 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analysis of Multi-Agent Reinforcement Learning for Decentralized Inventory Control Systems
Jul 21, 2023



Most solutions to the inventory management problem assume a centralization of information that is incompatible with organisational constraints in real supply chain networks. The inventory management problem is a well-known planning problem in operations research, concerned with finding the optimal re-order policy for nodes in a supply chain. While many centralized solutions to the problem exist, they are not applicable to real-world supply chains made up of independent entities. The problem can however be naturally decomposed into sub-problems, each associated with an independent entity, turning it into a multi-agent system. Therefore, a decentralized data-driven solution to inventory management problems using multi-agent reinforcement learning is proposed where each entity is controlled by an agent. Three multi-agent variations of the proximal policy optimization algorithm are investigated through simulations of different supply chain networks and levels of uncertainty. The centralized training decentralized execution framework is deployed, which relies on offline centralization during simulation-based policy identification, but enables decentralization when the policies are deployed online to the real system. Results show that using multi-agent proximal policy optimization with a centralized critic leads to performance very close to that of a centralized data-driven solution and outperforms a distributed model-based solution in most cases while respecting the information constraints of the system.
Distributional Reinforcement Learning for Scheduling of Chemical Production Processes
Mar 09, 2022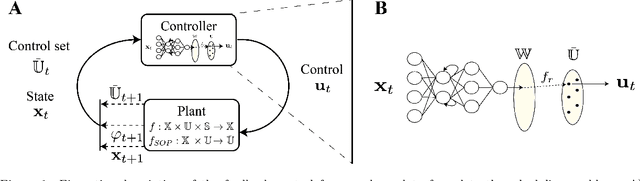
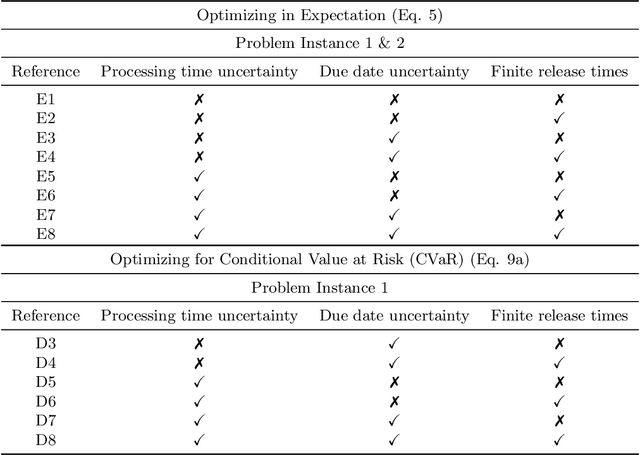
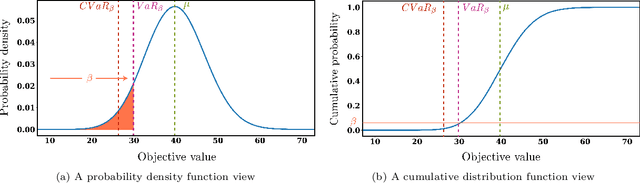
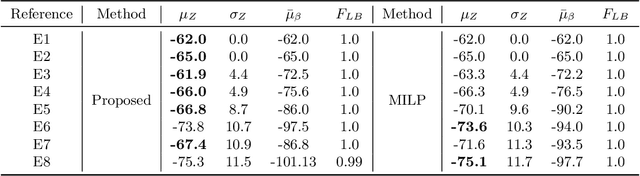
Reinforcement Learning (RL) has recently received significant attention from the process systems engineering and control communities. Recent works have investigated the application of RL to identify optimal scheduling decision in the presence of uncertainty. In this work, we present a RL methodology tailored to efficiently address production scheduling problems in the presence of uncertainty. We consider commonly imposed restrictions on these problems such as precedence and disjunctive constraints which are not naturally considered by RL in other contexts. Additionally, this work naturally enables the optimization of risk-sensitive formulations such as the conditional value-at-risk (CVaR), which are essential in realistic scheduling processes. The proposed strategy is investigated thoroughly in a parallel batch production environment, and benchmarked against mixed integer linear programming (MILP) strategies. We show that the policy identified by our approach is able to account for plant uncertainties in online decision-making, with expected performance comparable to existing MILP methods. Additionally, the framework gains the benefits of optimizing for risk-sensitive measures, and identifies online decisions orders of magnitude faster than the most efficient optimization approaches. This promises to mitigate practical issues and ease in handling realizations of process uncertainty in the paradigm of online production scheduling.
Safe Chance Constrained Reinforcement Learning for Batch Process Control
Apr 23, 2021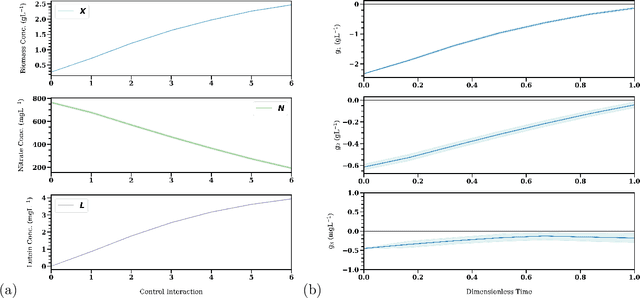


Reinforcement Learning (RL) controllers have generated excitement within the control community. The primary advantage of RL controllers relative to existing methods is their ability to optimize uncertain systems independently of explicit assumption of process uncertainty. Recent focus on engineering applications has been directed towards the development of safe RL controllers. Previous works have proposed approaches to account for constraint satisfaction through constraint tightening from the domain of stochastic model predictive control. Here, we extend these approaches to account for plant-model mismatch. Specifically, we propose a data-driven approach that utilizes Gaussian processes for the offline simulation model and use the associated posterior uncertainty prediction to account for joint chance constraints and plant-model mismatch. The method is benchmarked against nonlinear model predictive control via case studies. The results demonstrate the ability of the methodology to account for process uncertainty, enabling satisfaction of joint chance constraints even in the presence of plant-model mismatch.
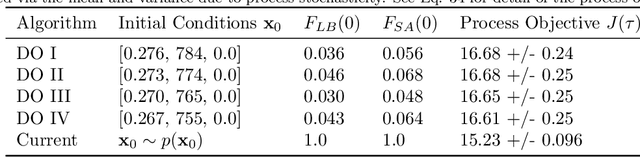
Constrained Model-Free Reinforcement Learning for Process Optimization
Nov 16, 2020

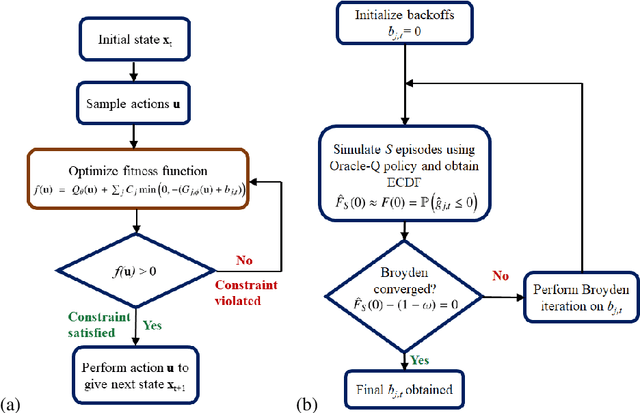

Reinforcement learning (RL) is a control approach that can handle nonlinear stochastic optimal control problems. However, despite the promise exhibited, RL has yet to see marked translation to industrial practice primarily due to its inability to satisfy state constraints. In this work we aim to address this challenge. We propose an 'oracle'-assisted constrained Q-learning algorithm that guarantees the satisfaction of joint chance constraints with a high probability, which is crucial for safety critical tasks. To achieve this, constraint tightening (backoffs) are introduced and adjusted using Broyden's method, hence making them self-tuned. This results in a general methodology that can be imbued into approximate dynamic programming-based algorithms to ensure constraint satisfaction with high probability. Finally, we present case studies that analyze the performance of the proposed approach and compare this algorithm with model predictive control (MPC). The favorable performance of this algorithm signifies a step toward the incorporation of RL into real world optimization and control of engineering systems, where constraints are essential in ensuring safety.