 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTASK3 DCASE2021 Challenge: Sound event localization and detection using squeeze-excitation residual CNNs
Paper and Code
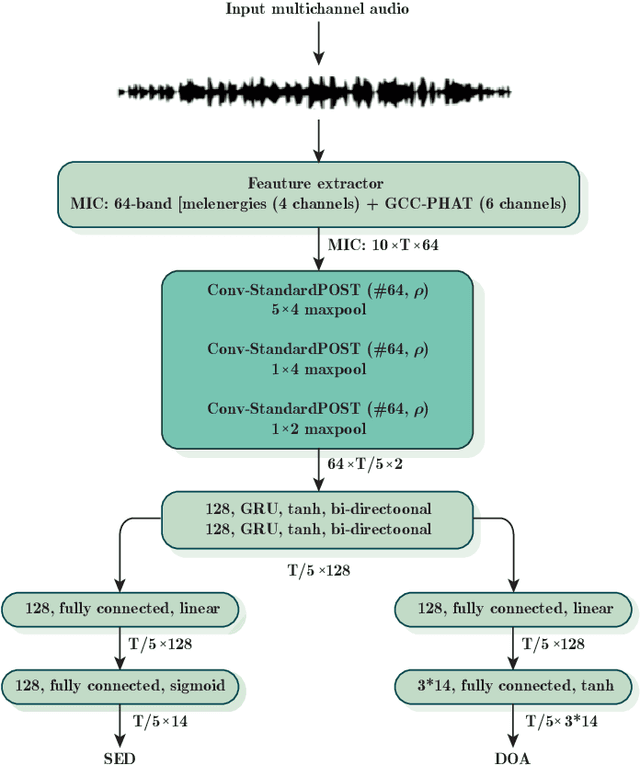
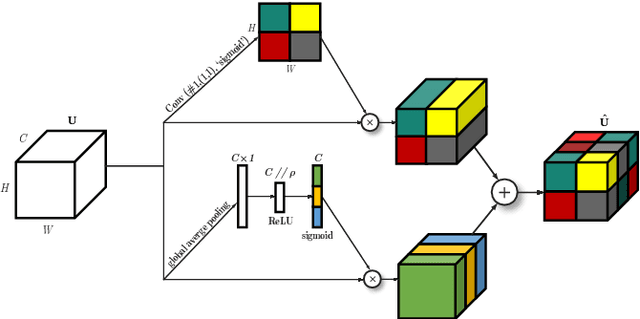
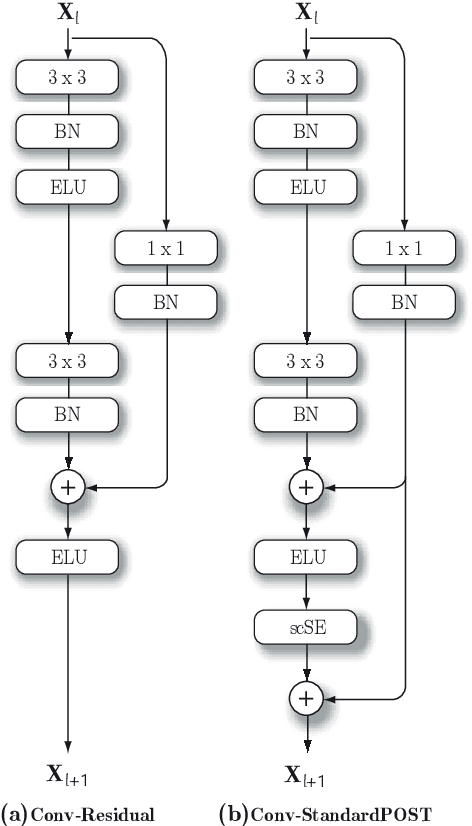

Sound event localisation and detection (SELD) is a problem in the field of automatic listening that aims at the temporal detection and localisation (direction of arrival estimation) of sound events within an audio clip, usually of long duration. Due to the amount of data present in the datasets related to this problem, solutions based on deep learning have positioned themselves at the top of the state of the art. Most solutions are based on 2D representations of the audio (different spectrograms) that are processed by a convolutional-recurrent network. The motivation of this submission is to study the squeeze-excitation technique in the convolutional part of the network and how it improves the performance of the system. This study is based on the one carried out by the same team last year. This year, it has been decided to study how this technique improves each of the datasets (last year only the MIC dataset was studied). This modification shows an improvement in the performance of the system compared to the baseline using MIC dataset.