 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDensity-based interpretable hypercube region partitioning for mixed numeric and categorical data
Nov 08, 2021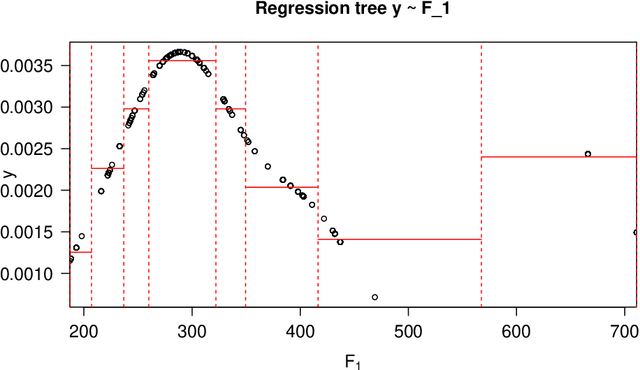
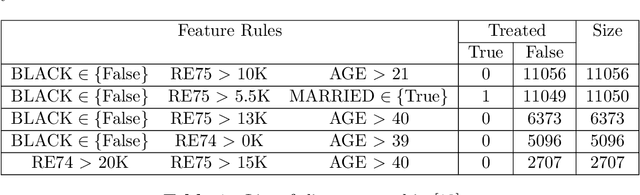
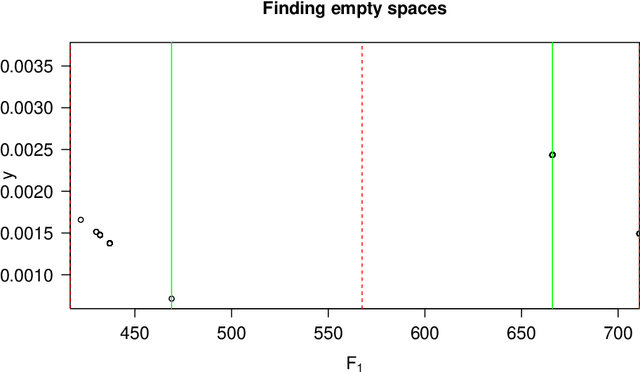

Consider a structured dataset of features, such as $\{\textrm{SEX}, \textrm{INCOME}, \textrm{RACE}, \textrm{EXPERIENCE}\}$. A user may want to know where in the feature space observations are concentrated, and where it is sparse or empty. The existence of large sparse or empty regions can provide domain knowledge of soft or hard feature constraints (e.g., what is the typical income range, or that it may be unlikely to have a high income with few years of work experience). Also, these can suggest to the user that machine learning (ML) model predictions for data inputs in sparse or empty regions may be unreliable. An interpretable region is a hyper-rectangle, such as $\{\textrm{RACE} \in\{\textrm{Black}, \textrm{White}\}\}\:\&$ $\{10 \leq \:\textrm{EXPERIENCE} \:\leq 13\}$, containing all observations satisfying the constraints; typically, such regions are defined by a small number of features. Our method constructs an observation density-based partition of the observed feature space in the dataset into such regions. It has a number of advantages over others in that it works on features of mixed type (numeric or categorical) in the original domain, and can separate out empty regions as well. As can be seen from visualizations, the resulting partitions accord with spatial groupings that a human eye might identify; the results should thus extend to higher dimensions. We also show some applications of the partition to other data analysis tasks, such as inferring about ML model error, measuring high-dimensional density variability, and causal inference for treatment effect. Many of these applications are made possible by the hyper-rectangular form of the partition regions.
"Train one, Classify one, Teach one" -- Cross-surgery transfer learning for surgical step recognition
Feb 24, 2021
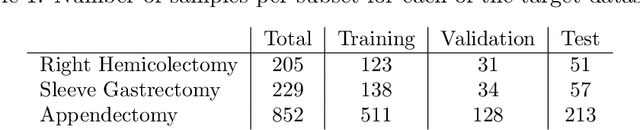

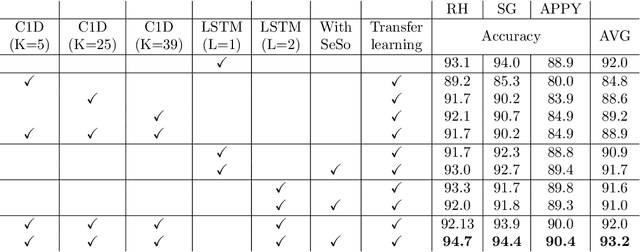
Prior work demonstrated the ability of machine learning to automatically recognize surgical workflow steps from videos. However, these studies focused on only a single type of procedure. In this work, we analyze, for the first time, surgical step recognition on four different laparoscopic surgeries: Cholecystectomy, Right Hemicolectomy, Sleeve Gastrectomy, and Appendectomy. Inspired by the traditional apprenticeship model, in which surgical training is based on the Halstedian method, we paraphrase the "see one, do one, teach one" approach for the surgical intelligence domain as "train one, classify one, teach one". In machine learning, this approach is often referred to as transfer learning. To analyze the impact of transfer learning across different laparoscopic procedures, we explore various time-series architectures and examine their performance on each target domain. We introduce a new architecture, the Time-Series Adaptation Network (TSAN), an architecture optimized for transfer learning of surgical step recognition, and we show how TSAN can be pre-trained using self-supervised learning on a Sequence Sorting task. Such pre-training enables TSAN to learn workflow steps of a new laparoscopic procedure type from only a small number of labeled samples from the target procedure. Our proposed architecture leads to better performance compared to other possible architectures, reaching over 90% accuracy when transferring from laparoscopic Cholecystectomy to the other three procedure types.
Video Transformer Network
Feb 01, 2021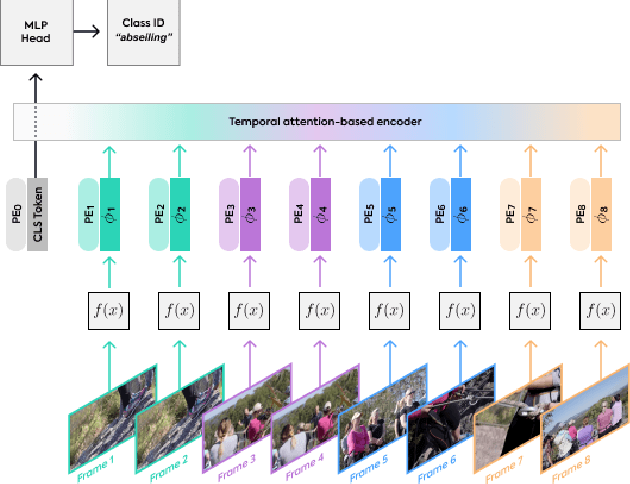


This paper presents VTN, a transformer-based framework for video recognition. Inspired by recent developments in vision transformers, we ditch the standard approach in video action recognition that relies on 3D ConvNets and introduce a method that classifies actions by attending to the entire video sequence information. Our approach is generic and builds on top of any given 2D spatial network. In terms of wall runtime, it trains $16.1\times$ faster and runs $5.1\times$ faster during inference while maintaining competitive accuracy compared to other state-of-the-art methods. It enables whole video analysis, via a single end-to-end pass, while requiring $1.5\times$ fewer GFLOPs. We report competitive results on Kinetics-400 and present an ablation study of VTN properties and the trade-off between accuracy and inference speed. We hope our approach will serve as a new baseline and start a fresh line of research in the video recognition domain. Code and models will be available soon.