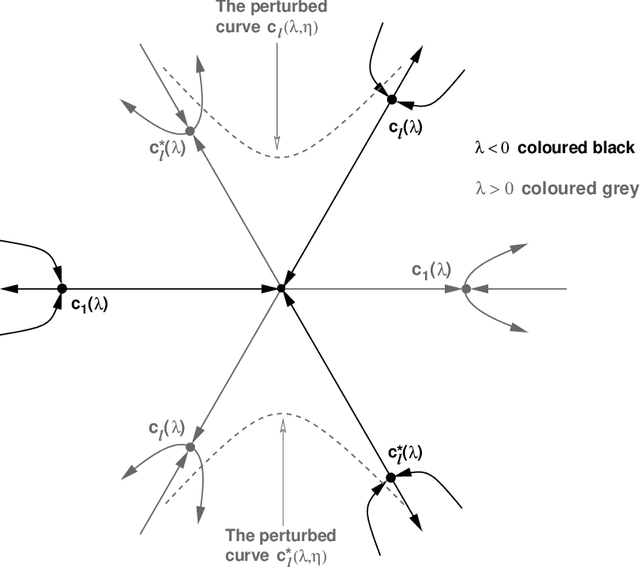
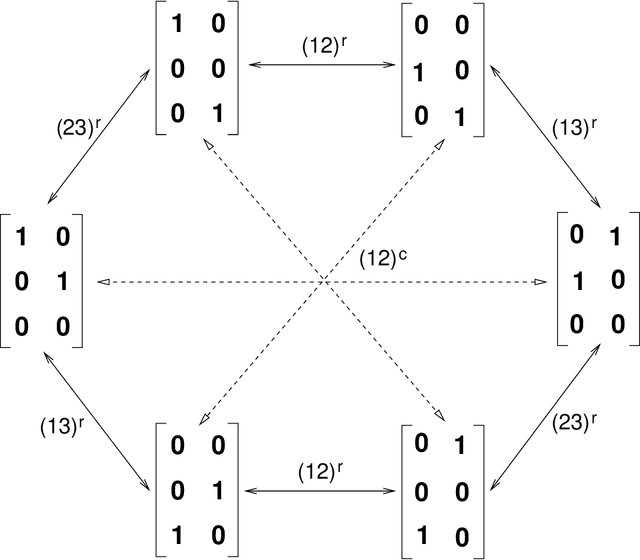
Motivated by questions originating from the study of a class of shallow student-teacher neural networks, methods are developed for the analysis of spurious minima in classes of gradient equivariant dynamics related to neural nets. In the symmetric case, methods depend on the generic equivariant bifurcation theory of irreducible representations of the symmetric group on $n$ symbols, $S_n$; in particular, the standard representation of $S_n$. It is shown that spurious minima do not arise from spontaneous symmetry breaking but rather through a complex deformation of the landscape geometry that can be encoded by a generic $S_n$-equivariant bifurcation. We describe minimal models for forced symmetry breaking that give a lower bound on the dynamic complexity involved in the creation of spurious minima when there is no symmetry. Results on generic bifurcation when there are quadratic equivariants are also proved; this work extends and clarifies results of Ihrig & Golubitsky and Chossat, Lauterback & Melbourne on the instability of solutions when there are quadratic equivariants.
Symmetry Breaking in Symmetric Tensor Decomposition
Mar 10, 2021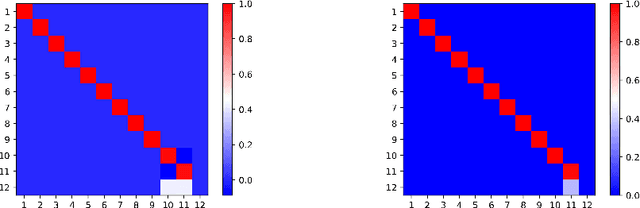
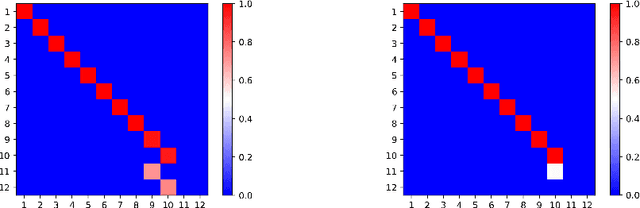
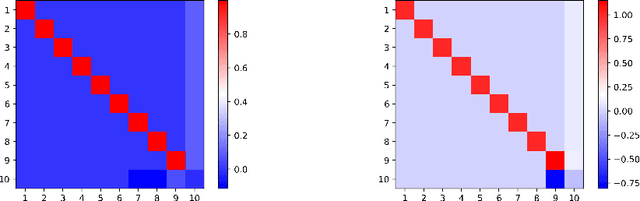
In this note, we consider the optimization problem associated with computing the rank decomposition of a symmetric tensor. We show that, in a well-defined sense, minima in this highly nonconvex optimization problem break the symmetry of the target tensor -- but not too much. This phenomenon of symmetry breaking applies to various choices of tensor norms, and makes it possible to study the optimization landscape using a set of recently-developed symmetry-based analytical tools. The fact that the objective function under consideration is a multivariate polynomial allows us to apply symbolic methods from computational algebra to obtain more refined information on the symmetry breaking phenomenon.
Analytic Characterization of the Hessian in Shallow ReLU Models: A Tale of Symmetry
Aug 04, 2020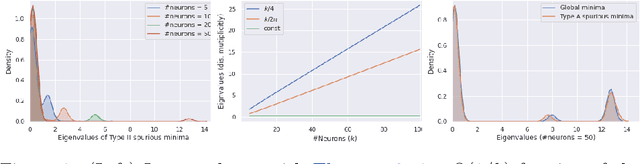
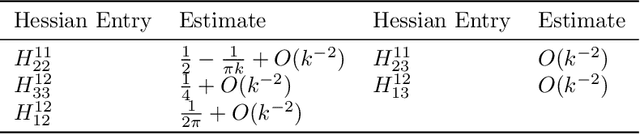

We consider the optimization problem associated with fitting two-layers ReLU networks with $k$ neurons. We leverage the rich symmetry structure to analytically characterize the Hessian and its spectral density at various families of spurious local minima. In particular, we prove that for standard $d$-dimensional Gaussian inputs with $d\ge k$: (a) of the $dk$ eigenvalues corresponding to the weights of the first layer, $dk - O(d)$ concentrate near zero, (b) $\Omega(d)$ of the remaining eigenvalues grow linearly with $k$. Although this phenomenon of extremely skewed spectrum has been observed many times before, to the best of our knowledge, this is the first time it has been established rigorously. Our analytic approach uses techniques, new to the field, from symmetry breaking and representation theory, and carries important implications for our ability to argue about statistical generalization through local curvature.
Symmetry & critical points for a model shallow neural network
Mar 23, 2020
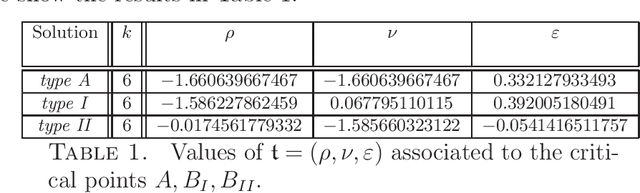

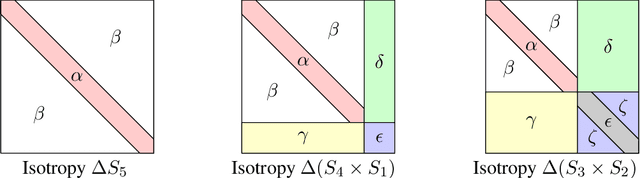
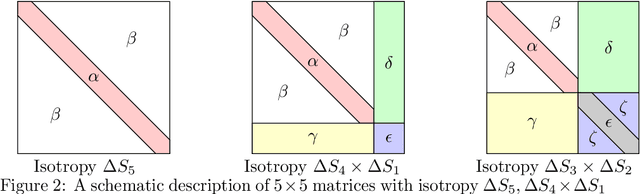
A detailed analysis is given of a family of critical points determining spurious minima for a model student-teacher 2-layer neural network, with ReLU activation function, and a natural $\Gamma = S_k \times S_k$-symmetry. For a $k$-neuron shallow network of this type, analytic equations are given which, for example, determine the critical points of the spurious minima described by Safran and Shamir (2018) for $6 \le k \le 20$. These critical points have isotropy (conjugate to) the diagonal subgroup $\Delta S_{k-1}\subset \Delta S_k$ of $\Gamma$. It is shown that critical points of this family can be expressed as an infinite series in $1/\sqrt{k}$ (for large enough $k$) and, as an application, the critical values decay like $a k^{-1}$, where $a \approx 0.3$. Other non-trivial families of critical points are also described with isotropy conjugate to $\Delta S_{k-1}, \Delta S_k$ and $\Delta (S_2\times S_{k-2})$ (the latter giving spurious minima for $k\ge 9$). The methods used depend on symmetry breaking, bifurcation, and algebraic geometry, notably Artin's implicit function theorem, and are applicable to other families of critical points that occur in this network.
Spurious Local Minima of Shallow ReLU Networks Conform with the Symmetry of the Target Model
Dec 26, 2019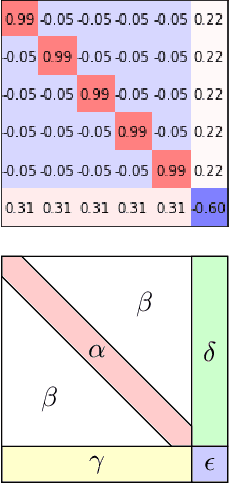
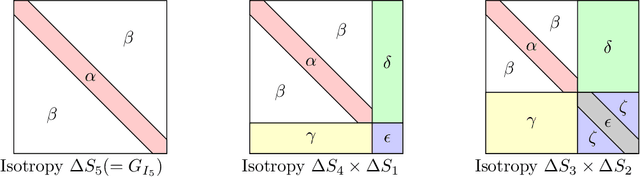

We consider the optimization problem associated with fitting two-layer ReLU networks with respect to the squared loss, where labels are assumed to be generated by a target network. Focusing first on standard Gaussian inputs, we show that the structure of spurious local minima detected by stochastic gradient descent (SGD) is, in a well-defined sense, the \emph{least loss of symmetry} with respect to the target weights. A closer look at the analysis indicates then that this principle of least symmetry breaking may apply to a broader range of settings. Motivated by this, we conduct a series of experiments which corroborate this hypothesis for different classes of non-isotropic non-product distributions, smooth activation functions and networks with a few layers.