 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Transformer Network
Paper and Code
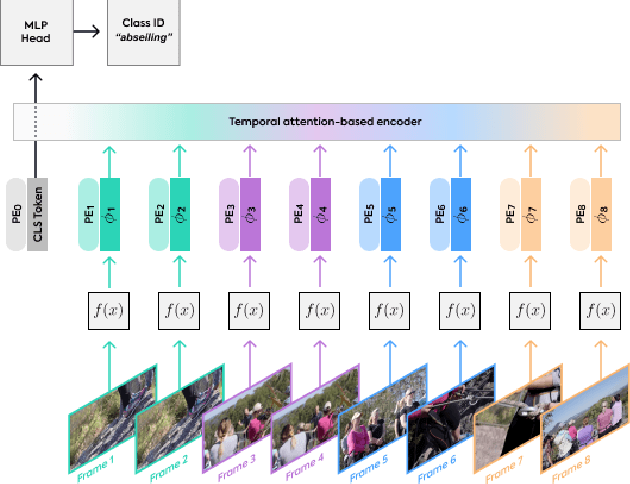


This paper presents VTN, a transformer-based framework for video recognition. Inspired by recent developments in vision transformers, we ditch the standard approach in video action recognition that relies on 3D ConvNets and introduce a method that classifies actions by attending to the entire video sequence information. Our approach is generic and builds on top of any given 2D spatial network. In terms of wall runtime, it trains $16.1\times$ faster and runs $5.1\times$ faster during inference while maintaining competitive accuracy compared to other state-of-the-art methods. It enables whole video analysis, via a single end-to-end pass, while requiring $1.5\times$ fewer GFLOPs. We report competitive results on Kinetics-400 and present an ablation study of VTN properties and the trade-off between accuracy and inference speed. We hope our approach will serve as a new baseline and start a fresh line of research in the video recognition domain. Code and models will be available soon.