 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Anomaly Detection with DIFFI: Depth-based Feature Importance for the Isolation Forest
Paper and Code
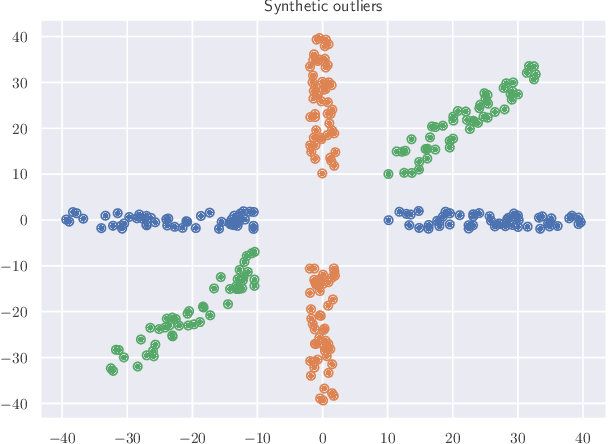
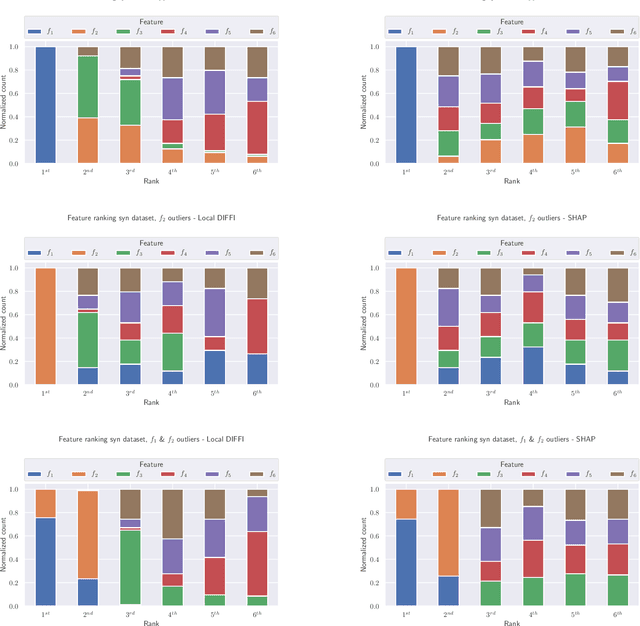
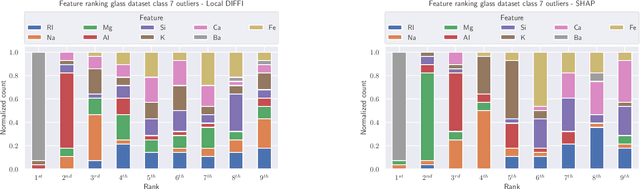
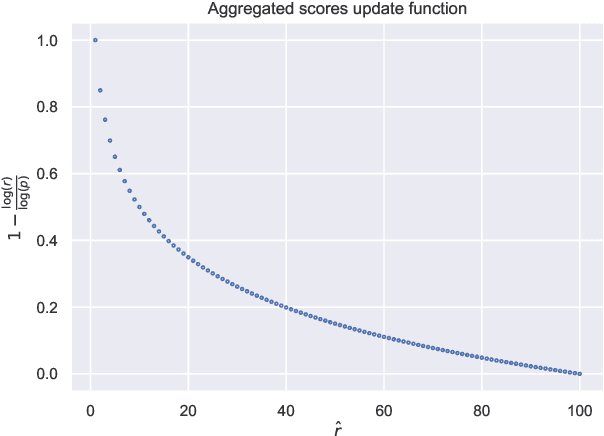
Anomaly Detection is one of the most important tasks in unsupervised learning as it aims at detecting anomalous behaviours w.r.t. historical data; in particular, multivariate Anomaly Detection has an important role in many applications thanks to the capability of summarizing the status of a complex system or observed phenomenon with a single indicator (typically called `Anomaly Score') and thanks to the unsupervised nature of the task that does not require human tagging. The Isolation Forest is one of the most commonly adopted algorithms in the field of Anomaly Detection, due to its proven effectiveness and low computational complexity. A major problem affecting Isolation Forest is represented by the lack of interpretability, as it is not possible to grasp the logic behind the model predictions. In this paper we propose effective, yet computationally inexpensive, methods to define feature importance scores at both global and local level for the Isolation Forest. Moreover, we define a procedure to perform unsupervised feature selection for Anomaly Detection problems based on our interpretability method. We provide an extensive analysis of the proposed approaches, including comparisons against state-of-the-art interpretability techniques. We assess the performance on several synthetic and real-world datasets and make the code publicly available to enhance reproducibility and foster research in the field.