 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning for Individual Heterogeneity
Oct 28, 2020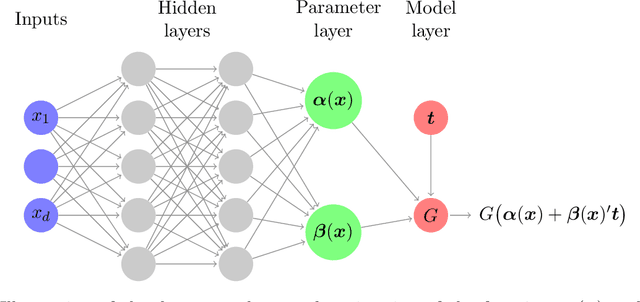
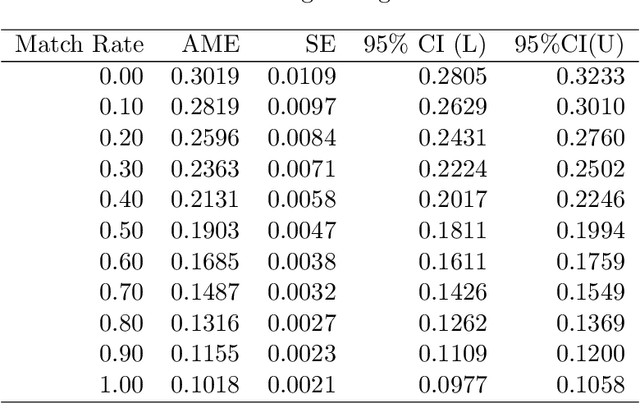
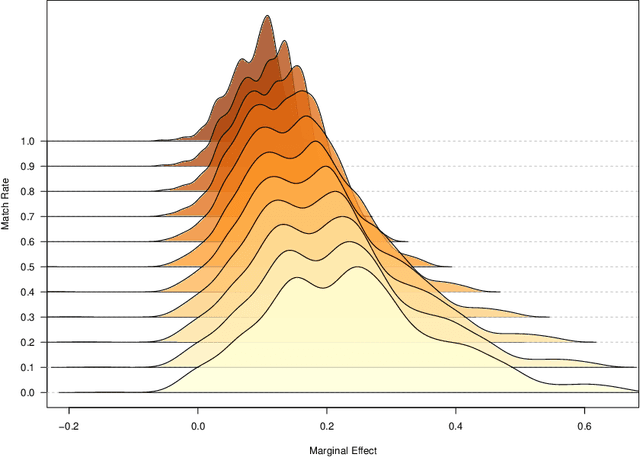
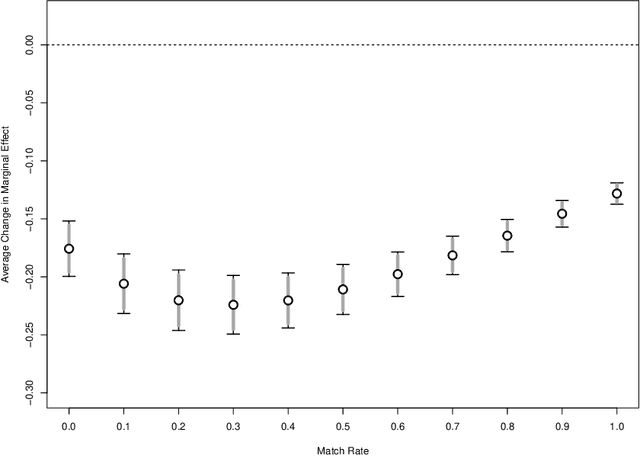
We propose a methodology for effectively modeling individual heterogeneity using deep learning while still retaining the interpretability and economic discipline of classical models. We pair a transparent, interpretable modeling structure with rich data environments and machine learning methods to estimate heterogeneous parameters based on potentially high dimensional or complex observable characteristics. Our framework is widely-applicable, covering numerous settings of economic interest. We recover, as special cases, well-known examples such as average treatment effects and parametric components of partially linear models. However, we also seamlessly deliver new results for diverse examples such as price elasticities, willingness-to-pay, and surplus measures in choice models, average marginal and partial effects of continuous treatment variables, fractional outcome models, count data, heterogeneous production function components, and more. Deep neural networks are well-suited to structured modeling of heterogeneity: we show how the network architecture can be designed to match the global structure of the economic model, giving novel methodology for deep learning as well as, more formally, improved rates of convergence. Our results on deep learning have consequences for other structured modeling environments and applications, such as for additive models. Our inference results are based on an influence function we derive, which we show to be flexible enough to to encompass all settings with a single, unified calculation, removing any requirement for case-by-case derivations. The usefulness of the methodology in economics is shown in two empirical applications: the response of 410(k) participation rates to firm matching and the impact of prices on subscription choices for an online service. Extensions to instrumental variables and multinomial choices are shown.
On Binscatter
Feb 25, 2019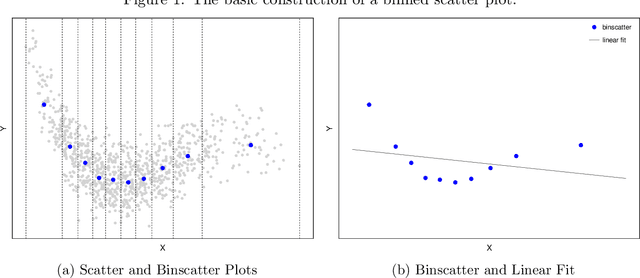
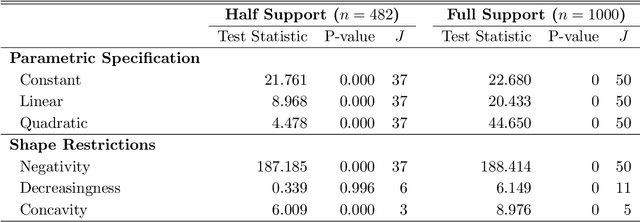
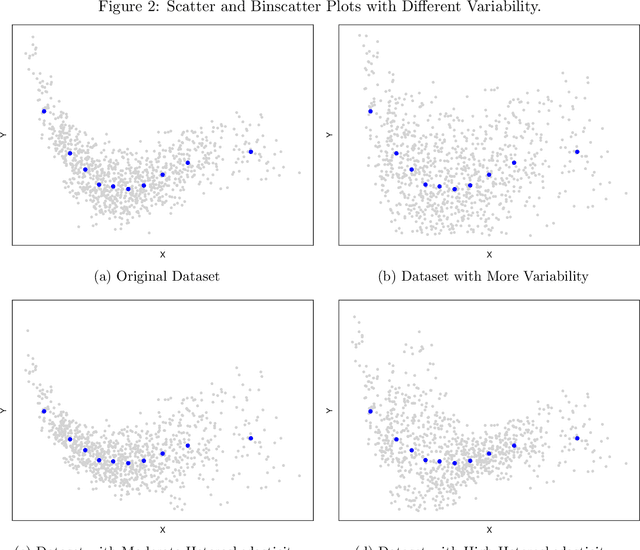
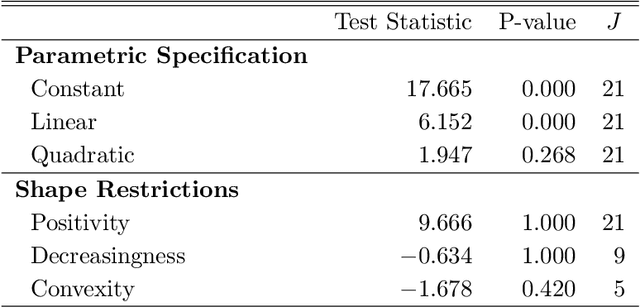
Binscatter is very popular in applied microeconomics. It provides a flexible, yet parsimonious way of visualizing and summarizing large data sets in regression settings, and it is often used for informal evaluation of substantive hypotheses such as linearity or monotonicity of the regression function. This paper presents a foundational, thorough analysis of binscatter: we give an array of theoretical and practical results that aid both in understanding current practices (i.e., their validity or lack thereof) and in offering theory-based guidance for future applications. Our main results include principled number of bins selection, confidence intervals and bands, hypothesis tests for parametric and shape restrictions of the regression function, and several other new methods, applicable to canonical binscatter as well as higher-order polynomial, covariate-adjusted and smoothness-restricted extensions thereof. In particular, we highlight important methodological problems related to covariate adjustment methods used in current practice. We also discuss extensions to clustered data. Our results are illustrated with simulated and real data throughout. Companion general-purpose software packages for \texttt{Stata} and \texttt{R} are provided. Finally, from a technical perspective, new theoretical results for partitioning-based series estimation are obtained that may be of independent interest.
Deep Neural Networks for Estimation and Inference: Application to Causal Effects and Other Semiparametric Estimands
Sep 26, 2018


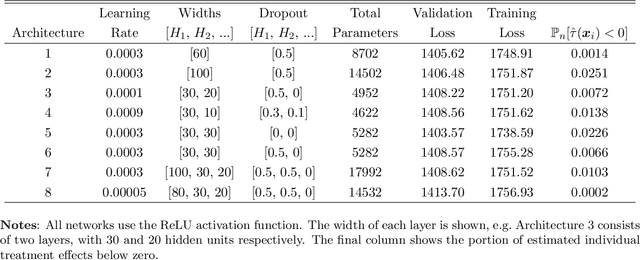
We study deep neural networks and their use in semiparametric inference. We provide new rates of convergence for deep feedforward neural nets and, because our rates are sufficiently fast (in some cases minimax optimal), prove that semiparametric inference is valid using deep nets for first-step estimation. Our estimation rates and semiparametric inference results are the first in the literature to handle the current standard architecture: fully connected feedforward neural networks (multi-layer perceptrons), with the now-default rectified linear unit (ReLU) activation function and a depth explicitly diverging with the sample size. We discuss other architectures as well, including fixed-width, very deep networks. We establish nonasymptotic bounds for these deep ReLU nets, for both least squares and logistic loses in nonparametric regression. We then apply our theory to develop semiparametric inference, focusing on treatment effects and expected profits for concreteness, and demonstrate their effectiveness with an empirical application to direct mail marketing. Inference in many other semiparametric contexts can be readily obtained.