 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSignalMC-MED: A Multimodal Benchmark for Evaluating Biosignal Foundation Models on Single-Lead ECG and PPG
Mar 10, 2026Recent biosignal foundation models (FMs) have demonstrated promising performance across diverse clinical prediction tasks, yet systematic evaluation on long-duration multimodal data remains limited. We introduce SignalMC-MED, a benchmark for evaluating biosignal FMs on synchronized single-lead electrocardiogram (ECG) and photoplethysmogram (PPG) data. Derived from the MC-MED dataset, SignalMC-MED comprises 22,256 visits with 10-minute overlapping ECG and PPG signals, and includes 20 clinically relevant tasks spanning prediction of demographics, emergency department disposition, laboratory value regression, and detection of prior ICD-10 diagnoses. Using this benchmark, we perform a systematic evaluation of representative time-series and biosignal FMs across ECG-only, PPG-only, and ECG + PPG settings. We find that domain-specific biosignal FMs consistently outperform general time-series models, and that multimodal ECG + PPG fusion yields robust improvements over unimodal inputs. Moreover, using the full 10-minute signal consistently outperforms shorter segments, and larger model variants do not reliably outperform smaller ones. Hand-crafted ECG domain features provide a strong baseline and offer complementary value when combined with learned FM representations. Together, these results establish SignalMC-MED as a standardized benchmark and provide practical guidance for evaluating and deploying biosignal FMs.
On the Properties of Adversarially-Trained CNNs
Mar 17, 2022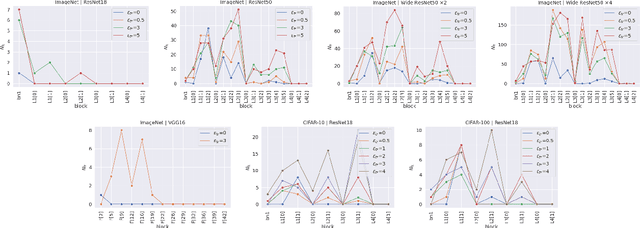
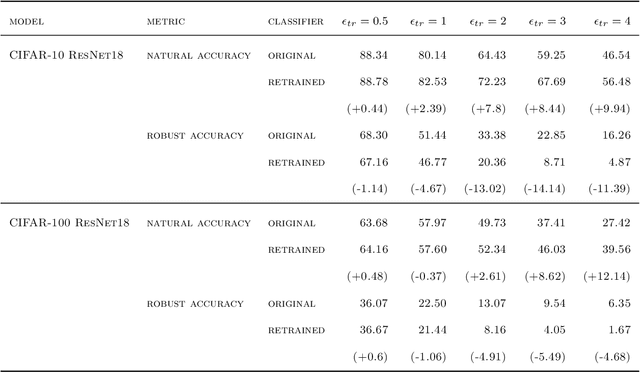
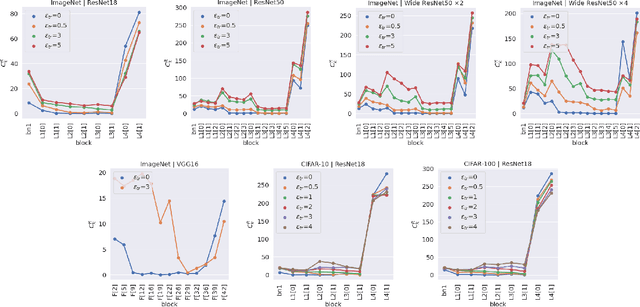

Adversarial Training has proved to be an effective training paradigm to enforce robustness against adversarial examples in modern neural network architectures. Despite many efforts, explanations of the foundational principles underpinning the effectiveness of Adversarial Training are limited and far from being widely accepted by the Deep Learning community. In this paper, we describe surprising properties of adversarially-trained models, shedding light on mechanisms through which robustness against adversarial attacks is implemented. Moreover, we highlight limitations and failure modes affecting these models that were not discussed by prior works. We conduct extensive analyses on a wide range of architectures and datasets, performing a deep comparison between robust and natural models.
AcME -- Accelerated Model-agnostic Explanations: Fast Whitening of the Machine-Learning Black Box
Dec 23, 2021In the context of human-in-the-loop Machine Learning applications, like Decision Support Systems, interpretability approaches should provide actionable insights without making the users wait. In this paper, we propose Accelerated Model-agnostic Explanations (AcME), an interpretability approach that quickly provides feature importance scores both at the global and the local level. AcME can be applied a posteriori to each regression or classification model. Not only does AcME compute feature ranking, but it also provides a what-if analysis tool to assess how changes in features values would affect model predictions. We evaluated the proposed approach on synthetic and real-world datasets, also in comparison with SHapley Additive exPlanations (SHAP), the approach we drew inspiration from, which is currently one of the state-of-the-art model-agnostic interpretability approaches. We achieved comparable results in terms of quality of produced explanations while reducing dramatically the computational time and providing consistent visualization for global and local interpretations. To foster research in this field, and for the sake of reproducibility, we also provide a repository with the code used for the experiments.
Improving Robustness with Image Filtering
Dec 21, 2021
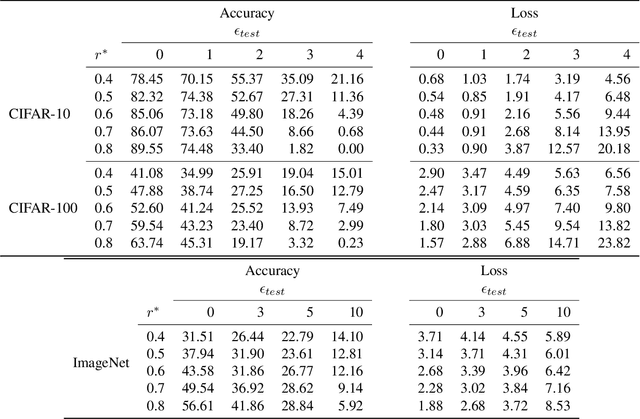
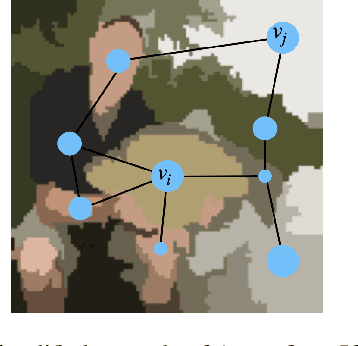

Adversarial robustness is one of the most challenging problems in Deep Learning and Computer Vision research. All the state-of-the-art techniques require a time-consuming procedure that creates cleverly perturbed images. Due to its cost, many solutions have been proposed to avoid Adversarial Training. However, all these attempts proved ineffective as the attacker manages to exploit spurious correlations among pixels to trigger brittle features implicitly learned by the model. This paper first introduces a new image filtering scheme called Image-Graph Extractor (IGE) that extracts the fundamental nodes of an image and their connections through a graph structure. By leveraging the IGE representation, we build a new defense method, Filtering As a Defense, that does not allow the attacker to entangle pixels to create malicious patterns. Moreover, we show that data augmentation with filtered images effectively improves the model's robustness to data corruption. We validate our techniques on CIFAR-10, CIFAR-100, and ImageNet.
Interpretable Anomaly Detection with DIFFI: Depth-based Feature Importance for the Isolation Forest
Jul 21, 2020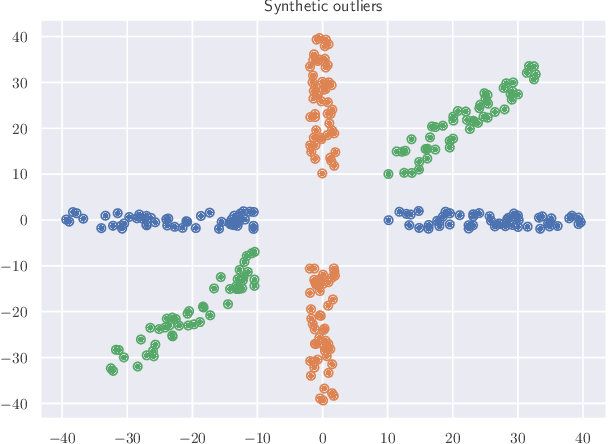
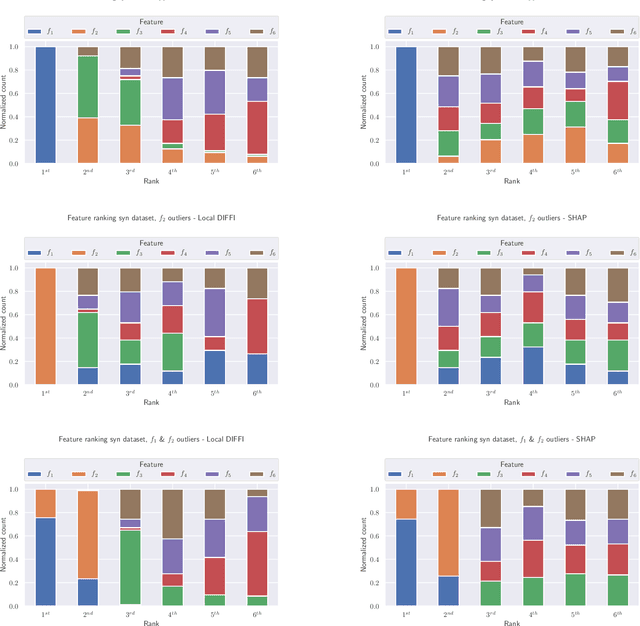
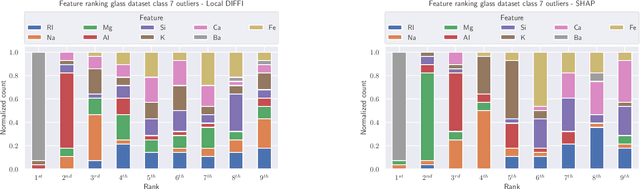
Anomaly Detection is one of the most important tasks in unsupervised learning as it aims at detecting anomalous behaviours w.r.t. historical data; in particular, multivariate Anomaly Detection has an important role in many applications thanks to the capability of summarizing the status of a complex system or observed phenomenon with a single indicator (typically called `Anomaly Score') and thanks to the unsupervised nature of the task that does not require human tagging. The Isolation Forest is one of the most commonly adopted algorithms in the field of Anomaly Detection, due to its proven effectiveness and low computational complexity. A major problem affecting Isolation Forest is represented by the lack of interpretability, as it is not possible to grasp the logic behind the model predictions. In this paper we propose effective, yet computationally inexpensive, methods to define feature importance scores at both global and local level for the Isolation Forest. Moreover, we define a procedure to perform unsupervised feature selection for Anomaly Detection problems based on our interpretability method. We provide an extensive analysis of the proposed approaches, including comparisons against state-of-the-art interpretability techniques. We assess the performance on several synthetic and real-world datasets and make the code publicly available to enhance reproducibility and foster research in the field.