 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLookupFFN: Making Transformers Compute-lite for CPU inference
Mar 12, 2024While GPU clusters are the de facto choice for training large deep neural network (DNN) models today, several reasons including ease of workflow, security and cost have led to efforts investigating whether CPUs may be viable for inference in routine use in many sectors of the industry. But the imbalance between the compute capabilities of GPUs and CPUs is huge. Motivated by these considerations, we study a module which is a workhorse within modern DNN architectures, GEMM based Feed Forward Networks (FFNs), and assess the extent to which it can be made compute- (or FLOP-) lite. Specifically, we propose an alternative formulation (we call it LookupFFN) to GEMM based FFNs inspired by the recent studies of using Locality Sensitive Hashing (LSH) to approximate FFNs. Our formulation recasts most essential operations as a memory look-up, leveraging the trade-off between the two resources on any platform: compute and memory (since CPUs offer it in abundance). For RoBERTa language model pretraining, our formulation achieves similar performance compared to GEMM based FFNs, while dramatically reducing the required FLOP. Our development is complemented with a detailed hardware profiling of strategies that will maximize efficiency -- not just on contemporary hardware but on products that will be offered in the near/medium term future. Code is avaiable at \url{https://github.com/mlpen/LookupFFN}.
Deep Action Sequence Learning for Causal Shape Transformation
Nov 08, 2016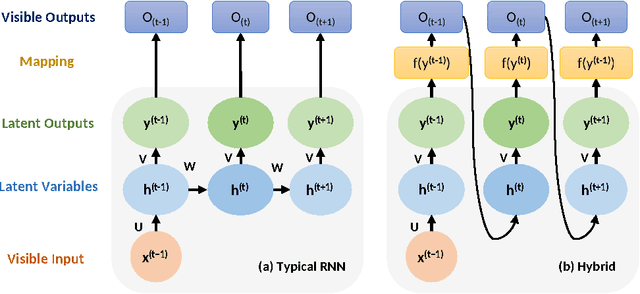
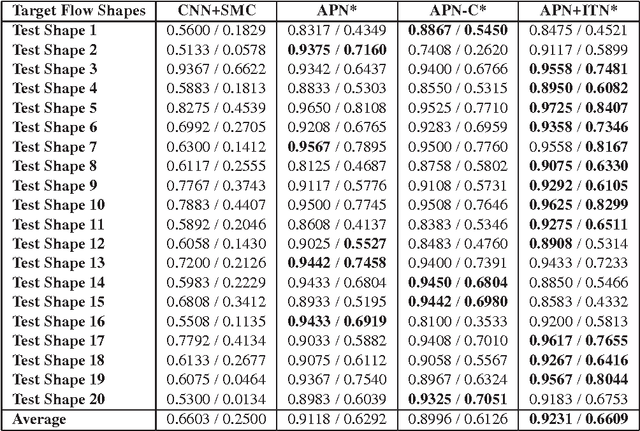
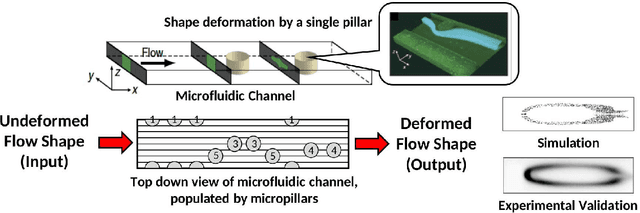
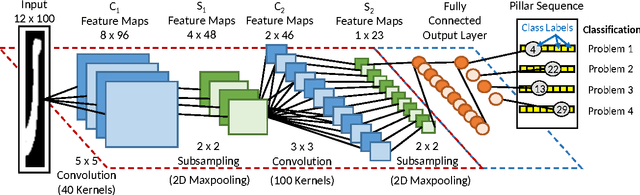
Deep learning became the method of choice in recent year for solving a wide variety of predictive analytics tasks. For sequence prediction, recurrent neural networks (RNN) are often the go-to architecture for exploiting sequential information where the output is dependent on previous computation. However, the dependencies of the computation lie in the latent domain which may not be suitable for certain applications involving the prediction of a step-wise transformation sequence that is dependent on the previous computation only in the visible domain. We propose that a hybrid architecture of convolution neural networks (CNN) and stacked autoencoders (SAE) is sufficient to learn a sequence of actions that nonlinearly transforms an input shape or distribution into a target shape or distribution with the same support. While such a framework can be useful in a variety of problems such as robotic path planning, sequential decision-making in games, and identifying material processing pathways to achieve desired microstructures, the application of the framework is exemplified by the control of fluid deformations in a microfluidic channel by deliberately placing a sequence of pillars. Learning of a multistep topological transform has significant implications for rapid advances in material science and biomedical applications.