 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Data-Driven Exploration of Elevation Cues in HRTFs: An Explainable AI Perspective Across Multiple Datasets
Mar 14, 2025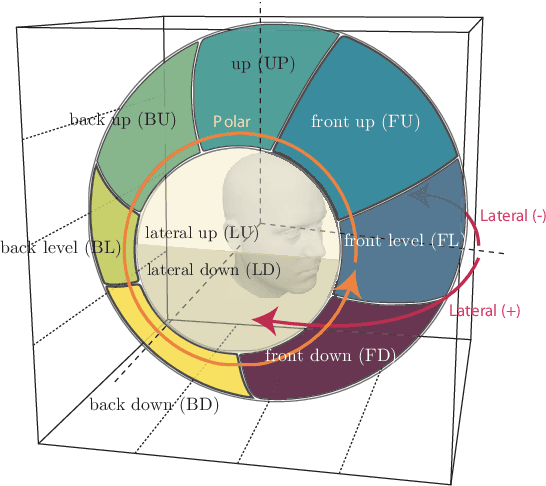
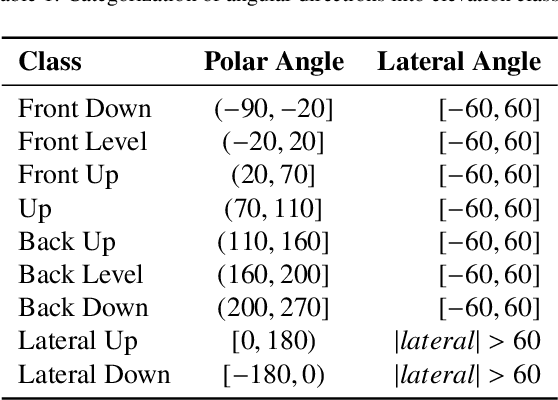
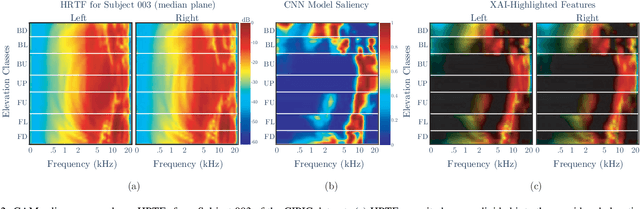
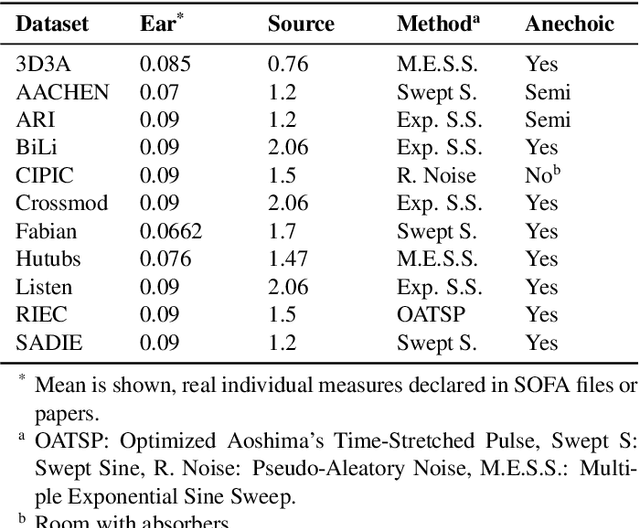
Precise elevation perception in binaural audio remains a challenge, despite extensive research on head-related transfer functions (HRTFs) and spectral cues. While prior studies have advanced our understanding of sound localization cues, the interplay between spectral features and elevation perception is still not fully understood. This paper presents a comprehensive analysis of over 600 subjects from 11 diverse public HRTF datasets, employing a convolutional neural network (CNN) model combined with explainable artificial intelligence (XAI) techniques to investigate elevation cues. In addition to testing various HRTF pre-processing methods, we focus on both within-dataset and inter-dataset generalization and explainability, assessing the model's robustness across different HRTF variations stemming from subjects and measurement setups. By leveraging class activation mapping (CAM) saliency maps, we identify key frequency bands that may contribute to elevation perception, providing deeper insights into the spectral features that drive elevation-specific classification. This study offers new perspectives on HRTF modeling and elevation perception by analyzing diverse datasets and pre-processing techniques, expanding our understanding of these cues across a wide range of conditions.
Acoustic source localization in the spherical harmonics domain exploiting low-rank approximations
Mar 15, 2023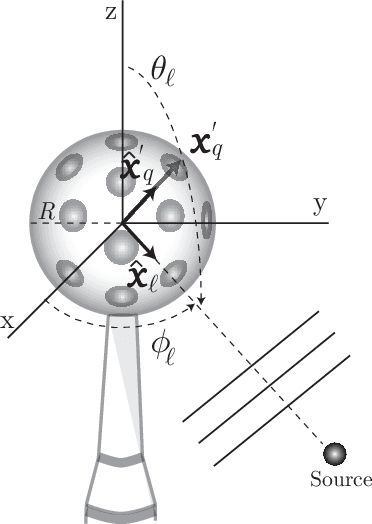
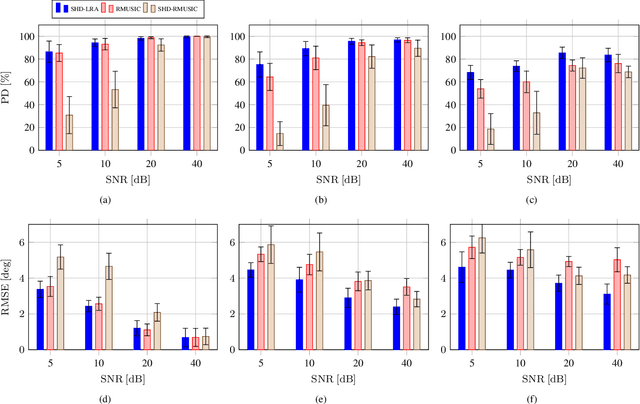
Acoustic signal processing in the spherical harmonics domain (SHD) is an active research area that exploits the signals acquired by higher order microphone arrays. A very important task is that concerning the localization of active sound sources. In this paper, we propose a simple yet effective method to localize prominent acoustic sources in adverse acoustic scenarios. By using a proper normalization and arrangement of the estimated spherical harmonic coefficients, we exploit low-rank approximations to estimate the far field modal directional pattern of the dominant source at each time-frame. The experiments confirm the validity of the proposed approach, with superior performance compared to other recent SHD-based approaches.
* To appear in ICASSP 2023
Task 1A DCASE 2021: Acoustic Scene Classification with mismatch-devices using squeeze-excitation technique and low-complexity constraint
Jul 30, 2021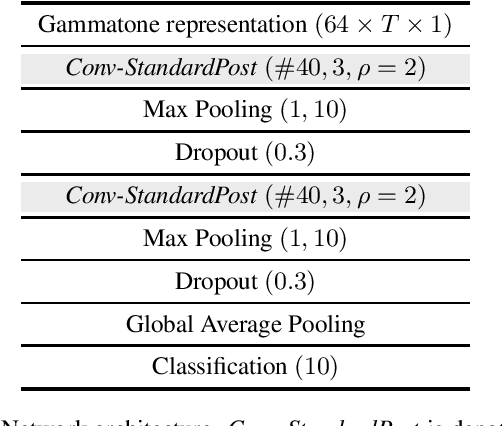

Acoustic scene classification (ASC) is one of the most popular problems in the field of machine listening. The objective of this problem is to classify an audio clip into one of the predefined scenes using only the audio data. This problem has considerably progressed over the years in the different editions of DCASE. It usually has several subtasks that allow to tackle this problem with different approaches. The subtask presented in this report corresponds to a ASC problem that is constrained by the complexity of the model as well as having audio recorded from different devices, known as mismatch devices (real and simulated). The work presented in this report follows the research line carried out by the team in previous years. Specifically, a system based on two steps is proposed: a two-dimensional representation of the audio using the Gamamtone filter bank and a convolutional neural network using squeeze-excitation techniques. The presented system outperforms the baseline by about 17 percentage points.
TASK3 DCASE2021 Challenge: Sound event localization and detection using squeeze-excitation residual CNNs
Jul 30, 2021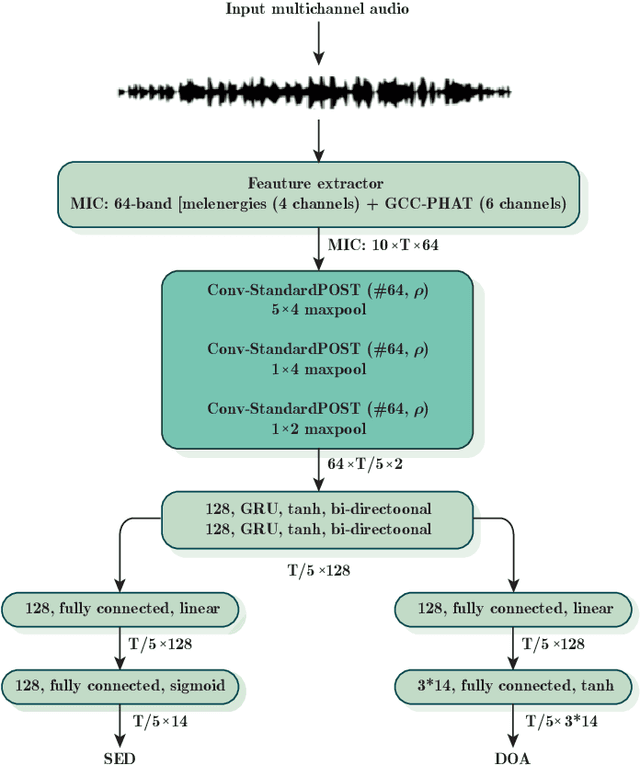
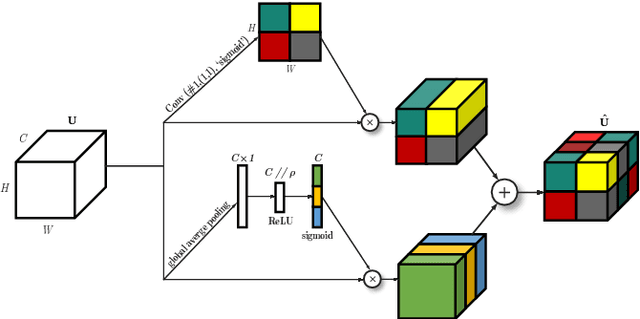
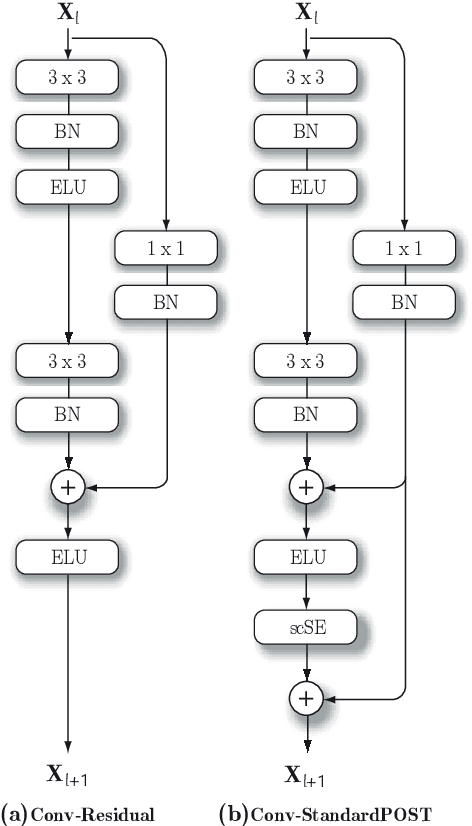

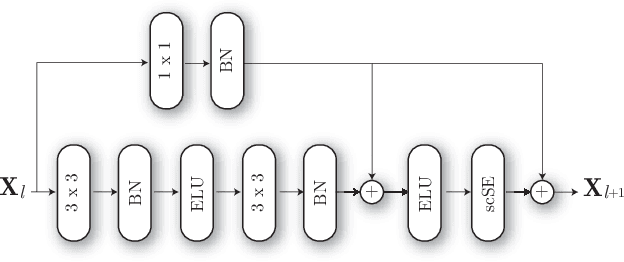
Sound event localisation and detection (SELD) is a problem in the field of automatic listening that aims at the temporal detection and localisation (direction of arrival estimation) of sound events within an audio clip, usually of long duration. Due to the amount of data present in the datasets related to this problem, solutions based on deep learning have positioned themselves at the top of the state of the art. Most solutions are based on 2D representations of the audio (different spectrograms) that are processed by a convolutional-recurrent network. The motivation of this submission is to study the squeeze-excitation technique in the convolutional part of the network and how it improves the performance of the system. This study is based on the one carried out by the same team last year. This year, it has been decided to study how this technique improves each of the datasets (last year only the MIC dataset was studied). This modification shows an improvement in the performance of the system compared to the baseline using MIC dataset.
Squeeze-Excitation Convolutional Recurrent Neural Networks for Audio-Visual Scene Classification
Jul 28, 2021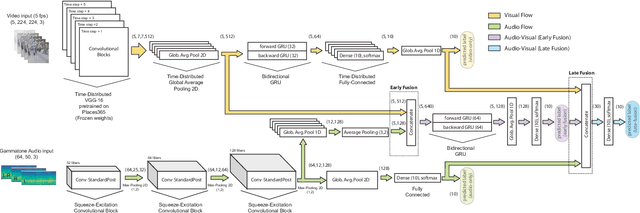


The use of multiple and semantically correlated sources can provide complementary information to each other that may not be evident when working with individual modalities on their own. In this context, multi-modal models can help producing more accurate and robust predictions in machine learning tasks where audio-visual data is available. This paper presents a multi-modal model for automatic scene classification that exploits simultaneously auditory and visual information. The proposed approach makes use of two separate networks which are respectively trained in isolation on audio and visual data, so that each network specializes in a given modality. The visual subnetwork is a pre-trained VGG16 model followed by a bidiretional recurrent layer, while the residual audio subnetwork is based on stacked squeeze-excitation convolutional blocks trained from scratch. After training each subnetwork, the fusion of information from the audio and visual streams is performed at two different stages. The early fusion stage combines features resulting from the last convolutional block of the respective subnetworks at different time steps to feed a bidirectional recurrent structure. The late fusion stage combines the output of the early fusion stage with the independent predictions provided by the two subnetworks, resulting in the final prediction. We evaluate the method using the recently published TAU Audio-Visual Urban Scenes 2021, which contains synchronized audio and video recordings from 12 European cities in 10 different scene classes. The proposed model has been shown to provide an excellent trade-off between prediction performance (86.5%) and system complexity (15M parameters) in the evaluation results of the DCASE 2021 Challenge.
Fast Channel Estimation in the Transformed Spatial Domain for Analog Millimeter Wave Systems
Apr 05, 2021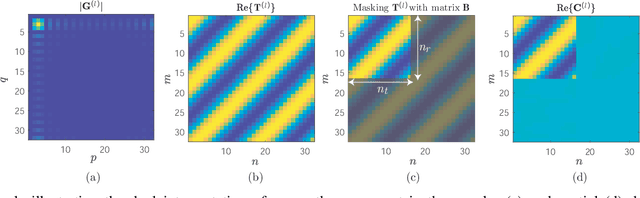
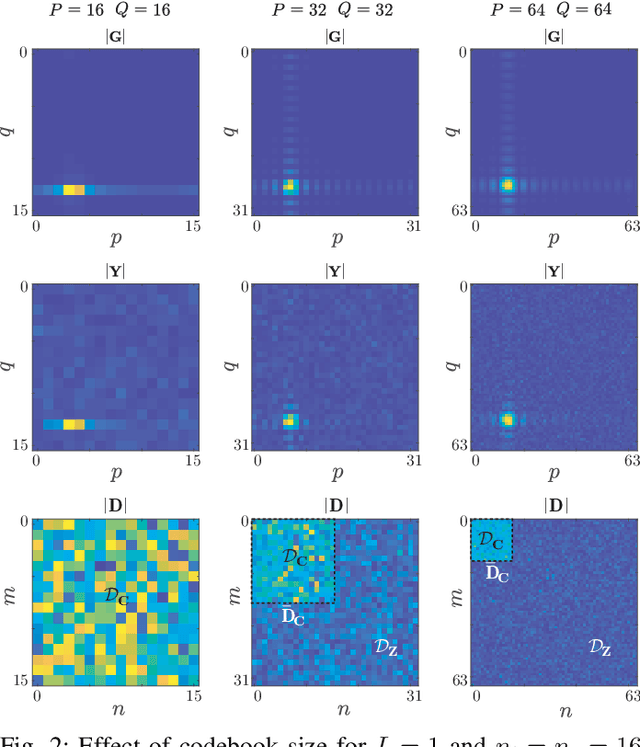
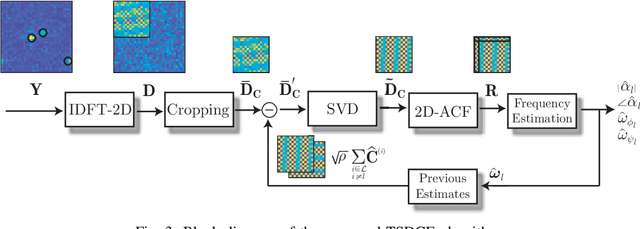
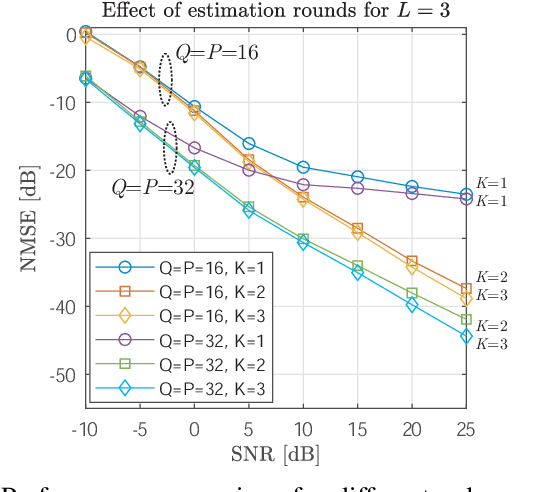
Fast channel estimation in millimeter-wave (mmWave) systems is a fundamental enabler of high-gain beamforming, which boosts coverage and capacity. The channel estimation stage typically involves an initial beam training process where a subset of the possible beam directions at the transmitter and receiver is scanned along a predefined codebook. Unfortunately, the high number of transmit and receive antennas deployed in mmWave systems increase the complexity of the beam selection and channel estimation tasks. In this work, we tackle the channel estimation problem in analog systems from a different perspective than used by previous works. In particular, we propose to move the channel estimation problem from the angular domain into the transformed spatial domain, in which estimating the angles of arrivals and departures corresponds to estimating the angular frequencies of paths constituting the mmWave channel. The proposed approach, referred to as transformed spatial domain channel estimation (TSDCE) algorithm, exhibits robustness to additive white Gaussian noise by combining low-rank approximations and sample autocorrelation functions for each path in the transformed spatial domain. Numerical results evaluate the mean square error of the channel estimation and the direction of arrival estimation capability. TSDCE significantly reduces the first, while exhibiting a remarkably low computational complexity compared with well-known benchmarking schemes.
Listen carefully and tell: an audio captioning system based on residual learning and gammatone audio representation
Jul 08, 2020
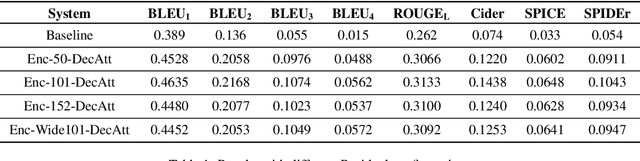


Automated audio captioning is machine listening task whose goal is to describe an audio using free text. An automated audio captioning system has to be implemented as it accepts an audio as input and outputs as textual description, that is, the caption of the signal. This task can be useful in many applications such as automatic content description or machine-to-machine interaction. In this work, an automatic audio captioning based on residual learning on the encoder phase is proposed. The encoder phase is implemented via different Residual Networks configurations. The decoder phase (create the caption) is run using recurrent layers plus attention mechanism. The audio representation chosen has been Gammatone. Results show that the framework proposed in this work surpass the baseline system in challenge results.
Anomalous Sound Detection using unsupervised and semi-supervised autoencoders and gammatone audio representation
Jun 27, 2020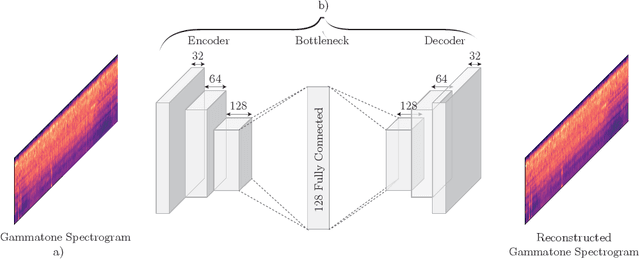
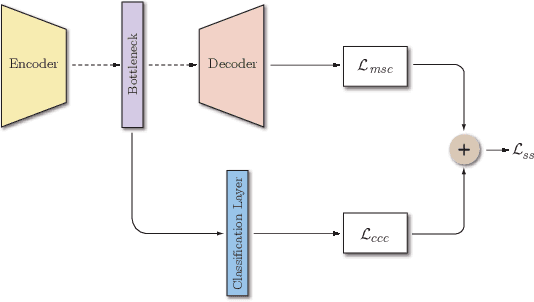
Anomalous sound detection (ASD) is, nowadays, one of the topical subjects in machine listening discipline. Unsupervised detection is attracting a lot of interest due to its immediate applicability in many fields. For example, related to industrial processes, the early detection of malfunctions or damage in machines can mean great savings and an improvement in the efficiency of industrial processes. This problem can be solved with an unsupervised ASD solution since industrial machines will not be damaged simply by having this audio data in the training stage. This paper proposes a novel framework based on convolutional autoencoders (both unsupervised and semi-supervised) and a Gammatone-based representation of the audio. The results obtained by these architectures substantially exceed the results presented as a baseline.
On the performance of different excitation-residual blocks for Acoustic Scene Classification
Mar 20, 2020
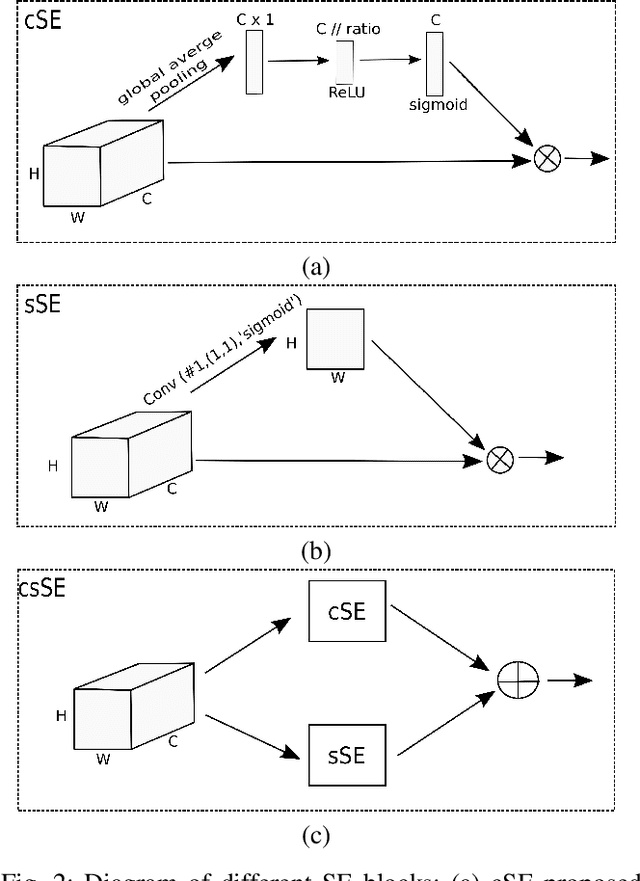
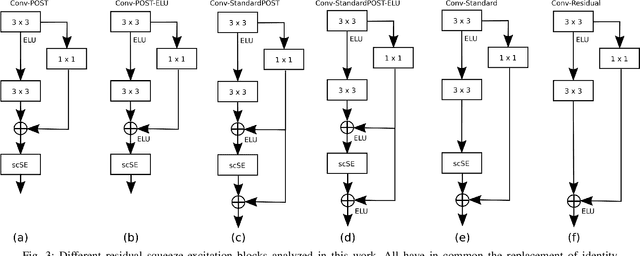
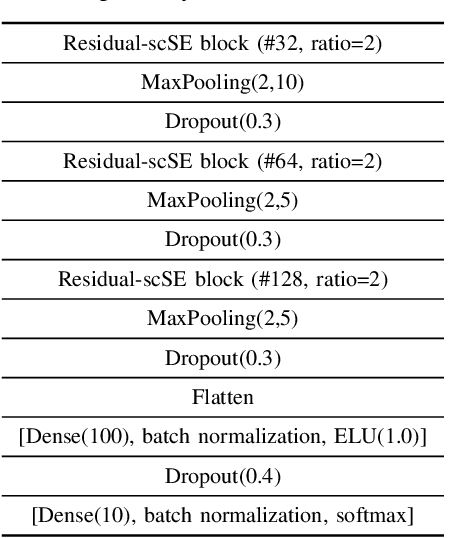
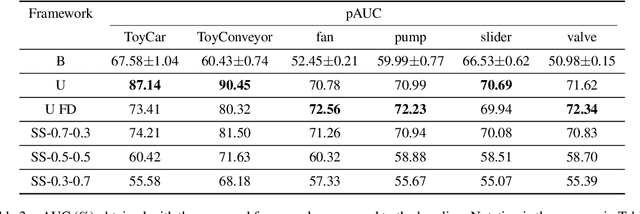
Acoustic Scene Classification (ASC) is a problem related to the field of machine listening whose objective is to classify/tag an audio clip in a predefined label describing a scene location. Interest in this topic has grown so much over the years that an annual international challenge (Dectection and Classification of Acoustic Scenes and Events) is held to propose novel solutions. Solutions to these problems often incorporate different methods such as data augmentation or with an ensemble of various models. Although the main line of research in the state-of-the-art usually implements these methods, considerable improvements and state-of-the-art results can also be achieved only by modifying the architecture of convolutional neural networks (CNNs). In this work we propose two novel squeeze-excitation blocks to improve the accuracy of an ASC framework by modifying the architecture of the residual block in a CNN together with an analysis of several state-of-the-art blocks. The main idea of squeeze-excitation blocks is to learn spatial and channel-wise feature maps independently instead of jointly as standard CNNs do. This is done by some global grouping operators, linear operators and a final calibration between the input of the block and the relationships obtained by that block. The behavior of the block that implements these operators and, therefore, the entire neural network can be modified depending on the input to the block, the residual configurations and the non-linear activations, that is, at what point of the block they are performed. The analysis has been carried out using TAU Urban Acoustic Scenes 2019 dataset presented in DCASE 2019 edition. All configurations discussed in this document exceed baseline proposed by DCASE organization by 13% percentage points. In turn, the novel configurations proposed in this paper exceed the residual configuration proposed in previous works.
An Open-set Recognition and Few-Shot Learning Dataset for Audio Event Classification in Domestic Environments
Mar 18, 2020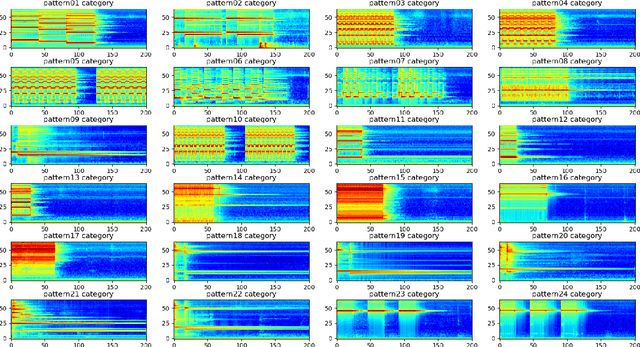
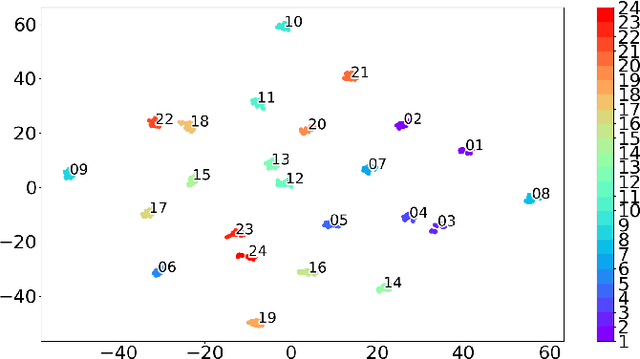

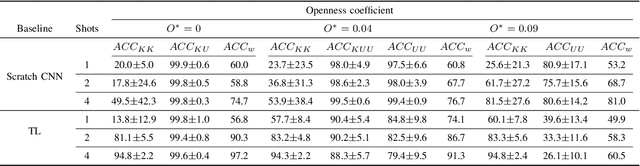
The problem of training a deep neural network with a small set of positive samples is known as few-shot learning (FSL). It is widely known that traditional deep learning (DL) algorithms usually show very good performance when trained with large datasets. However, in many applications, it is not possible to obtain such a high number of samples. In the image domain, typical FSL applications are those related to face recognition. In the audio domain, music fraud or speaker recognition can be clearly benefited from FSL methods. This paper deals with the application of FSL to the detection of specific and intentional acoustic events given by different types of sound alarms, such as door bells or fire alarms, using a limited number of samples. These sounds typically occur in domestic environments where many events corresponding to a wide variety of sound classes take place. Therefore, the detection of such alarms in a practical scenario can be considered an open-set recognition (OSR) problem. To address the lack of a dedicated public dataset for audio FSL, researchers usually make modifications on other available datasets. This paper is aimed at providing the audio recognition community with a carefully annotated dataset for FSL and OSR comprised of 1360 clips from 34 classes divided into pattern sounds and unwanted sounds. To facilitate and promote research in this area, results with two baseline systems (one trained from scratch and another based on transfer learning), are presented.